





Bon ben Linux m'aime vraiment pas...
Pas moyen d'installer PostgreSQL 12
Deux articles que je suis et les deux arrivent au même résultat...
-- Edit : bon, SQL Server ça passe
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter

Bon ben Linux m'aime vraiment pas...
Pas moyen d'installer PostgreSQL 12
Deux articles que je suis et les deux arrivent au même résultat...
-- Edit : bon, SQL Server ça passe
On ne jouit bien que de ce quon partage.








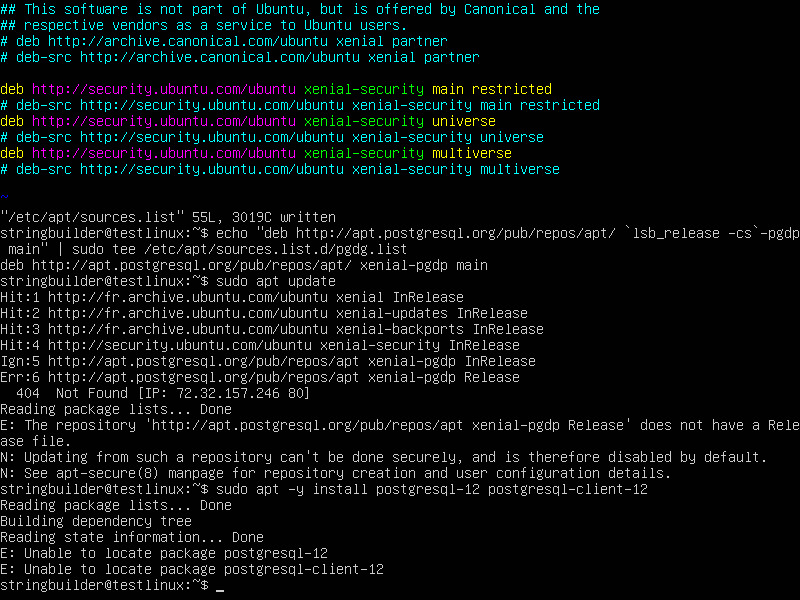
Une typo, pgdg pas pgdp (P.S. et tu ne veux probablement que la version 64 bit) :Envoyé par StringBuilder

Code : Sélectionner tout - Visualiser dans une fenêtre à part echo "deb [arch=amd64] http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main"
Empreinte PGP - Je suis les règles de Crocker.
depesz
Une discussion avec RhodiumToad sur irc :
Code XML : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
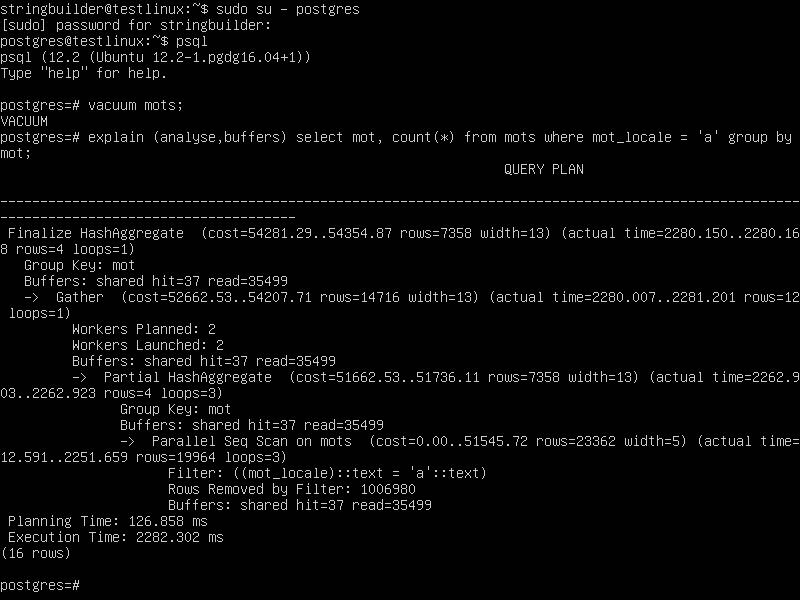
14tidx=# vacuum t_accents; VACUUM tidx=# explain (analyze,buffers) select count(datum) from t_accents where datum='a'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Aggregate (cost=1828.67..1828.68 rows=1 width=8) (actual time=21.654..21.654 rows=1 loops=1) Buffers: shared hit=168 -> Index Only Scan using i on t_accents (cost=0.43..1684.64 rows=57612 width=5) (actual time=0.078..17.797 rows=59892 loops=1) Index Cond: (datum = 'a'::text) Heap Fetches: 0 Buffers: shared hit=168 Planning Time: 0.125 ms Execution Time: 21.676 ms (8 lignes)
Une note importante pour SQLPro : le vocable index seek n'existe pas dans postgres, c'est appelé index scan, et ça ressemble beaucoup plus à l'index seek que l'index scan de sqlserver.
