









Bonsoir,
j'ai besoin d'aide pour faciliter la gestion des différentes branches "version" correspondant à nos différentes versions projets dans mon équipe. Nous traitons au sein de mon équipe (25 développeurs environ) une branche de correction production (que nous appellerons version-n/develop) et 2 versions de développement pour les échéances suivantes que nous nommerons version-n-plus-1/develop et version-n-plus-2/develop. Les branches version-n-plus-1/develop et version-n-plus-2/develop peuvent vivre plusieurs mois car nous ne mettons en production des versions majeures que tous les 6 mois et la production est patchée toutes les 2 semaines à partir de la branche version-n/develop.
Nous rencontrons de grosses difficultés sur les phases de reports de code de la branche maintenance vers les branches projets N+1. Après chaque installation en production, nous reportons les tags associées sur la branche N+1. Pour les reports N+1 vers N+2, nous le faisons en début de sprint de la version N+2 toutes les 3 semaines afin d'éviter une divergence trop difficile à gérer, notamment avec les phases de refactorisation que nous réalisons sur les branches N+1 et N+2.
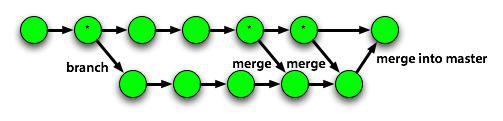
La procédure que nous appliquons pour les reports N vers N+1 (la même entre N+1 et N+2)
- Récupération de la branche version-n-plus-1/develop (git pull)
- Création d'une branche report version-n-plus-1/report/merge-tag-version-n-XXX (git create branch)
- Switch sur la branche créée (git checkout)
- Merge du tag production (git merge tag-version-n-XXX)
- On résout les conflits
- On lance les TU
- On réalise quelques tests manuels
- On fait un pull rebase de la branche version-n-plus-1/develop pour récupérer les éventuels commit produient entre temps.
- On fait un rebase de version-n-plus-1/develop depuis notre branche de report version-n-plus-1/report/merge-tag-version-n-XXX, et là on galère !!! (mot très faible...)
- On merge ensuite sur version-n-plus-1/develop la branche version-n-plus-1/report/merge-tag-version-n-XXX.
- On envoit sur le serveur distant (git push)
Notre procédure est-elle correcte ? Doit-on vraiment faire un rebase à la fin de nos tests après le merge sur la branche de report ? Si ce n'est pas nécessaire, comment devons-nous gérer le cas où il y a eu un commit entre temps sur version-n-plus-1/develop ? En ne faisant pas de rebase, aura-t-on un historique des commits pourri ? Des idées ?
Merci par avance ^^
 Répondre avec citation
Répondre avec citation












Partager