












L'anonymat en ligne : les données anonymisées peuvent être reconstituées à laide de lapprentissage automatique selon les résultats d'une étude
qui remet en cause les cadres de protection de la vie privée
« Les ensembles de données anonymes peuvent être reconstitués par les personnes utilisant l'apprentissage automatique ». Cest la conclusion dune nouvelle étude réalisée récemment par des universitaires de lImperial College London et de lUCLouvain (Université catholique de Louvain). Selon eux, l'anonymisation des données personnelles ne suffit pas à protéger la vie privée sur Internet et ils saccordent à dire que les méthodes actuelles d'anonymisation des données exposent toujours les personnes à un risque de nouvelle identification.
La collecte de données personnelles des utilisateurs dInternet est devenue de plus en plus grandissante et les entreprises spécialisées dans le Big Data se développent mieux que jamais. De même, les gouvernements sont devenus eux aussi des acteurs incontournables dans la collecte de données afin de poursuivre des programmes didentification comme le récent projet Alicem en France. Une fois que ces données sont collectées, elles sont anonymisées et dans le cas des entreprises de données, elles peuvent décider de les revendre à de tiers publicitaires ou autres.
La manière dont les données sont utilisées est protégée par les lois en vigueur, telles que le RGPD, entré en vigueur dans lUE, ou la loi américaine sur la protection des consommateurs en Californie (CCPA). Ces lois décrivent des processus d'échantillonnage et danonymisation des données qui demandent de supprimer les caractères d'identification telles que les noms et les adresses électroniques, afin que les personnes ne puissent pas, en théorie, être identifiées. Après quoi, elles ne sont plus soumises aux lois protégeant les données.
Ainsi, lorsque les données anonymisées sont rachetées par des tiers, cest comme sils étaient libres den faire lutilisation quil leur plaisait. Selon les auteurs de létude, cest là que les choses deviennent dangereuses. En se basant sur les différentes expériences quils ont menées, ils ont affirmé que les ensembles de données anonymisés rachetés par les entreprises tierces aux entreprises de données peuvent souvent être modifiés grâce à une ingénierie permettant didentifier à nouveau les personnes, cela en dépit des techniques danonymisation.
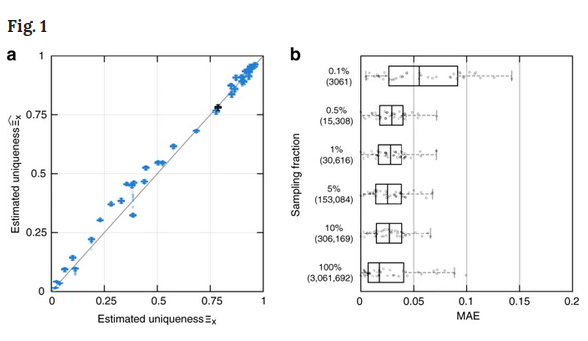
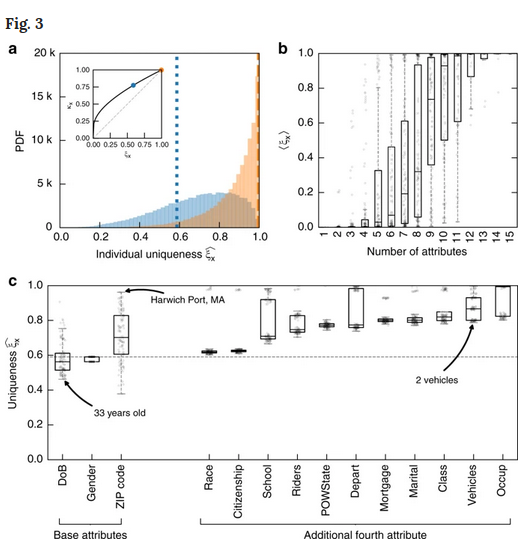
À titre illustratif, dans l'étude, 99,98 % des Américains ont été correctement réidentifiés à partir dun ensemble de données anonymisées disponible en utilisant seulement 15 caractéristiques, dont l'âge, le sexe et l'état matrimonial. « Alors qu'il y a peut-être beaucoup de gens dans la trentaine, de sexe masculin, qui vivent à New York, beaucoup moins d'entre eux sont nés le 5 janvier, conduisent une voiture de sport rouge et vivent avec deux enfants (deux filles) et un chien », a déclaré lun des auteurs de létude, Luc Rocher de l'UCLouvain (Université catholique de Louvain).
