



Bonjour,
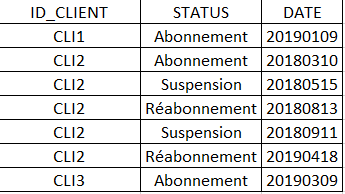
j'ai une table R qui ressemble à celle-ci
Et je souhaite obtenir une table qui ressemble à celle-ci s'il vous plait.
Merci d'avance de votre aide
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter







Bonjour,
j'ai une table R qui ressemble à celle-ci
Et je souhaite obtenir une table qui ressemble à celle-ci s'il vous plait.
Merci d'avance de votre aide

Tu as la fonction reshape en format direction="long", varying étant les numéros ou les noms des colonnes à éclater et sep, le séparaetur, c'est-à-dire que les noms des colonnes résultantes sont à gauche de ce séparateur. Voir son aide en ligne.
ci-joint les données :
time.xlsx
J'ai testé ce bout de code :
Erreur :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
Error in guess(varying) :
failed to guess time-varying variables from their names




Bonjour.
Je n'utilise pas le package {reshape}, je suis plutôt {reshape2} ou {tidyr} pour transposer.
Une solution avec {reshape2} et un peu de {dplyr}, sans doute largement optimisable...John Mount explique ici une solution qui passerait par son package {cdata} et une table qui pilote la transformation de transposition.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Bon courage.
Olivier

Bonjour,
La fonction reshape() du package stats indiquée par faubry nécessite de renommer les variables (de même que la fonction fonction wideToLong() du package lsr proposée dans la suite du message).
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8> df id Status_1 Date_1 Status_2 Date_2 Status_3 Date_3 Status_4 Date_4 Status_5 Date_5 Status_6 Date_6 1 CLI1 Abonnement 20190109 <NA> NA <NA> NA <NA> NA <NA> NA NA NA 2 CLI2 Abonnement 20180310 Suspension 20180515 Reabonnement 20180813 Suspension 20180911 Reabonnement 20190418 NA NA 3 CLI3 Abonnement 20190309 <NA> NA <NA> NA <NA> NA <NA> NA NA NA 4 CLI4 Abonnement 20170916 Desabonnement 20181213 Reabonnement 20181213 Desabonnement 20190425 <NA> NA NA NA 5 CLI5 Abonnement 20181215 <NA> NA <NA> NA <NA> NA <NA> NA NA NA 6 CLI6 Abonnement 20180605 <NA> NA <NA> NA <NA> NA <NA> NA NA NA
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15> df_l id time Status Date CLI1.1 CLI1 1 Abonnement 20190109 CLI2.1 CLI2 1 Abonnement 20180310 CLI3.1 CLI3 1 Abonnement 20190309 CLI4.1 CLI4 1 Abonnement 20170916 CLI5.1 CLI5 1 Abonnement 20181215 CLI6.1 CLI6 1 Abonnement 20180605 CLI2.2 CLI2 2 Suspension 20180515 CLI4.2 CLI4 2 Desabonnement 20181213 CLI2.3 CLI2 3 Reabonnement 20180813 CLI4.3 CLI4 3 Reabonnement 20181213 CLI2.4 CLI2 4 Suspension 20180911 CLI4.4 CLI4 4 Desabonnement 20190425 CLI2.5 CLI2 5 Reabonnement 20190418
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15> df_l id rep Status Date 1 CLI1 1 Abonnement 20190109 2 CLI2 1 Abonnement 20180310 3 CLI3 1 Abonnement 20190309 4 CLI4 1 Abonnement 20170916 5 CLI5 1 Abonnement 20181215 6 CLI6 1 Abonnement 20180605 8 CLI2 2 Suspension 20180515 10 CLI4 2 Desabonnement 20181213 14 CLI2 3 Reabonnement 20180813 16 CLI4 3 Reabonnement 20181213 20 CLI2 4 Suspension 20180911 22 CLI4 4 Desabonnement 20190425 26 CLI2 5 Reabonnement 20190418
Cordialement,
bonjour une solution avec le tidyverse et la fonction gather (à tester)
cldt
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5

Bonjour,
Il n'y a pas besoin de renommer les variables avec reshape. On peut spécifier dans l'argument varying quelles sont les colonnes qui appartiennent à la même variable en indiquant leur position.
cdlt
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Bonjour,
Je vous remercie de vos réponses
Juste histoire d'aller au bout de la piste du package {cdata} voici la solution proposée...
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
Bon courage.
Olivier

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.

 Répondre avec citation
Répondre avec citation
Partager