Code XML : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
Empreinte PGP - Je suis les règles de Crocker.
Arf, oui merci, ça va mieux en effet
J'oublie toujours d'enlèver mes palmes quand je tapes des lignes de commande...
Edit :
Pour info, SQL Server sous Linux c'est 237 Mo de téléchargement (le double de PostgreSQL) et 1033 Mo de place disque.
Une paille comparé à Calibre (nécessaire pour avoir simplement ebook-convert) : 537 Mo à télécharger !
On ne jouit bien que de ce quon partage.


dépend comment c'est packagé...
dispo pour de nombreuse distribution...
https://software.opensuse.org/package/calibre
Bon, ça me gonfle, j'arrive pas à importer le fichier CSV dans SQL Server.
J'ai un souci d'encodage des accents. J'arrive pas à trouver d'où ça vient...
Le fichier CSV généré à partir des livres est en UTF-8, mais bulk insert produit des caractères merdiques à la place.
J'ai essayé de "recode" avec différents formats, mais au mieux, c'est pire, au pire, bulk insert plante carrément.
Et évidement, Microsoft n'a pas jugé opportun de porter l'option "codepage" sous Linux... Et pour le mode "RAW", ça prend le codepage "OEM" du système, mais moi je sais pas à quoi ça correspond
On ne jouit bien que de ce quon partage.
Le Objet Eminemment Microsofto-merdique est plus tentant que Original Equipment Manufacturer...
Il y a l'air d'avoir pas mal de monde qui fait tourner sqlserver sur ubu19.10, j'essaierai ce soir en cas.
Empreinte PGP - Je suis les règles de Crocker.
Ouf, c'est bon, j'ai fini par trouver...
En fait, depuis le début j'essayais de faire ce qu'il fallait, mais vu que j'avais rien compris à la doc de recode, forcément je faisais n'importe quoi...
Bref, après avoir converti le fichier utf-8 en unicode, problème résolu !
Voici mes résultats ^^
Si on utilise la collation sous PostgreSQL 12 telle que créée par MaximeCh :
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part CREATE COLLATION ignore_accents (provider = icu, locale = 'fr-u-ks-level1-kc-false', deterministic=false);
Et un index sur la colonne.
Alors SQL Server est... un peu plus de 2,66 fois plus rapide que PostgreSQL, au détail près qu'on parle de 24 ms contre 64 ms ce qui n'est pas forcément très représentatif.
Mode opératoire : (code SQL identique sur les deux systèmes, au détail près de l'import du CSV)
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Grosse différence constatée : le UPDATE pour copier les données cs_as est bien plus rapide avec SQL Server (quelques secondes contre plusieurs dizaines pour PostgreSQL).
Pour le reste, la requête :
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
Dure 24 ms pour SQL Server et 64 ms pour PostgreSQL.
Si je drop l'index et relance la requête, à ce moment SQL Server met 210ms (pour 640 ms de CPU, utilisation des 4 coeurs disponibles) et PostgreSQL met 572ms (pas le détail d'éventuel multi-threading)
Pour le coup, on retrouve de nouveau un temps très proche, avec un ratio similaire de 2,7
Machine de test :
Hôte : Windows 10 Familial / CPU i5 8400@2.8 - mais 3.9 GHz en charge / 16 Go RAM / plusieurs disques dont un disque magnétique SATA 3 de 2 To dédié au test
Outil de virtualisation : Oracle Virtual Box 6.0.16
VM : ubuntu 16.04 amd64 / 4 coeurs / 4 Go de RAM / un disque virtuel de 10 Go avec tout dessus
SQL Server 2019 RTM-CU2 du 3 février 2019 avec licence "developpeur"
PostgreSQL 12 ubuntu 12.2-1.pgpd16.04+1
Il serait intéressant maintenant de voir ce que ça donne avec SQL Server et PostgreSQL sous Windows en testant si la collation fonctionne.
Attention par contre !
