Bonsoir,
Permettez-moi de participer au débat.
Escartefigue, nous redondons à loccasion (verrou mortel par exemple), mais bon !
Fred, en ce qui concerne le DBTG, il est vrai que dans lorganigramme CODASYL, il sagit dune instance du comité responsable des langages de programmation, mais quand on parle de DBTG dans le contexte des bases de données on peut faire comme Codd et se cantonner au terme CODASYL, connu de tous. Dans les années soixante-dix, quand je donnais mes cours sur les bases de données, je faisais mention de ce distinguo.
En guise de préambule :
Je rappelle que le SGBD (réseau) IDS a été conçu et développé au milieu des années 60 par un ingénieur de grand talent, Charles Bachman (Prix Turing en 1973, la plus haute distinction, une sorte Nobel en informatique). IDS est larchétype des SGBD de type réseau (CODASYL).
Je rappelle encore que le modèle relationnel est une théorie qui fut proposée en 1970 par un mathématicien et logicien du nom de E.F. Codd (Prix Turing en 1981), fondée sur la logique du 1er ordre (le calcul relationnel), et pour laquelle il a proposé son alter ego ensembliste (bien quil place le calcul relationnel un cran au-dessus), qui nous plus familier, grâce à son algèbre relationnelle laquelle faut-il le rappeler est complète.
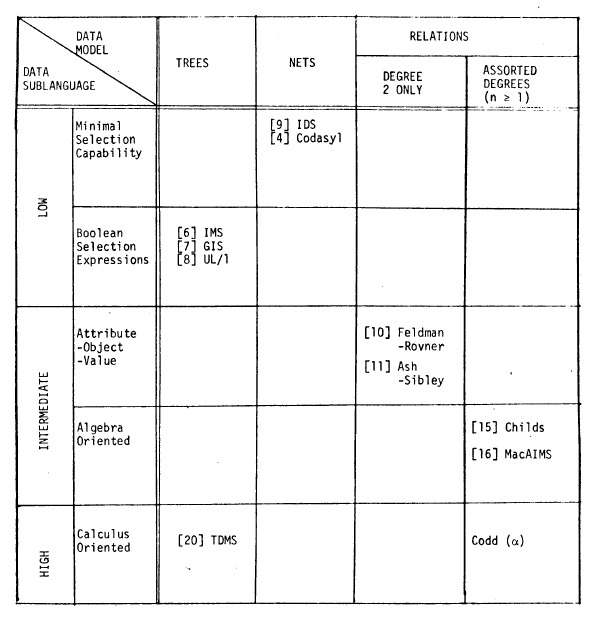
Pour Codd, les langages de manipulation des bases de données se positionnent selon 3 niveaux.
Extrait de A data base sublanguage founded on the relational calculus (1971) :
Je cite Codd (toujours dans A data base sublanguage founded on the relational calculus) qui situe IDS (et CODASYL) au niveau inférieur parce que le langage est procédural :
« Most readers of this paper will have some familiarity with the existing systems (and the CODASYL proposal) cited in the top two rows of this table. The data sublanguages for these systems, so far as they can be identified separately* from their host languages, are rather primitive. Not even boolean selection expressions are provided in IDS [9] and CODASYL [4]. Therefore, there is a heavy dependence on the host language for iterative scanning and searching.
...
*The separation in the CODASYL proposal is clear. »
Codd place lalgèbre relationnelle au niveau intermédiaire parce que pour obtenir le résultat voulu, on enquille les opérations (projection, restriction, union, jointure, etc.) les unes à la suite des autres, dans lordre qui nous convient, mais de façon non procédurale (pas de IF ou de LOOP et toutes ces sortes de choses propres à la programmation) : une 1re opération appliquée à une relation (par exemple une restriction) produit une nouvelle relation qui peut à son tour participer à une autre opération (par exemple une jointure) pour la production dune autre relation, etc., jusquà lobtention du résultat voulu qui bien entendu est une relation.
Le calcul relationnel est au niveau supérieur, parce que lobtention du résultat voulu ne nécessite quune seule instruction.
A noter que SQL est à classer à ce niveau, dans la mesure où le résultat (table, tant quà faire !) est la combinaison dun ensemble dopérations (jointures, unions, restriction (WHERE), etc.) conclue par la projection finale (ligne SELECT).

