










Bonjour,
Je débute en R et j'ai un problème de traitement de données
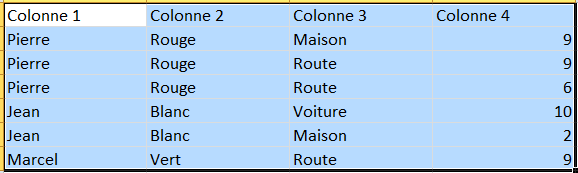
J'ai un dataframe qui ressemble à cela (avec bien entendu beaucoup plus de lignes et de colonnes)
Les lignes sont triées selon la colonne 1 puis la colonne 3 (en ordre ascendant) puis la colonne 4 (en ordre descendant) et je ne souhaite garder que la 1ère ligne de chaque groupe de la colonne 1
Le dataframe final serait :
Avec un tableur (type excel), auquel je suis un peu plus habituée, j'aurais ajouté une colonne 5 qui met un flag 1 si la valeur de la ligne n est différente de celle de la ligne n-1 et 0 sur les autres lignes et il ne me resterait plus qu'à filtrer
Pourriez-vous m'aider pour obtenir ce résultat en R ?
Avec mes remerciements

 Répondre avec citation
Répondre avec citation


Partager