En voulant faire quelques tests complémentaires, je suis par contre tombé sur un truc pas cool pour PostgreSQL.
En effet, et pour le coup ça peut vite devenir problématique, le LIKE (ni le ILIKE) ne fonctionne pas sur une collation non déterministe !
Pour le coup, ça peut vite devenir emmerdant dans le cadre d'une migration d'un projet, car c'est pas juste quelques requêtes à écrire pour passer outre cette contrainte.
SQL Server :
PostgreSQL :
Edit : d'après la documentation, rendre la collation déterministe ne résoudra rien, car elle redeviendra sensible à la casse puisqu'une comparaison aura lieu octet par octet.
On ne jouit bien que de ce quon partage.
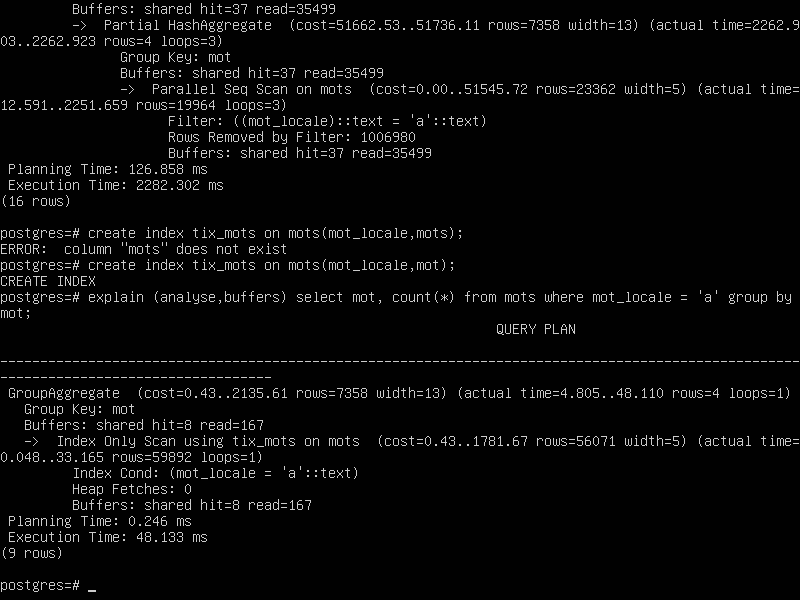
StringBuilder, comme j'ai évoqué quelques postes plus tôt dans perf*2, si tu fais un vacuum de ta table postgres avec index, il y a de grandes chances pour que le planner fasse une recherche dans l'index et que la requête colle voire dépasse le niveau de sqlserver.
Un résultat sans plan de requête a beaucoup moins de valeur.
Empreinte PGP - Je suis les règles de Crocker.
Hmmm, c'est pas franchement mieux : on a un rapport de 1 pour deux.
On va remettre le temps d'exécution du premier select sans index sur le fait que je viens de redémarrer la VM.
Pour les autres, normalement tout est déjà en mémoire.
Avant création de l'index :
Après création de l'index :
Après un nouveau vaccum :
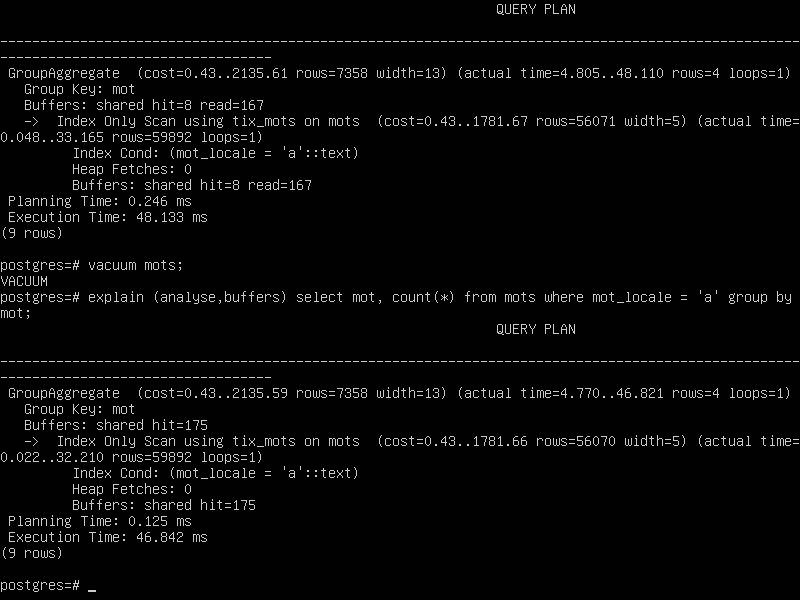
On ne jouit bien que de ce quon partage.







