











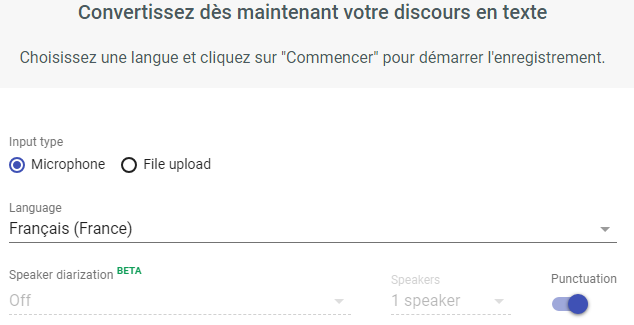
Quelles sont les API de traitement de la parole que vous préférez en 2019 ?
Petit tour d'horizon sur les API les plus populaires du marché
Le traitement de la parole est un domaine très populaire de lapprentissage automatique. Il existe une demande importante pour transformer le discours humain en texte et le texte en discours. Cela est particulièrement important pour le développement du libre-service dans différents endroits: magasins, transports, hôtels, etc. En effet, les machines remplacent de plus en plus de main-d'uvre humaine et ces machines devraient pouvoir communiquer. Cest pourquoi la reconnaissance vocale est une perspective et un domaine important de lintelligence artificielle et de lapprentissage automatique.
Aujourd'hui, de nombreuses grandes entreprises fournissent des API pour effectuer différentes tâches d'apprentissage machine. La reconnaissance vocale ne fait pas exception. Il nest pas nécessaire que vous soyez un expert en traitement de langage naturel pour utiliser ces API. Ils fournissent généralement une interface pratique. Tout ce que vous avez à faire est denvoyer une requête HTTP avec le contenu requis au serveur de lAPI. Ensuite, vous recevrez la réponse avec les tâches terminées. Cette approche est utile lorsque vous navez pas besoin de quelque chose de spécial (en d'autres termes, si votre problème est standard et connu). L'avantage supplémentaire de cette méthode est que vous pouvez économiser autant de ressources précieuses que le temps et l'argent.
Néanmoins, il existe de nombreuses situations dans lesquelles vous ne pouvez pas utiliser l'API et devez développer un système de reconnaissance vocale à partir de zéro. Cette méthode est assez complexe, elle nécessite de nombreux efforts et ressources, mais vous pouvez ainsi créer un système parfaitement compatible avec vos besoins. En outre, il est possible d'améliorer la qualité des résultats si vous construisez vous-même les algorithmes. Quoi qu'il en soit, il est bon de connaître les API. Vous pouvez comprendre ce que chaque API peut faire, ses avantages et inconvénients, etc. Ainsi, vous serez en mesure de détecter quand vous devriez utiliser une API (et quelle API) et quand vous devriez penser à votre propre système.
Il est donc question ici de parler d'API populaires pouvant fonctionner avec la parole humaine. Nous allons aussi évoquer quelques API moins connues.
Google Cloud Speech-to-Text API
Google assure que son API dispose d'une reconnaissance vocale performante :
Envoyé par Google
Détection automatique de la langue : l'API vous permet d'identifier la langue de l'énoncé (fonctionnalité limitée à quatre langues). Vous pouvez ainsi retranscrire des recherches ("Quelle température fait-il à Paris ?", par exemple) et commandes vocales (comme "Augmenter le volume").
Transcriptions audio en temps réel de contenus de courte ou longue durée : Cloud Speech-to-Text est capable de transmettre instantanément des résultats au format texte. Le discours est reconnu dès que le contenu audio est lancé ou que l'utilisateur parle. Vous pouvez également fournir un fichier audio à Cloud Speech-to-Text pour obtenir sa transcription. L'API vous permet d'analyser des contenus audio de courte ou longue durée.
Expressions clés : Vous pouvez personnaliser la reconnaissance vocale pour un contexte particulier en fournissant un ensemble de mots et d'expressions susceptibles d'être utilisés. Cette fonctionnalité est particulièrement utile, car elle permet d'ajouter des mots et des noms personnalisés au vocabulaire existant et de prédéfinir des commandes vocales.
