









Bonjour à tous,
Je vous sollicite à nouveau (après tant dannées) pour vous exposer un problème de taille.
Il sagit du thème de la réplication en multi-sites.
Notre principe de fonctionnement actuel :
Nous travaillons sur un logiciel, qui utilise un server de fichier et une base SQL server. En gros, nos fichiers sont caractérisés par nos tables SQL. Pour linstant, nos clients travaillent avec une seule base commune et là tout va bien.
Notre problématique :
Il y a maintenant des clients qui veulent travailler en multi-sites (par exemple : un en Chine, lautre en Argentine). Et là, vient le problème de lenvoie de données. En effet, la connexion dun site à lautre est beaucoup trop lente. Actuellement, ils ont décidé de travailler avec deux bases différentes et nous avons développé une commande dexportation de données qui exporte les fichiers dune base à lautre. Mais les vas et viens provoquent une certaine divergence dans le temps entre les deux bases.
Ce que nous voulons :
Avoir une seule base commune aux deux en optimisant les temps de transfert bien sûr. Mais si on imagine que la connexion internet nest plus possible, un des sites ne peut plus travailler et cest inacceptable.
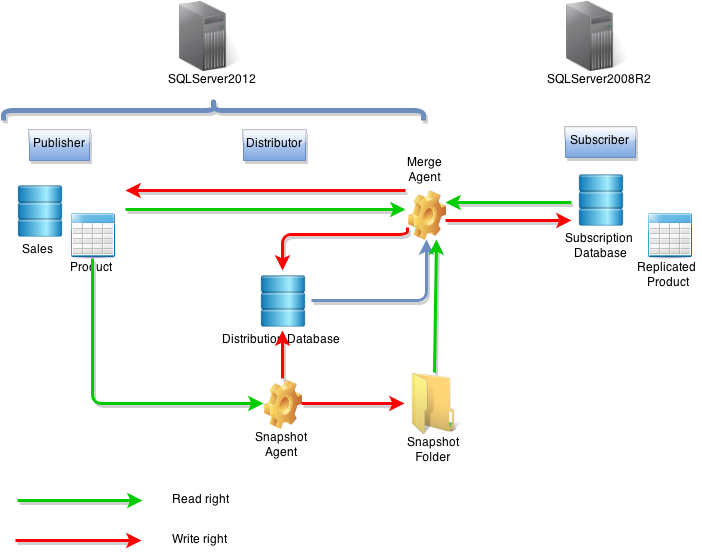
Les solutions :
Voilà que je me tourne vers vous, pour, dans un premier temps, exposer les solutions qui existent. Nous avons notamment exploré les sujets de réplications entre base (sql mirroring, groupes de disponibilité, ). Le gros challenge est que la lecture et lécriture de données puissent être possible dans les bases "secours" et surtout le "merge" de la base secours vers la base maitresse.
Ps : Je tiens à vous remercier davance et je voulais vous remercier aussi pour la qualité de votre site car même si je ne pose pas souvent de questions, je viens souvent lire ici et cest une mine dor (mieux quà lécole pour apprendre).
 Répondre avec citation
Répondre avec citation














Partager