Bref peste ou choléra....
A +
Frédéric Brouard - SQLpro - ARCHITECTE DE DONNÉES - expert SGBDR et langage SQL
Le site sur les SGBD relationnels et le langage SQL: http://sqlpro.developpez.com/
Blog SQL, SQL Server, SGBDR : http://blog.developpez.com/sqlpro
Expert Microsoft SQL Server - M.V.P. (Most valuable Professional) MS Corp.
Entreprise SQL SPOT : modélisation, conseils, audit, optimisation, formation...
* * * * * Expertise SQL Server : http://mssqlserver.fr/ * * * * *
Tu parles de access vs sqlserver ou de windows 10 vs server ?
J'ai installé mssql 2019 version dev sur ubu19.10 Les deux SGBDs avec config de base.
mssql par défaut prend 4Go de RAM, postgres même pas 1. Sur la requête-rengaine count(mot) j'ai mssql : 11ms et postgres 20ms, si on stresse la requête en boucle ça descend à 14ms. Je posterai les résultats demain.
Le problème du like, c'est une critique de mauvaise foi éhontée de la part de SQLPro, pour qui on rédige ici le chapitre qui lui manquait tandis qu'il finit son oeuvre de benchmark dans son coin, et qui pointe le bout de son nez dès que ça sent le souffre pour postgres.
On va bien sûr pas dans la pratique créer une table collationnée ICU... mais faire des index collationnés. Par exemple (déjà dit, et pas le meilleur moyen de le faire) :
Par ailleurs le nom de collation ignore_accent trouvé ici est assez mal choisi, la collation définie est insensible à la casse, aux accents, mais bien plus : c'est une collation ICU. Allez jeter un oeil à la doc ICU, vous entreverrez la puissance / l'usine à gaz du machin.
Code XML : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22tidx=# create table t (id serial, mot text)); CREATE TABLE ... INSERT 0 3080832 tidx=# create index t_i on t(mot collate ignore_accents); CREATE INDEX tidx=# create index t_i2 on t(lower(mot)); CREATE INDEX tidx=# select mot, count(mot) from t where lower(mot) like 'c%œ%' group by mot; mot | count ------------+------- chœur | 82 chœurs | 7 cœli | 1 Cœlina | 28 Cœuilly | 1 cœur | 1661 Cœur | 10 cœurs | 100 contrecœur | 2 Crèvecœur | 16 (10 lignes)
Et oui pas de like sur les collations non déterministes, ça appelle des problèmes très bien évoqués ici qui sont loin d'être triviaux, ce qu'est justement la collation french_ci_ai utilisée sur sqlserver. Tant qu'on y est, postgres est encodée par défaut en UTF-8, sqlserver sur un désuet dérivé de LATIN1, col SQL_Latin1_General_CP1_CI_AS sur ma version 2019. Pour la jouer pédant et coller au cadre, le support d'UTF-8 est arrivé sur sqlserver... l'année dernière!!! ouff!! Sinon pas de soucis pour collationner une base postgres en C bien sûr, et stocker de façon ferme tous ses caractères sur un octet, et dire aux chinois d'aller voir ailleurs. Niveau support des encodages et recherche textuelle, postgres c'est la dernière Tesla, sqlserver c'est une pauvre Polo qui a truqué les tests de pollution!
Bref, la moutarde me monte doucement au nez devant ces abîmes de réflexion, et je vais finir par lui donner jour à ce site de benchmark, pour au moins concurrencer par SEO la tendance dévorante à la désinformation de Frédéric Brouard, (et montrer aux pauvres étudiants de DUT/licences pro, biberonnés de Microsoft comme j'ai pu l'être, la porte vers une informatique un peu moins malheureuse. et sauver le monde).
Empreinte PGP - Je suis les règles de Crocker.
Histoire de donner une réponse plus intelligente que celle de SQLtruc, je vais jouer un peu l'avocat du diable quitte à faire perdre un avantage supposé à Postgres: peux-tu détailler en quoi la collation french_ci_ai est triviale? Peux-tu donner des exemples qui marchent avec la collation ICU et pas avec celle de SQLServer?
