








C'est probable en effetEnvoyé par fsmrel

C'eut été avec plaisir, mais la mission était déjà accomplie
C'est réparé quand même, dans ce fil ce ne sont pas les réponses pertinentes qui manquent")
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter

C'est probable en effet
C'eut été avec plaisir, mais la mission était déjà accomplie
C'est réparé quand même, dans ce fil ce ne sont pas les réponses pertinentes qui manquent







C'est aussi un plaisir pour moi de vous retrouvez sur les forums.
J'ai hâte de pouvoir échanger de nouveau sur des sujets de Théorie Relationnelle et de normalisation.

Bonjour à tous,
Encore merci pour votre aide!
fsmrel, j'ai du mal à voir la différence concrète en base de données des 2 versions que tu proposes la 1) et la 2). Si je peux résumer les liens entre POINT, ELEMENT et PASSAGE en une phrase, la voici: un TECHNICIEN effectue une sortie donc les caractéristiques (date, etc.) sont décrites par PASSAGE, il est positionné sur un POINT (positionné géographiquement), puis comptabilise et positionne les ELEMENTS (donc position géographique aussi). J'espère que ça clarifiera?
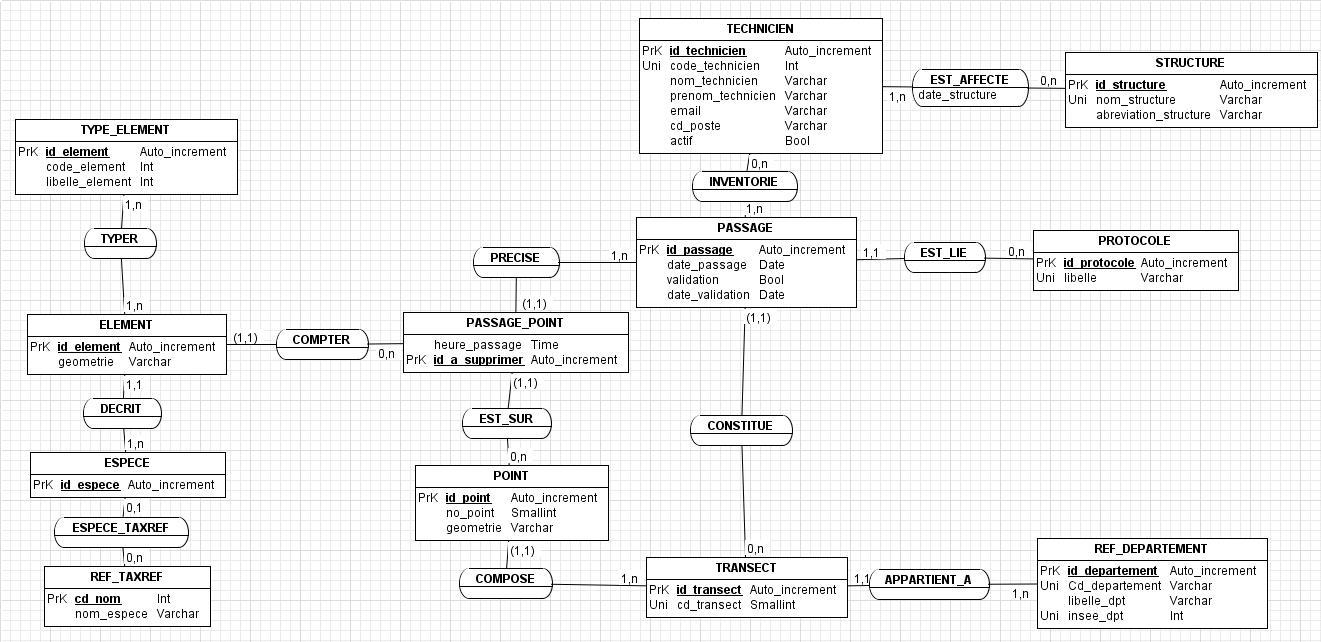
Jai tenté de suivre lexemple de la Société daudiovisuel, mais javais une question, est ce que la personne a utilisé un logiciel ou pas? Car ce nest pas évident de penser à tout! jespère ne pas en avoir trop oublié ci-dessous (sachant que jai tout repris, car auparavant, javais laissé quelques erreur, genre Route et Transect, etc.:
Lobjectif de la base de donnée est de stocker les données issues de suivis floristiques (passés et futurs). La base tourne actuellement sur Access, et lobjectif est de transférer la base sur Postgres/Postgis pour avoir une interface de saisie en ligne.
