









Bonjour,
dans un champ de ma table Hive, le caractère "" est présent sur certaines lignes :
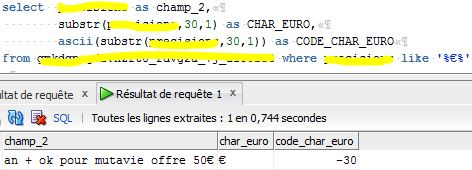
Comme vous pouvez le constater, le code ascii associé à ce caractère est -30. je m'attendais plutôt à avoir 128 (c'est d'ailleurs la première fois que je vois un code ascii négatif et il me semble que c'est incorrect).
La table est définie comme ceci :
Est-ce que quelque chose dans la définition de la table empêche d'interpréter correctement le "" ?
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
Merci d'avance.
 Répondre avec citation
Répondre avec citation
Partager