Envoyé par
Artemus24

Toutes les données ne sont pas de type relationnel[le] ... Il se peut que le modèle relationnel ne soit pas ce que vous désirez.
Gordon, as-tu un exemple de données que le modèle relationnel serait incapable de prendre en compte alors quun sous-langage basé sur la norme CODASYL permettrait de le faire ? Au plan structurel, il ny a rien qui puisse être représenté par un modèle réseau qui ne puisse être représenté par seulement des relations, et au plan manipulation des données, il ny a pas de requête qui puisse être satisfaite par un modèle réseau qui ne puisse lêtre par le modèle relationnel.
Envoyé par
Artemus24
Elle a surtout linconvénient que vous devez créer votre propre moteur de recherche.
Tu métonnes ! Ça a pris entre deux et trois ans pour léquipe qui a inventé SYSTEM/R (et SQL, du reste intégralement pompé sans vergogne par Ellison), le temps de sortir un 1er jet, remplacé ex nihilo par une 2e version...
Envoyé par
Artemus24
la fonctionnalité reste la recherche basée sur des liens, même si ces liens sont de types relationnelles, hiérarchiques, réseaux, ...
Il ny a pas de liens en relationnel ! Je pense que tu as pu être induit en erreur par le concept de clé étrangère, qui nest pas un lien mais une référence utilisée dans la définition dune contrainte dintégrité référentielle, selon laquelle un tuple référençant un autre tuple ne peut exister si le tuple référencé nexiste pas. Il se peut aussi que tu « quiproquotes » dans la mesure où le modèle relationnel est une théorie, tandis que les merisiens et consorts utilisent lexpression « modèle relationnel » pour les « diagrammes relationnels », mais la notion de diagramme est bien entendu totalement absente du modèle relationnel de Codd.
Envoyé par
Artemus24
Vous pouvez créer des liens de toutes natures, comme lien avant, lien arrière, lien vers parent, lient vers enfants, lien vers début de chaînage, lien vers fin de chaînage, ...
En fait, ce que je vous décris se nomme l'organisation réseau, connue aussi sous le nom IDS II sous bull.
Tu es en train de parler du COMMENT ! Ce qui nous concerne cest le QUOI !
Par exemple, soit les relvars (variables relationnelles) suivantes :
FOURNISSEUR {FournisseurId, FournisseurNom}
PRODUIT {ProduitId, ProduitNom, Couleur, Poids}
LIVRAISON {FournisseurId, ProduitId, Quantite}
Je te laisse le soin de nous traduire en DML IDS II la requête suivante, écrite en ALPHA en 1973 par Chris Date :
RANGE PRODUIT x
RANGE LIVRAISON y
GET RESULTAT (FOURNISSEUR.FournisseurNom) : ∃x∃y(y.FournisseurId = FOURNISSEUR.FournisseurId ∧ y.ProduitId = x.ProduitId ∧ x.Couleur = 'rouge')
En SQL (qui nétait alors quen cours de conception), GET a été renommé en SELECT.
Envoyé par
Artemus24
Mais au niveau performance, on ne fait pas mieux !
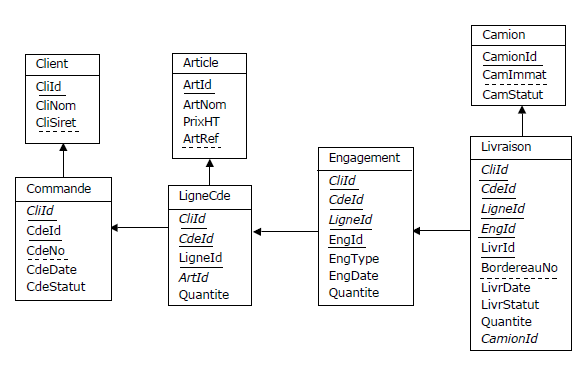
Es-tu à même de le prouver ? Je prends un contre-exemple, celui des camions et les livraisons :
En inversant le sens des flèches par conformité au diagrammes de Bachman :
Supposons que l'on ait besoin de savoir quels camions sont concernés par les livraisons chez le client Gillou (Siret = 12345678900001).
Si en SQL je code :