Au niveau du protocole:
- Cest un échantillonnage qui a lieu en France métropolitaine, où il y a une dizaine de transects par départements en moyenne.
- Un "transect", est "virtuel" et en fait correspond aux 10 points référencés géographiquement et espacés denviron 100m (un groupe de 10 points positionnés le long dune route forestière constitue un transect). Chaque transect a un numéro unique; ex. 123. Tout transect commencé est obligatoirement terminé (un technicien ne peut pas faire juste 3 des 10 points), s'il n'est pas fini, on ne l'enregistre pas.
- Un "point" est un élément du transect et son code est constitué du "numéro de transect"_ "numéro du point (allant de 1 à 10)" ex. 123_1 , 123_2 , 123_3 , , 123_10.
- Un technicien (qui peut être accompagné par 1 ou 2 techniciens) effectue la description d1 à 2 transects par jour par protocole.
- Lors de la description, il parcourt les 10 points les uns à la suite des autres (il n'est pas possible d'en faire 2 en même temps, même s'il y a 2 techniciens) et ils sont soit commencé par le n°1 soit par la n°10, mais jamais dans n'importe quel ordre.
- Sur chacun des points, il dénombre le nombre dindividus par espèces (dans un rayon de 5m) (il y a environ une vingtaine despèces actuellement)
- Pour chaque espèce il définit le nombre de tiges (plantules, arbustes) et le nombre de graines au sol.
- Il y a 4 protocoles (plus ou moins similaires), ce qui fait que le technicien fera le suivi entre 0 et 4 fois par an, en notamment plus ou moins les mêmes choses (suivant les saisons, il y aura des graines ou des feuilles, etc.)
- Pour chacun des passages et/ou années, on applique un filtre pour dénombrer (ou pas) certaines espèces (via une colonne avec des booléens à côté de chaque espèce)
- La date et lheure de description du point est enregistrée.
- Nous aimerions faire évoluer le protocole et que le technicien positionne géographiquement les éléments quil trouve.
Voici les règles de gestion (jespère avoir pensé à tout!):
POINT:
Un point est une localisation, définie par des coordonnées XY où un technicien se positionnera pour faire son relevé.
P_01:Un point est unique, et 10 points composent un TRANSECT
P_02:Un point possède une et une seule geométrie (geom, XY)
P_03: Un point possède un et un seul numéro de point (allant de 1 à 10)
P_04: Un point est composé du numéro de transect et du numéro du point (le nom complet du point pour lutilisateur est composé de la sorte: "numéro_transect" _"numéro_point")
TRANSECT:
Un "transect", est "virtuel" et en fait correspond aux 10 points référencés géographiquement et espacés denviron 100m (un groupe de 10 points positionnés le long dune route forestière constitue un transect). Chaque transect a un numéro unique; ex. 123.
Tout transect commencé est obligatoirement fini: c'est à dire qu'on ne peut pas avoir qu'une partie des 10 points inventoriés, sinon, on ne le considère pas.
T_01: Un transect est unique
T_02: Un transect a un et un seul numéro (entier)
T_03: Un transect est constitué de 10 POINTS
T_04: Un transect est attribué à un et un seul département
PASSAGE ou TOURNEE:
Le passage correspond au moment où le technicien va effectuer le suivi dun TRANSECT (composé de plusieurs POINTs), il y passe 4 fois par an pour 4 protocoles différents et répète cela dannée en année (il peut donc y avoir entre 0 et 4 passages par an par transect).
Pour répondre à fsmrel: Sortie et Passage sont synonymes; Tournée peut aussi convenir. Route est une erreur et correspond à Transect (qui sont situés souvent le long de routes forestières).
Pas_01: Un passage se fait sur au moins un TRANSECT
Pas_02: Un passage est effectué à une et une seule DATE
Pas_03: Un passage est fait par un ou plusieurs Technicien
Pas_04: Un passage est lié à un et un seul protocole
Pas_05: Un passage sera validé (par une personne, Technicien ou autre, dont le nom na pas à être stocké)
Pas_06: Un passage sera validé à une et une seule date
PASSAGE POINT
Le passage point correspond au moment où le technicien se positionne sur un POINT et décrit les plantes.