Une sélection de modèles prédéfinis adaptés à votre cas d'utilisation : Cloud Speech-to-Text comprend plusieurs modèles de reconnaissance vocale prédéfinis (tels que le modèle adapté aux commandes vocales) que vous pouvez mettre à profit dans votre cas d'utilisation. Par exemple, Google explique que son modèle de transcription vidéo prédéfini est idéal pour indexer ou sous-titrer des vidéos et/ou des contenus comportant plusieurs locuteurs. Il emploie une technologie de machine learning comparable à celle utilisée pour créer des sous-titres dans YouTube.
IBM Watson Speech to Text
IBM Watson Speech to Text est un service fourni par IBM Watson capable de convertir la parole humaine en texte. IBM Watson prend en charge la personnalisation non seulement pour le dictionnaire de mots spécifiques mais également pour les conditions acoustiques particulières. Vous pouvez donc adapter le système à l'environnement dans lequel vous prévoyez de l'utiliser. La principale faiblesse de IBM Watson Speech to Text réside dans le très petit nombre de langues prises en charge. De plus, les modèles personnalisés sont disponibles pour un nombre de langues encore plus réduit. Pour le moment, des fonctions telles que la détection de mots-clés et l'étiquetage des locuteurs sont disponibles en version bêta.
Voici les fonctionnalités présentés par IBM :
- Puissante reconnaissance de la parole en temps réel : Transcrivez automatiquement laudio de 7 langues en temps réel. Identifiez et transcrivez rapidement ce qui est discuté, même à partir d'audio de qualité inférieure, à travers une variété de formats audio et d'interfaces de programmation (HTTP REST, Websocket, Asynchronous HTTP).
- Moteur de parole extrêmement précis : Personnalisez votre modèle pour améliorer la précision de la langue et du contenu qui vous intéressent le plus, tels que les noms de produits, les sujets sensibles ou les noms de personnes. Reconnaît différents haut-parleurs dans votre audio. Utilisez des mots clés spécifiés en temps réel avec une grande précision et une grande confiance
- Conçu pour supporter divers cas d'utilisation : Transcrivez l'audio pour différents cas d'utilisation, allant de la transcription audio en temps réel d'un microphone à l'analyse de 1 000 enregistrements audio de votre centre d'appels pour fournir des analyses significatives.
Microsoft Azure Bing Speech API
L'API Microsoft Azure Bing Speech est un composant des services cloud Microsoft Azure permettant de résoudre deux tâches simultanément: la conversion parole / texte et la conversion texte-parole.
Voici les différentes fonctionnalités évoquées par Microsoft :
La reconnaissance vocale convertit de la parole audio en texte pour permettre une interaction intuitive : Ajoutez facilement la conversion de parole en texte en temps réel à vos applications pour des usages tels que les commandes vocales, les transcriptions en temps réel ou lanalyse de journaux de centre dappels. Adaptez vos modèles de reconnaissance vocale aux styles oraux, expressions ou jargon des utilisateurs, ainsi quaux bruits de fond, accents et caractéristiques vocales spécifiques de votre scénario. Convertissez un enregistrement vocal en texte. Appelez lAPI pour reconnaître le signal audio provenant du microphone, dautres sources audio de streaming en temps réel ou dun fichier audio enregistré. À mesure que le signal audio est envoyé au serveur, des résultats de reconnaissance partielle sont renvoyés si vous le souhaitez. Vous pouvez utiliser lAPI pour générer des applications intelligentes déclenchées par la voix.
La synthèse vocale confère une voix naturelle à vos applications : Générez des applications et services intelligents qui sadressent aux utilisateurs en langage naturel grâce au service de synthèse vocale. Convertissez du texte en audio en temps quasi réel, et adaptez la vitesse, la tonalité, le volume et dautres paramètres de la parole. Donnez à votre application une voix caractéristique unique et reconnaissable à laide de modèles vocaux personnalisés. Enregistrez et chargez simplement des données dapprentissage. Le service crée ensuite une police de la voix unique calquée sur votre enregistrement.
