1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| //Start of specific code
//Extract data from Bonjour.xml
$content = file_get_contents( dirname( __FILE__ ) . '/Bonjour.xml' );
if ($content === false) echo "ERROR CANNOT READ file";
//Extraction of <w:std> tags included in Word XML Template
$dom = new DOMDocument();
$dom->loadXML($content);
//Enregistrement du NameSpace Microsoft Word
$nsp = ['w' => 'http://schemas.openxmlformats.org/wordprocessingml/2006/main'];
//Get item elements <w:sdt> with linked id's in XML document
foreach ($dom->getElementsByTagNameNS($nsp['w'], 'sdt') as $sdt)
{
$id = $sdt->getElementsByTagNameNS($nsp['w'], 'id')->item(0);
$idvalue = $id -> attributes -> getNamedItem( 'val' );
//$idvalue = $id->getAttributeNS($nsp['w'], 'val'); //Je n'arrive pas à faire fonctionner la fonction getAttributeNS
$ids[]=$idvalue->value;
echo 'local name: ', $sdt->localName, ', prefix: ', $sdt->prefix, ' ID:',$idvalue->value, "\n",'<br/>';
echo '</pre>';
}
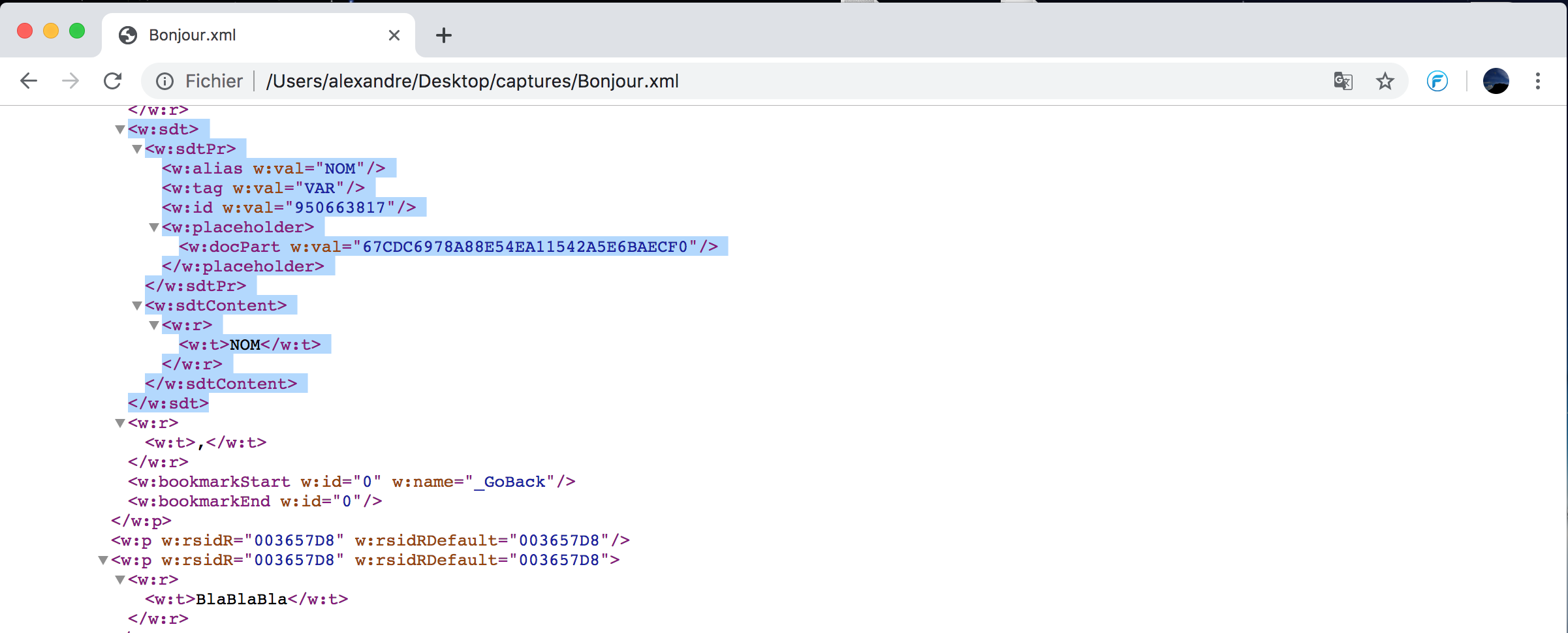
// Update text value for a balise sdt with ID 950663817 with XPath
$target_id = array_search('950663817', $ids);
$xp = new DOMXPath($dom);
$xp->registerNameSpace('w', 'http://schemas.openxmlformats.org/wordprocessingml/2006/main');
$textNL = $xp->query('//w:sdt[.//w:id/@w:val='.$ids[$target_id].']/w:sdtContent//w:t/text()');
if ($textNL->length)
{
$text = $textNL->item(0);
$text->parentNode->replaceChild($dom->createTextNode('Toto'), $text);
}
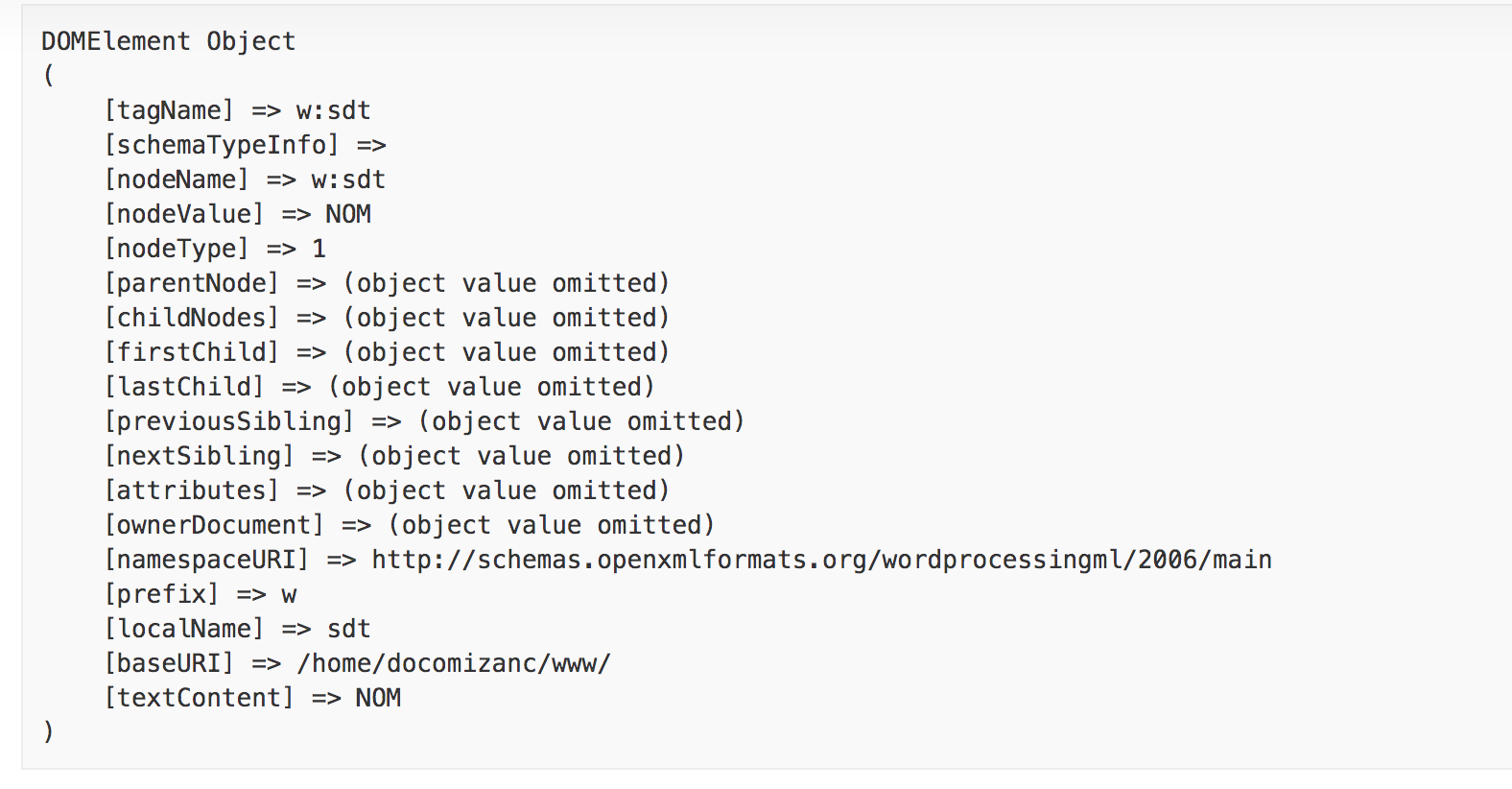
//Check update of textnode
var_dump($textNL);
//Save updated xml in test.xml file
$dom->save("test.xml"); // Ici rien ne se passe. Je m'attends à avoir un doc test.xml créé mais je me plante à un endroit que je n'identifie pas
//End of specific code |











 Répondre avec citation
Répondre avec citation





Partager