PasPoint_01: Le Passage Point appartient à un et un seul PASSAGE
PasPoint_02: Le Passage Point est effectué à une et une seule heure
PasPoint_03: Le Passage Point aura zéro ou plusieurs ELEMENTS (plantes)
TECHNICIEN:
Le technicien est la personne qui effectue linventaire. Il est affecté à une structure*; mais il peut changer de structure (passer de lune à lautre), je ne pense pas quil y ai de cas, mais ça pourrais où le technicien appartiennent à une structure au niveau professionnel et une structure au niveau loisir. Dans ce cas, je pense quon ne retiendrais que la structure professionnelle. Idem pour répondre à fsmrel; plusieurs techniciens (en général, seul un est renseigné même si 2 sont présents) peuvent faire ensemble le suivi.
T_01: Un technicien a un code unique composé de 4 chiffres (malheureusement, dans la base historique, une même personne à un ou plusieurs code, un seul sera conservé)
T_02: Un technicien a un et un seul nom
T_03: Un technicien a un et un seul prénom
T_04: Un technicien a zéro ou un email
T_05: Un technicien a zéro ou un numéro de téléphone
T_06: Un technicien a un et un seul code poste (observateur, validateur, administrateur)
T_07: Un technicien peut être actif ou non
T_08: Un technicien appartient à au moins une structure
STRUCTURE:
La structure est lorganisme auquel peut appartenir un technicien (que ce soit au niveau professionnel ou associatif).
ST_01: Une structure a une abréviation (ex. ONF)
ST_02: Une structure a un nom (ex. Office National des Forêts)
ST_03: Une structure peut affecter 0 ou plusieurs techniciens qui sont susceptibles de participer aux suivis floristiques.
ESPECE
Lespèce correspond à lespèce de plante que le technicien inventorie, sachant que le technicien utilise un identifiant propre au protocole et quune espèce a également un code issu dun référentiel national: TaxRef
ES_01: une espèce a identifiant unique définit par léquipe.
ES_02: une espèce a un et un seul code cd_nom (référence nationale TAXREF) (qui permet de déterminer le nom vulgaire, le nom scientifique, etc.)
ES_03: lespèce a un et un seul nom commun français
ES_04: lespère a un et un seul nom latin scientifique
REF_TAXREF:
TaxRef est le référentiel taxonomique français où chaque espèce est référencée et classées. Cela permet notamment davoir les synonymes des noms vulgaires utilisés localement, les traductions, les noms scientifiques, etc.
TR_01: Une espèce a un et un seul Code nom
TR_02: Une espèce peut avoir un ou plusieurs noms français
ELEMENT:
Lélément est ce qui compose et décrit lespèce (graine, tige, feuille, fleur, etc.).
Lors dun passage, il peut ne pas y avoir déléments (sol nu)
EL_01: un élément correspond à une et une seule espèce
EL_02: un élément a au moins un TYPE dELEMENT
EL_03: un élement est caractérisé par une espèce et un type délément
TYPE_ELEMENT
le type délément décrit lélément, ce peut être une graine, une tige, une feuille, etc.
TE_01: le type délément a un et un seul code éléments
TE_02: le type délément sert à typer au moins un élément
REF_DEPARTEMENT:
Le référentiel département est le référentiel standard qui contient le code département, son nom et sa géographie (pas utilisée ici)
DE_01: Un département a un et un seul département
DE_02: Un département a un et un seul code_insee
DE_03: Un département a un seul nom
DE_04: Un département peut contenir de 0 à plusieurs transects.
Voilà, jespère ne rien avoir oublié et avoir été clair.
Ce travail ma notamment permis de voir quil faut que je rajoute dans mon MCD une entité PASSAGE_POINT pour attribuer lheure au point (et non au transect comme je lavais fait) par contre, du coup, les ELEMENTs devront être rattachés à PASSAGE_POINT et non à PASSAGE?