Traduction vocale : Dotez votre application de fonctionnalités de traduction vocale en temps réel dans lune des langues prises en charge, et obtenez une traduction de texte ou de parole. Les modèles de traduction vocale sont basés sur des technologies de pointe en matière de reconnaissance vocale et de traduction automatique neuronale. Ils sont optimisés pour comprendre la façon dont les gens parlent dans la vie réelle, et générer des traductions dune qualité exceptionnelle.
Amazon Transcribe
Amazon Transcribe fait partie de l'infrastructure Amazon Web Services. Vous pouvez analyser vos documents audio stockés dans le service Amazon S3 et obtenir le texte à partir de l'audio.
Amazon Transcribe peut ajouter de la ponctuation et du formatage du texte. Une autre fonction intéressante fournie par ce service est la prise en charge de la téléphonie audio. C'est parce que l'audio des conversations téléphoniques est souvent de mauvaise qualité. Les développeurs dAmazon Transcribe ont donc estimé quils devaient traiter ce type daudio de manière spécifique. Le système ajoute des horodatages pour chaque mot du texte. Ainsi, vous pourrez faire correspondre chaque mot du texte à la place correspondante dans le fichier audio.
Amazon affirme que son API Amazon Transcribe peut reconnaître lorsque le locuteur change et attribuer le texte transcrit de manière appropriée. Cela peut considérablement réduire la charge de travail nécessaire pour transcrire de l'audio avec plusieurs locuteurs comme les appels téléphoniques, les entretiens et les émissions de télévision. Amazon Transcribe vous permet également d'enrichir et de personnaliser votre vocabulaire de reconnaissance vocale. Vous pouvez ajouter de nouveaux mots au vocabulaire de base et générer des transcriptions de haute précision spécifique à votre utilisation, comme des noms de produits, une terminologie propre au secteur ou des noms de personnes.
Amazon Polly
Amazon Polly est un service qui transforme le texte en paroles réalistes, vous permettant de créer des applications qui parlent et de bâtir une toute nouvelle gamme de produits dotés de parole. Amazon Polly est un service de synthèse vocale qui exploite des technologies avancées de deep learning pour synthétiser la parole de façon naturelle.
Amazon Polly convertit non seulement le texte en parole, mais permet également dajuster certains paramètres de parole. Par exemple, vous pouvez configurer différentes voix (genre), volume, prononciation, vitesse du discours, hauteur de ton et quelques autres propriétés. Avec des douzaines de voix réalistes dans différentes langues, vous pouvez sélectionner la voix idéale et créer des applications vocales qui fonctionnent dans de nombreux pays différents.
VoxSigma API
L'API VoxSigma pour la conversion parole en texte est un produit de la société Vocapia Research. Cette société est spécialisée dans le domaine de la technologie de la parole et du langage. L'API VoxSigma peut non seulement convertir le discours saisi en texte, mais également effectuer l'identification de la langue et l'alignement parole-texte. Une autre caractéristique intéressante de lAPI est quelle peut ajouter de la ponctuation au texte de sortie, calculer le score de confiance pour la sortie. En outre, l'API VoxSigma peut traiter des entités numériques et d'autres entités (telles que des devises, par exemple) de manière unique. Il est possible de personnaliser le modèle de langue disponible, mais vous devez pour cela contacter la société et lui parler directement.
API Nexmo Voice
L'API Nexmo Voice n'est pas une API autonome. Vous pouvez l'utiliser pour appeler. Par exemple, si vous souhaitez appeler quelqu'un, vous pouvez utiliser l'API Nexmo Voice pour convertir du texte en parole. Nexmo est la société qui fournit des services de communication programmable. L'ensemble des fonctionnalités disponibles n'est pas très riche. Cela inclut uniquement la possibilité de changer le genre de voix (homme ou femme) ainsi que de changer l'accent du discours.
Sources : Google, IBM, Microsoft, Amazon Transcribe, Amazon Poly, VoxSigma, Nexmo
Et vous ?
Vous êtes-vous déjà servi d'une API de traitement de la parole ?
Voir aussi :


 Répondre avec citation
Répondre avec citation















Partager