Merci beaucoup pour ton travail de bench et de comparaison, qui semble suivre une démarche ouverte, rigoureuse et objective.
Perso, j'utilise des SGBD de temps en temps mais je suis loin d'être un expert donc ce genre de résultats m'intéresse beaucoup et permet de dissiper l'enfumage que certains produisent (involontairement j'espère...).
mssql est prévu pour tourner sur une machine dédiée.
Par conséquent, si tu as 1 To de RAM, même avec une petite base de données, il va finir par s'étaler en mémoire autant que possible.
En effet, ce sera toujours plus rapide de retrouver dans le cache le résultat d'une requête exécutée la semaine dernière que de la ré-exécuter.
C'est un comportement absolument normal, connu et documenté.
En revanche, une version Express ne peut techniquement pas dépasser 1 Go de mémoire cache par instance. Donc SQL Server c'est pas d'emblée 4 Go, c'est d'emblée ce qui est disponible. Pour rappel, l'allocation de mémoire a un coût, surtout quand il faut paginer... et encore pire dans une VM lorsque la mémoire est allouée par l'hôte dynamiquement !
Il est donc parfaitement logique que SQL Server en réserve un maximum dès le démarrage. Pour le coup, c'est PostgreSQL qui se met des bâtons dans les roues à en allouer le minimum.
Le version standard, je ne sais plus. A une époque reculée c'était 4 Go, maintenant à priori c'est 128 Go.
Dans tous les cas, on peut restreindre cette quantité de mémoire dédiée par instance (ainsi que les CPU, aussi bien le nombre que leur identifiant) très simplement. Sur un serveur mutualisé avec d'autres outils, on va évidement garder une partie de la mémoire dédiée pour les autres applications.
J'avoue ne pas comprendre cette remarque : si je cherche "coeur" ou "cur" je souhaite obtenir le même résultat. Aussi bien sur une recherche de mot que sur une recherche de phrase.
Qu'en est-il d'une recherche sur "coeur" ?
Tout comme l'est french_ci_ai (ai incluant le ou le ç par exemple).
Sur quels exemples te bases-tu ?
Pour ce qui est des recherches textuelles, je suis surpris de ce que tu avances : car non seulement le LIKE ici fonctionne "mieux" puisqu'il supporte les collations non déterministes, mais surtout, il y a textsearch qui permet de faire des recherches sur les formes infléchies, et même, si bien configuré, sur les synonymes et même traductions. J'irai pas dire sans avoir vu que PostgreSQL peut pas faire mieux, mais on est quand même loin de la Polo truquée !
On ne jouit bien que de ce quon partage.
Ce n'est effectivement pas le cas de Postgres... ce qui prouve bien que les deux outils ne sont pas conçus pour le même usage, et donc que la comparaison n'est pas toujours pertinente.
Un peu comme un gaz en fait... donc c'est une usine à gaz, CQFD.
En dehors d'un usage en cours de développement, je me demande quand même si la ré-exécution d'une requête une semaine après, tout en espérant qu'elle soit encore dans le cache (donc qu'il n'y ait pas eu plein d'autres requêtes qui la remplacent) est réellement un cas d'utilisation fréquent.
Là par contre je peux être d'accord avec toi. Au hasard, où peut-on trouver la spec complète de french_ci_ai ?




Salut
Avec la fonction remove_accents réécrite...
et sans les caractères non déterministes, sur PG12 win10 64bit cpu CORE i3 2.4GHzX2 et 8G de RAM, j'obtiens...
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 50 secondes avec
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3- 14 secondes avec
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Bravo à notre .
@+
Le monde est trop bien programmé pour être luvre du hasard
Mon produit pour la gestion d'école: www.logicoles.com
Voilà de la doc sur les collations sqlserver, difficile de faire moins documenté.
En ce qui concerne la collation postgres, j'aurais d'abord du dire "potentiellement bien plus". La collation 'fr-u-ks-level1-kc-false' reste très simple et est pareille que french_ci_ai.
Je vais faire un peu de vulgarisation Unicode et ICU ici, mais ça restera à ma sauce peu raffinée, et ne remplacera pas de vraies lectures.
Pour parler d'ICU, ça aide de comprendre quelques bases du standard Unicode, comme les points de code, les 16 plans, l'encodage principal UTF-8. Comme dit Stéphane Bortzmeyer, Unicode est complexe, mais pas inutilement complexe, parce que le monde est complexe.