(Jai vu que plusieurs personnes utilisaient DB_MAIN, est-ce que DB_MAIN aide à mettre en place les règles de gestion? Jai vu quil y avait 14 jours dessai, mais vu que le développement de cette base de données nest pas mon activité principale, je narrive pas à libérer suffisamment de temps pour tester la solution (comme vous pouvez le constater dans mes délais de réponse!).
Merci pour votre aide!







Bonsoir Alex,
Bel effort ! Bien utile, mais jaurai évidemment quelques remarques à faire...
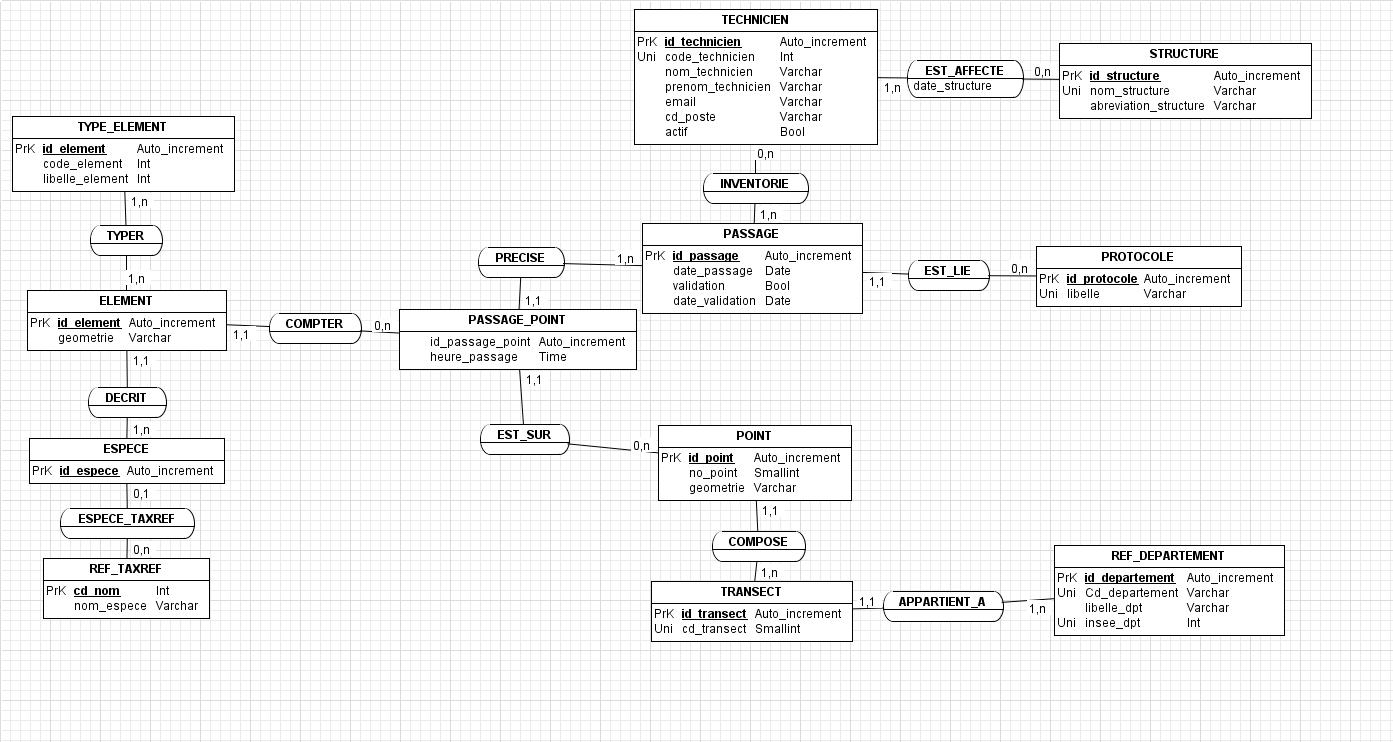
Je suppose quil sagit non pas du MCD du post #2, mais des deux versions figurant dans le post #13. Cest cela ?
