J'ai du mal avec votre modèle de données.
Même s'il n'y a que 3 colonnes ça me pique un peu les yeux.
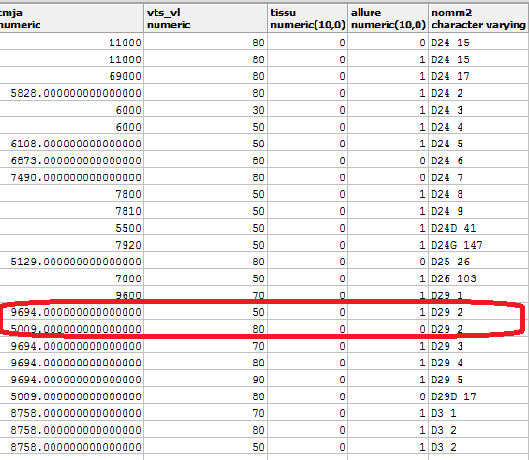
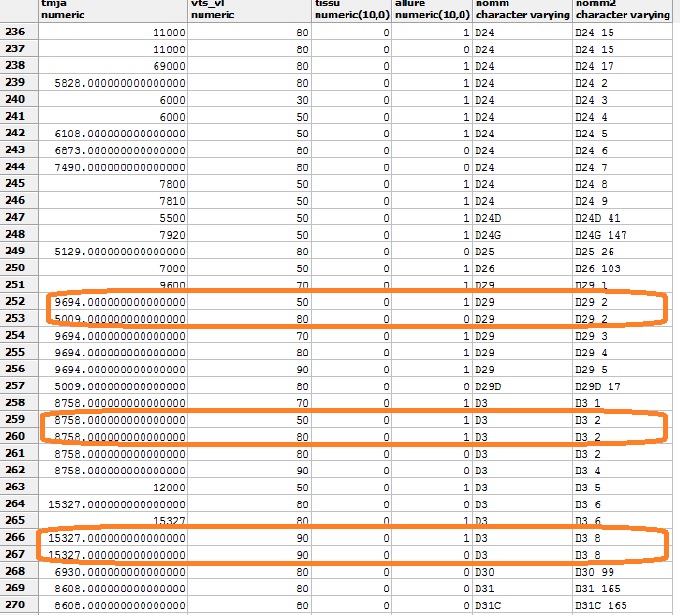
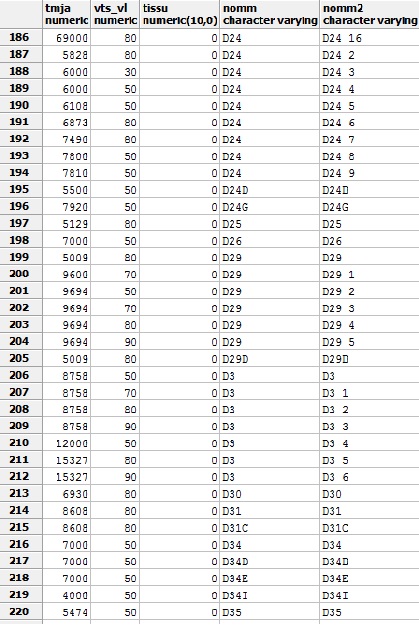
Si j'ai bien compris le tjma correspond à : "trafic moyen journalier annuel".
Dans la formulation même de la définition de la colonne on a bien une notion de temps, non ?
Or le nom de la route est intemporelle.
Comment pouvez-vous mélanger tout ça dans le même sac ? et éludant la notion de date ? et, pour finir, pour corriger une ligne par rapport à une autre sans ordre logique sinon celui du traitement.
La "normalité" voudrait qu'il y ait dans ton système d'information au moins 2 tables.
T_route
Id_route
Nom_route
T_TJMA
Id_tjma
Id_route
Position_GPS_du_relevé
Description_des_conditions_du_relevé
Date_début_collecte
Date_fin_collecte
Nombre_de_véhicules
et encore je m'arrête là 
Donc avant de vous lancer dans cet update, merci de nous expliciter les tenants et les aboutissants du problème et particulièrement ce à quoi, in fine, votre opération va vous permette de faire.










 Répondre avec citation
Répondre avec citation








Partager