











L'IA de Google est capable de traduire ce que vous dites tout en conservant les caractéristiques de votre voix,
Translatotron en est encore au stade expérimental
Des systèmes de traduction de parole à parole ont été développés au cours des dernières décennies dans le but d'aider les personnes qui parlent des langues différentes à communiquer les unes avec les autres. De tels systèmes ont généralement été divisés en trois composants distincts: reconnaissance automatique de la parole pour transcrire le discours source en texte, traduction automatique pour traduire le texte transcrit dans la langue cible et synthèse par synthèse vocale (TTS) pour générer de la parole dans la cible. langue du texte traduit.
Diviser la tâche en une telle cascade de systèmes a été un grand succès, alimentant de nombreux produits de traduction vocale commerciaux, y compris Google Translate. Mais Google voudrait aller plus loin. Dans un projet de recherche, lentreprise a annoncé son objectif : traduire directement la parole dune langue en parole dans une autre langue, sans recourir à une représentation textuelle intermédiaire. Si lentreprise y arrivait, cela rendrait la traduction de parole à parole plus rapide, permettrait déviter les erreurs entraînées par toutes ces étapes (comme dans le jeu du « téléphone », un mot peut vite être modifié au cours de transcriptions successives) et, plus important peut-être, permettrait de refléter plus facilement la voix source.
À cette fin, les chercheurs ont commencé à réfléchir sur des moyens de convertir les spectrogrammes (en quelques sortes une image qui contient les fréquences de ce signal audio) de paroles dans une langue donnée en spectrogrammes dans une autre. Ce processus est très différent du processus en trois étapes et a ses propres faiblesses, mais il a aussi des avantages.
Premièrement, bien que complexe, il sagit essentiellement dun processus en une étape plutôt que de plusieurs étapes. En dautres termes, si vous disposez dune puissance de traitement suffisante, le système pourrait fonctionner plus rapidement. Mais plus important encore, pour beaucoup, le processus permet de conserver la voix source. La traduction ne sort donc pas de manière robotique, mais avec le ton et la cadence de la phrase originale.
Naturellement, cela a un impact énorme sur l'expression, et quelqu'un qui s'appuie régulièrement sur la traduction ou la synthèse vocale comprendra que non seulement ce qu'il dit est reflété, mais également de la façon dont il le dit.
Arrive alors Translatotron
Translatotron, comme lappelle le projet, est laboutissement de plusieurs années de travaux connexes, bien quil sagisse toujours dune expérience. Les chercheurs de Google et dautres chercheurs étudient la possibilité dune traduction directe de parole à parole depuis des années, mais ce nest que récemment que ces efforts ont porté leurs fruits.
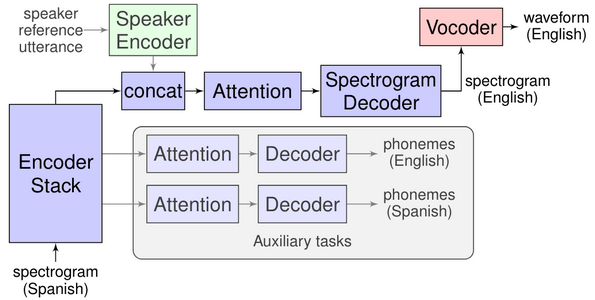
Google avance que « Dans Traduction directe parole à parole avec un modèle séquence à séquence, nous proposons un nouveau système expérimental basé sur un seul modèle attentif séquence à séquence pour la traduction directe parole à parole sans faire appel à des intermédiaires de représentation textuelle. Surnommé Translatotron, ce système évite de diviser la tâche en étapes séparées, offrant quelques avantages par rapport aux systèmes en cascade, notamment une vitesse de déduction plus rapide, évitant naturellement les erreurs de combinaison entre la reconnaissance et la traduction, facilitant la conservation de la voix du locuteur d'origine après la traduction, et offrant un meilleur traitement des mots qui n'ont pas besoin d'être traduits (par exemple, noms et noms propres) ».
Et Google dindiquer que « Translatotron est basé sur un réseau séquence à séquence qui prend en entrée les spectrogrammes source et génère des spectrogrammes du contenu traduit dans la langue cible. Il utilise également deux autres composants entraînés séparément: un vocodeur neuronal convertissant les spectrogrammes de sortie en formes d'onde dans le domaine temporel et, éventuellement, un encodeur pouvant être utilisé pour conserver le caractère de la voix du locuteur source dans la parole traduite synthétisée. Au cours de la formation, le modèle séquence à séquence utilise un objectif multitâche pour prédire les transcriptions source et cible en même temps que la génération de spectrogrammes cible. Cependant, aucune transcription ou autre représentation textuelle intermédiaire n'est utilisée lors de l'inférence ».
Préserver les caractéristiques vocales
Google avance quen intégrant un réseau dencodeurs, Translatotron est également capable de conserver les caractéristiques vocales de la source dans le discours traduit, ce qui rend le discours traduit plus naturel. Cette fonctionnalité s'appuie sur les recherches précédentes de Google sur lanalyse de la source vocale et son adaptation pour TTS. Le réseau dencodeurs est pré-entraîné sur la tâche danalyse de la source, ce qui lui permet d'apprendre à coder les caractéristiques de la source à partir d'un court exemple d'énoncé. Conditionner le décodeur de spectrogramme sur ce codage permet de synthétiser une parole ayant des caractéristiques similaires, même si le contenu est dans une langue différente.
Performance
« Nous avons validé la qualité de la traduction de Translatotron en mesurant le score BLEU, calculé avec du texte transcrit par un système de reconnaissance vocale. Bien que nos résultats soient à la traîne par rapport à un système en cascade classique, nous avons démontré la faisabilité de la traduction vocale directe de bout en bout ».
Les premières démonstrations de cette technologie ont étés faites en espagnol. Google a utilisé deux bases de données où sont traduites des phrases de lespagnol vers langlais. Vous pouvez écouter une vingtaine de phrases, traduites depuis cette langue vers langlais avec le Translatotron. Le résultat nest pas encore parfait.
Les chercheurs admettent que la précision de la traduction nest pas aussi bonne que celle des systèmes traditionnels, qui ont eu plus de temps pour affiner leur précision. Mais beaucoup de traductions résultantes sont (au moins partiellement) assez bonnes, et pouvoir inclure une expression est un trop grand avantage pour le laisser passer. En fin de compte, léquipe décrit modestement son travail comme un point de départ démontrant la faisabilité de lapproche.
Le document décrivant la nouvelle technique a été publié sur Arxiv, et vous pouvez parcourir des exemples audio, avec la source, la traduction traditionnelle et la traduction avec Translatotron. Il faut garder à lesprit que ces extraits audio nont pas été tous sélectionnés pour la qualité de leur traduction, mais servent plutôt d'exemples de la façon dont le système conserve l'expression tout en obtenant l'essentiel du sens.
Échantillon audio
Source : Google
Et vous ?

 Répondre avec citation
Répondre avec citation




Partager