Supposons que ça ce soit le cas :
Version 1
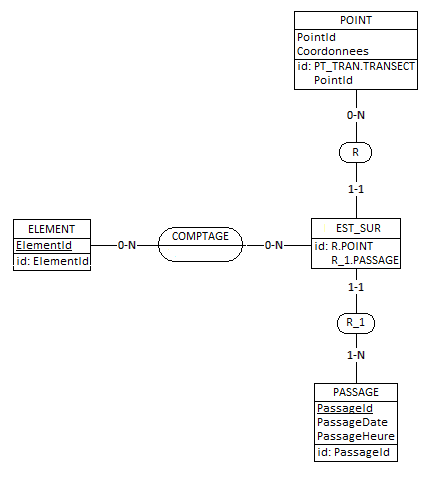
Dans ce 1er cas, un passage PA1 fait référence à plusieurs points, par exemple PT1, PT2, PT3 : les comptages sont effectués pour chacune des paires <PA1, PT1>, <PA1, PT2>, <PA1, PT3>.
Version2
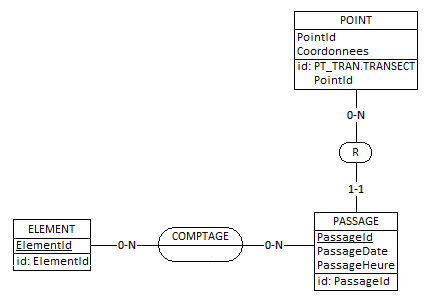
Dans ce 2e cas, le passage PA1 fait référence à un et un seul point, par exemple PT1 : les comptages sont effectués pour ce seul passage.
Les phrases sont toujours sujettes à interprétations diverses, ça reste le cas ici. Bien que le MCD aille dans le sens de la version 1, on pourrait très bien interpréter la phrase qui précède dans le contexte de la version 2, c'est-à-dire la façon suivante :
(a) Le technicien TE1 effectue le passage PA1 au (seul) point PT1 à la date D1 et à lheure H1.
(b) Au moment de son passage PA1, le technicien compte les éléments et les positionne.
Question annexe : indépendamment de ce qui est représenté dans le MCD, positionner les éléments signifie-t-il positionner un ensemble déléments ? Sinon, chaque élément compté a-t-il ses propres coordonnées, distinctes de celles de son voisin (mais incluses dans celles du point PT1 (au passage PA1)) ?
Du point de vue de la modélisation, ce système didentification des points est bien propre à lutilisateur, il sagira donc dun identifiant alternatif, « secondaire » pour lentité-type POINT. Par référence à votre MCD, Lidentifiant principal sera constitué du singleton {id_point}, ou mieux, en utilisant lidentification relative, cet identifiant sera constitué de la paire {COMPOSE, id_point}. ON aura à reparler de cela.
Euh... Merci de compléter
Dans lapproche MCD, Il va falloir remettre à plat cette partie, c'est-à-dire voir très précisément quelles entités-types et associations et attributs sont parties prenantes.
Vous écrivez quil peut y avoir entre 0 et 4 passages par an par transect, il y a donc une relation forte entre un passage et un transect. Ceci napparaît pas sur votre MCD, on doit donc sappuyer sur lentité-type POINT et les associations EST_SUR et COMPOSE pour inférer cette relation. On aura à creuser cette partie.
Autres remarques
Il faudrait compléter les règles de gestion des données concernant lentité-type PASSAGE_POINT. en effet, selon votre MCD, un passage point donné « décrit » au moins un point, au plus plusieurs. Ça fait bizarre, quelque chose méchappe. Quen est-il ? Par ailleurs, les entités-types POINT, PASSAGE, PASSAGE_POINT en conjugaison avec les associations EST_SUR, décrit et est_associe constituent un cycle, et cest quelque chose de redoutable, on devra aussi reparler de cela.
Selon votre MCD, un élément est compté une fois et une seule dans sa vie, il a une seule géométrie et comporte un nombre déléments : il y quelque chose qui cloche... Jai limpression quil y a mélange entre lélément au sens général (association dune espèce et dun type) et au sens particulier (tel élément localisé à tel endroit).
A mettre à plat. Les règles de gestion des données concernant les éléments sont à mieux préciser.
Je nai pas la réponse, vous lui poserez la question.
