









Bonjour,
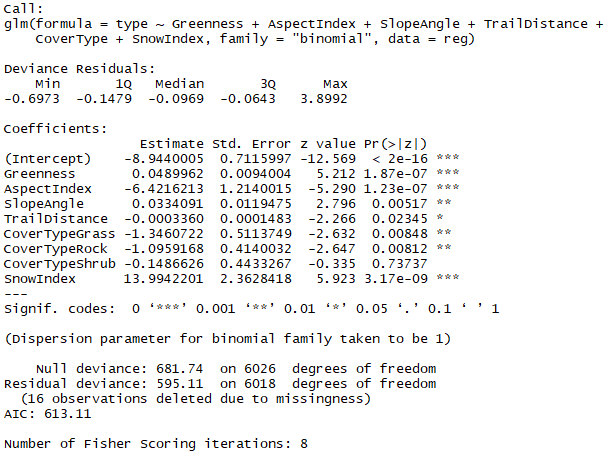
J'ai realise une regression logistique sur R, donc le resultat est presente ci dessous.
Mon but est de differencier deux groupes a et b, le groupe a etant ici en refference.
Quand j'effectue un test t pour etudier le facteur "AspectIndex" (quantitatif, prenant des valeurs entre 0 et 1), je trouve que ce facteur est significativement superieur dans le groupe b. Comment se fait il alors que le coefficiant Estimate soit inferieur a 0 ?
Le facteur qualitatif "Cover" classe les donnees en 4 groupes : Conifer (la refference, donc pas indique ci-dessous), Grass, Rock, Shrub. Dans ma regression, j'obtient des p values significatives pour Grass et Rock, mais pas pour Shrub. Pensez-vous qu'il serait judicieux de retirer le groupe "Shrub" de mon analyse ? si oui comment ?
Merci d'avoir pris le temps de lire ce message ! Et desole pour les accents, j'ecris actuellement du Canada !
 Répondre avec citation
Répondre avec citation


Partager