Les auteurs de létude ont déclaré quil ne suffit pas dajouter du bruit, d'échantillonner des ensembles de données ou dutiliser des techniques de dépersonnalisation pour empêcher une réutilisation des données sensibles collectées chez les usagers dInternet. Notons que lajout de bruit à une donnée est une technique qui consiste à noyer linformation dans la masse. Par exemple, si l'on veut anonymiser lâge dun patient de 22 ans, on pourrait remplacer cette information par une fourchette, telle que 18-25 ans, ce qui le rend impossible à retrouver.
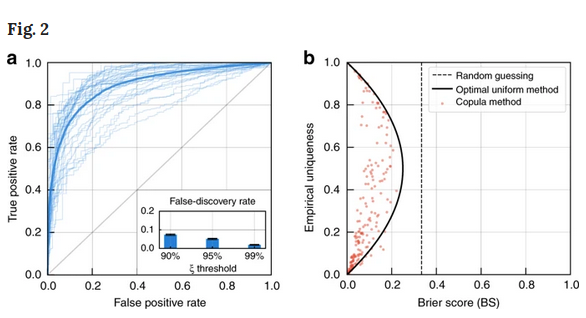
Il est également possible de jouer sur les valeurs numériques et les dates en les modifiant dun certain pourcentage. Pour se justifier, ils ont mis au point un modèle d'apprentissage automatique pour évaluer la probabilité que les caractéristiques d'un individu soient suffisamment précises pour ne décrire qu'une personne sur une population de plusieurs milliards. Ils ont également mis au point un outil en ligne, qui n'enregistre pas les données et ne sert qu'à des fins de démonstration.
Loutil en ligne permet aux gens de voir quelles caractéristiques les rendent uniques dans les ensembles de données. Il vous demande d'abord d'entrer la première partie de votre code postal (UK) ou ZIP (US), votre sexe et votre date de naissance, avant de vous donner une probabilité que votre profil puisse être réidentifié dans un jeu de données anonymes. Il vous demande ensuite votre état matrimonial, le nombre de véhicules, le statut de propriétaire et le statut d'emploi, avant de recalculer. En effet, en ajoutant plus de caractéristiques, la probabilité qu'une correspondance soit correcte augmente considérablement.
« C'est une information assez standard pour les entreprises. Bien qu'ils soient liés par les lignes directrices du GDPR, ils sont libres de vendre les données à quiconque une fois qu'elles sont rendues anonymes. Nos recherches montrent à quel point il est facile et précis de retracer les individus une fois que cela s'est produit », a déclaré Yves-Alexandre de Montjoye, coauteur de létude. Il a souligné le fait que les entreprises et les gouvernements ont minimisé le risque de réidentification pensant que les jeux de données qu'ils vendent sont toujours incomplets.
« Nos résultats contredisent cet argument et démontrent qu'un attaquant peut facilement et avec précision estimer la probabilité que le dossier trouvé appartienne à la personne qu'il recherche », a-t-il ajouté. Les chercheurs saccordent à dire que la réidentification des données anonymisées est le procédé par lequel les journalistes ont réussi à trouver et à exposer les déclarations de revenus de Donald Trump de 1985 à 1994 en mai 2019. Pour eux, la dépersonnalisation est loin dêtre une technique suffisante pour protéger la vie privée des personnes.
« On nous assure souvent que l'anonymat protégera nos données personnelles. Notre article montre cependant que la dépersonnalisation est loin d'être suffisante pour protéger la confidentialité des données des gens », a déclaré Julien Hendrickx de l'UCLouvain, coauteur de létude. Pour cela, ils estiment que les décideurs politiques doivent faire davantage pour protéger les individus contre de telles attaques, qui pourraient avoir de graves répercussions sur leur carrière ainsi que sur leur vie personnelle et financière. Il faut approfondir les normes danonymisation.
Selon le coauteur Julien Hendrickx, il est préférable que les normes d'anonymisation soient robustes et tiennent aussi compte des nouvelles menaces comme celle démontrée dans leur étude, cest-à-dire la montée en puissance de lapprentissage automatique. Daprès de Montjoye, le but de l'anonymisation est d'utiliser les données au profit de la société. « C'est extrêmement important, mais cela ne devrait pas et ne doit pas se faire au détriment de la vie privée des gens », a-t-il conclu.
Sources : Science Daily, l'outil de test en ligne, Rapport de létude
Et vous ?
Que pensez-vous des résultats de cette étude ?
Voir aussi
 Répondre avec citation
Répondre avec citation










Partager