





















L'entraînement de réseaux neuronaux et leur utilisation pour de l'inférence requiert d'énormes quantités de calculs en nombres à virgule flottante. Cependant, les formats actuels pour stocker ces nombres se focalisent sur la précision : pour des réseaux neuronaux, cette précision n'est pas aussi nécessaire que pour la simulation de l'écoulement de l'air autour d'une aile d'avion, par exemple. C'est pourquoi Google a proposé le format bfloat16 (brain floating point) en remplacement de la norme IEEE 754 (la plus utilisée) pour ces applications spécifiques, avec une première implémentation dans ses TPU de troisième génération.
Depuis lors, une bonne partie de l'industrie des semi-conducteurs se lance à la suite de Google : Intel ajoutera une implémentation de bloat16 dans ses Xeon Cooper Lake et dans ses processeurs orientés réseaux neuronaux Nervana Spring Crest ; WAVE Computing fait de même dans ses DPU et Flex-Logix dans ses codes pour FPGA.
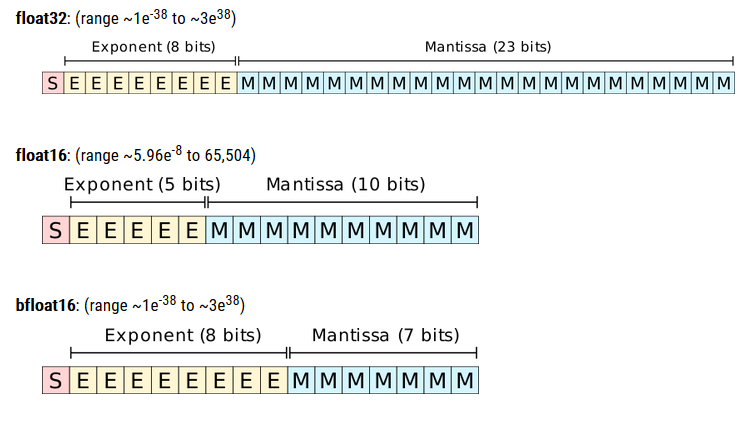
Techniquement, bfloat16 utilise seize bits pour représenter un nombre à virgule flottante, autant qu'un nombre en demi-précision selon la norme IEEE 754 (float16). Tous ces formats utilisent une forme de notation scientifique pour encoder les nombres : un bit pour le signe, quelques bits pour l'exposant (pour stocker un ordre de grandeur), le reste pour la mantisse (pour les détails sur le nombre), de telle sorte que le nombre puisse s'écrire "signe x mantisse x (2 ^ exposant). Cependant, alors qu'un float16 utilise une mantisse de dix bits (donc à peine cinq pour l'exposant), bfloat16 lui alloue à peine sept bits, ce qui laisse huit bits pour l'exposant. Par conséquent, avec un float16, on peut stocker des nombres jusque 65 504 : pour un blofat16, on peut monter jusque 3 x 10^38, à peu près autant qu'un float32. L'énorme différence est le manque de précision pour un bfloat16, ce qui pose très peu de problèmes pour un réseau neuronal, mais l'avantage est de traiter moins de bits (ce qui permet d'accroître la performance).
ARM proposera très bientôt une implémentation de ce format dans son architecture ARM-V8-A (qui inclut les extensions vectorielles SVE et les architectures trente-deux bits AArch32 Neon et soixante-quatre bits AArch64 Neon). Celle-ci se basera sur quatre instructions : BFDOT pour le produit scalaire entre deux vecteurs de deux bfloat16 chacun, BFMMLA pour un produit de deux matrices (2x4 et 4x2) en bfloat16, BFMLAL pour un produit entre deux bfloat16, BFCVT pour la conversion avec float32. Ces instructions sont vraiment prévues pour des réseaux neuronaux, pas pour des calculs plus génériques, même si des scientifiques les envisagent pour accélérer certaines parties de leurs codes, les moins sensibles au manque de précision.
Le format bfloat16 pose cependant un certain nombre de questions. La norme IEEE 754 a pu s'imposer grâce à sa définition rigoureuse du résultat de toutes les opérations : tous les processeurs ne donnent pas forcément les mêmes résultats pour les mêmes opérations (puisque leur ordre est laissé libre au concepteur du processeur), mais les différences sont bornées par la norme (on parle de "bruit d'arrondi"). Au contraire, pour bfloat16, rien n'est vraiment normalisé : on n'a aucune certitude que le résultat d'un même calcul sur deux processeurs différents sera identique ou même proche.
Image : WikiChip.
Source : The Next Platform.
 Répondre avec citation
Répondre avec citation


Partager