Avis perso, Unicode c'est comme la vie, ça reste injuste, ça privilégie toujours l'alphabet latin qui est dans le premier plan, compatible ASCII et peut donc être stocké sur un octet (les caractères des derniers plans prennent 4 octets).
Du jargon Unicode :
ICU - International Components for Unicode
CLDR - Common Locale Data Repository
LDML - Locale Data Markup Language
Les très bon billets de blog de Daniel Vérité, contributeur postgres.
- http://blog-postgresql.verite.pro/20...7/icu_ext.html
- http://blog-postgresql.verite.pro/20...rministes.html
Pour la collation utilisée dans ce topic, 'fr-u-ks-level1-kc-false'
1 fr : code langage, BCP47 de l'IETF (l'IETF fait des RFC, des BCP...)
2 le reste préfixé par '-u-' sont les attributs de collation. http://unicode.org/reports/tr35/tr35-collation.html
Il y a au moins deux syntaxes, 'attribut-valeur-' et '@attribut=valeur;' ;
cette même collation peut s'écrire 'fr-u-ks-level1-kc-false' comme 'fr@ks=level1;kc=false'
Avec un arsenal d'attributs pareil, ça sera intéressant de montrer des cas, avec tri des numéros de téléphone par exemple, où sqlserver risque d'être complètement dans les choux.
https://github.com/unicode-org/cldr/.../collation.xml
Code XML : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13ks : <key name="ks" description="Collation parameter key for collation strength" alias="colStrength"> <type name="level1" description="The primary level" alias="primary"/> <type name="level2" description="The secondary level" alias="secondary"/> <type name="level3" description="The tertiary level" alias="tertiary"/> <type name="level4" description="The quaternary level" alias="quaternary quarternary"/> <type name="identic" description="The identical level" alias="identical"/> </key> kc : <key name="kc" description="Collation parameter key for case level" alias="colCaseLevel"> <type name="true" description="The case level is inserted in front of tertiary" alias="yes"/> <type name="false" description="No special case level handling" alias="no"/> </key>
Il y a encore plein d'axes d'amélioration : je trouverai utile, et c'est ce qui est demandé ici, que postgres autorise like pour les collations non-déterministes simples comme dans notre cas. Le côté génial c'est qu'avec ICU il y a des fondations béton, et autoriser ça c'est facile.
Showerthought, je trouve l'expression "non-déterministe" très mal choisie pour les collations, ça n'a rien à voir avec la sémantique, courante en informatique, de reproductibilité.
Empreinte PGP - Je suis les règles de Crocker.
Il y a un travail de parallélisation en cours, pour sql copy, sur la liste de diffusion pgsql-hackers : c'est peu prioritaire et annoncé pour pas avant postgres14.
Par contre pgLoader de Dimitri Fontaine, ETL écrit en CommonLisp, est massivement parallèle.
Empreinte PGP - Je suis les règles de Crocker.
Je ne suis pas d'accord, postgres est conçu pour tourner sur une machine dédiée, et le fait avec un peu de paramétrage sans problème. C'est juste qu'il est dans un sens plus adapté à la base jouet d'un étudiant, et ne va pas occuper agressivement la mémoire de sa petite bécane. Il y a express diront certains... qui quelques pages avant ont critiqué la fragmentation des binaires sur certains écosystèmes.
L'argument sqlserver est adapté aux petites bases comme aux plus grosses, qui est apparu sur la discussion mère, peut-être en fait retourné et utilisé pour postgres en l'état.
PostgreSQL est mieux adapté pour tourner sur un raspberry pi comme sur un cluster d'AMD Epyc2 réparti sur plusieurs continents (et pour une appli de ce dernier niveau, le choix ne se fera de toute façon probablement pas entre sqlserver et postgres mais entre google bigtable et google spanner).
Empreinte PGP - Je suis les règles de Crocker.

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.
 Répondre avec citation
Répondre avec citation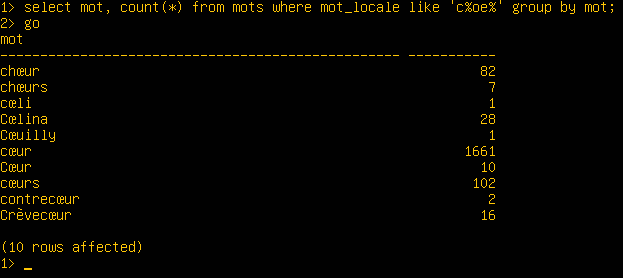

Partager