SELECT DISTINCT Camion.CamImmat
FROM Client JOIN Commande ON Client.CliId = Commande.CliId
JOIN LigneCde ON Commande.CliId = LigneCde.CliId
AND Commande.CdeId = LigneCde.CdeId
JOIN Engagement ON LigneCde.CliId = Engagement.CliId
AND LigneCde.CdeId = Engagement.CdeId
AND LigneCde.LigneId = Engagement.LigneId
JOIN Livraison
ON Engagement.CliId = Livraison.CliId
AND Engagement.CdeId = Livraison.CdeId
AND Engagement.LigneId = Livraison.LigneId
AND Engagement.EngId = Livraison.EngId
JOIN Camion
ON Livraison.CamionId = Camion.CamionId
WHERE CliSiret = '12345678900001' ;
SELECT DISTINCT Camion.CamImmat
FROM Client JOIN Livraison
ON Client.CliId = Livraison.CliId
JOIN Camion
ON Livraison.CamionId = Camion.CamionId
WHERE CliSiret = '12345678900001' ;
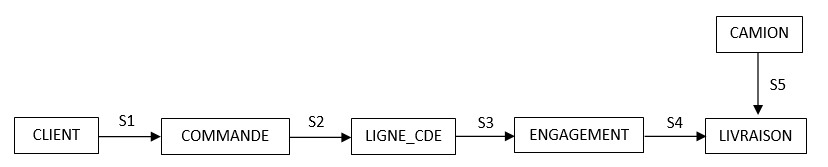
Clairement, prendre ce raccourci spatio-temporel avec un SGBD réseau est évidemment impossible, puisquil faut obligatoirement suivre les pointeurs, via les sets (liens, chemins, mais certainement pas ensembles !  ) S1, S2, S3, S4, S5, bref ça prend du temps ! Je doute que pour leur part, C et C++ sachent transformer le code et prendre le raccourci...
) S1, S2, S3, S4, S5, bref ça prend du temps ! Je doute que pour leur part, C et C++ sachent transformer le code et prendre le raccourci...
Envoyé par
Artemus24
Par exemple, une relation à la fois père vers fils et fils vers père. Dans le modèle relationnelle, cela se nomme un verrou mortel.
Tout faux ! La notion de verrou mortel (étreinte fatale, dead lock) est complètement étrangère au modèle relationnel de données ! Jette un coup doeil ici et cherche « affectation multiple ». Le verrou mortel concerne en fait les transactions :
Un utilisateur U1 met à jour la table A (transaction T1) pendant quun utilisateur U2 met à jour la table B (transaction T2), suite à quoi, dans sa transaction T1, U1 cherche ensuite à mettre à jour la table B pendant quau cours de T2, U2 cherche à mettre à jour à son tour la table A. Le dénouement de cette situation de blocage est SGBD dépendant, mais il y a toujours une victime. Par exemple, en IMS (années 70/80), celui des deux utilisateurs qui a fait le moins de mises à jour est pénalisé (ROLLBACK) et lautre ne lest pas (COMMIT). Pour DB2, je te renvoie aux ouvrages de Gabrielle Wiorkowski (RIP).
Envoyé par
Artemus24
Et donc, on passe à la trappe le CODASYL.
Nuance ! Codd montre seulement que IDMS/R (de feue Cullinet) sest prétendu SGBD relationnel alors quil a obtenu la note 0 sur 12 (comme DATACOM/DB qui avait la même prétention). Forcément, IDMS/R reste un SGBD réseau, ni plus, ni moins...
Et, comme il avait déjà compris quel était le sens de lHistoire, Charles Bachman a mis ses diagrammes au rencart (les fameux diagrammes de Bachman), et mis le voiles de chez Cullinet en 1983 (année de naissance de DB2, tiens, tiens...) pour fonder BACHMAN Information Systems, développer et vendre son produit de migration (re-engineering selon ses propres termes) des SGBD réseau vers les SGBD relationnels SQL...










")
 Répondre avec citation
Répondre avec citation










 de mon aide, vous pouvez cliquer sur
de mon aide, vous pouvez cliquer sur  .
.








Partager