Cest à vous de produire un MCD (entités-types, associations, cardinalités portées par les pattes dassociation, spécialisation/généralisation des entités-types, contraintes). Comme les AGL traditionnels utilisés pour réaliser des MCD ou des MLD, DB-MAIN ne fait quacter votre MCD, le valider, et vous permet de produire automatiquement le code SQL de description des tables. Pour produire un MCD à partir de phrases en français, je ne sais pas ce qui existe sur le marché. Par le passé, jai utilisé SECSI (Système Expert en Conception des Système dInformation), enfant du professeur Bouzeghoub, mais SECSI était évidemment payant.
Ces 14 jours dessai concerne DATABOOK (dont jignorais jusquici lexistence !) Quant à lui, DB-MAIN est gratuit, simplement il faut ouvrir un compte pour obtenir une licence (à renouveler chaque année).
Je répète, vous avez fait un très el effort quant aux règles de gestion des données, mais certaines (et pas des plus évidentes) sont restées sous le tapis...
Gardons nos manches retroussées
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Bonjour,
Merci pour la réponse détaillée.
Oui, il s'agit bien de cette version je pense que c'est celle qui correspond le mieux... par contre, je ne connaissais pas l'option utilisant l'entité "est_sur".
Non, positionner les éléments correspond à positionner géographique chacun des éléments, élément par élément. donc en effet, chaque élément compté a ses propres coordonnées distinctes mais incluse dans celles du point PT1.
En effet, le système de codification actuel est utilisateur et j'avais prévu d'utiliser un code propre à la base de donnée. Je ne connais pas le {COMPOSE, id_point}
En fait les protocoles sont quasiment les mêmes (actuellement ils sont séparés dans la base Access car ils ont été ajoutés avec les années... mais vu que les données sont à 90% similaire, je vais faire qu'une base de données. En fait, ce qui change, c'est que vu que les relevés se font à des périodes de l'année différente, les éléments sont différents (ex. fleur, graine, ou tige) ne sont pas les même mais tout le reste est pareil.
Je ne vois pas comment le mettre plus en évidence que la relation entre passage et transect est "forte".
J'ai modifié le MCD, en effet, PASSAGE_POINT peut avoir un et un seul POINT par contre un POINT peut avoir plusieurs PASSAGE_POINT.
En effet, il restait quelque chose d'une vieille version.
Ok, merci, je pensais qu'il y avoir des outils qui pouvaient plus accompagner...
Voilà, j'ai refais un MCD avec les différentes remarques, j'espère que c'est un peu plus cohérent?
Merci en tout cas pour l'aide.
Bonne fin de journée
Bonsoir Alex,
Dans tout ce qui suit, ne tenez pas compte des valeurs que jai affectées aux attributs identifiants id_passage, id_technicien, etc., elles sont purement symboliques, ce sont des mickeys (PA1, PA2, TE1 TE2, etc.)
Entité-type PASSAGE
Je reviens sur :
Je remets encore à plus tard mes commentaires concernant les éléments.
Ce que je retiens de PASSAGE : les dates de passage (attribut date_passage) seraient prévues à lavance par qui de droit, avant même quon sache que tel technicien sera partie prenante pour la date de passage dun passage donné. Quen est-il ?
Pour le moment, je vois ainsi les choses au niveau tabulaire :
PASSAGE {id_passage, date_passage, validation, date_validation, id_protocole} PA1 2011-03-03 vrai 2011-03-10 PR1 PA2 2011-06-02 vrai 2011-06-09 PR1 PA3 2011-09-08 vrai 2011-09-22 PR2 PA4 2011-11-15 vrai 2011-11-29 PR1 PA5 2011-03-22 vrai 2011-03-29 PR3 PA6 2011-05-09 vrai 2011-05-16 PR4 PA7 2011-09-01 vrai 2011-09-15 PR1 PA8 2012-03-10 vrai 2012-03-24 PR3 PA9 2012-06-21 vrai 2012-06-28 PR2 PA10 2012-09-05 vrai 2012-09-19 PR3 PA11 2012-11-13 vrai 2012-03-20 PR4 PA702 2017-03-16 vrai 2017-03-23 PR2 PA703 2017-05-10 vrai 2017-05-24 PR4 PA704 2017-09-12 vrai 2017-09-19 PR1
En passant, je note la présence dun attribut validation et dun attribut date_validation dans len-tête (liste des attributs) de lentité-type PASSAGE. Lattribut validation est du type booléen : les combinaisons suivantes sont-elles toutes légales ?
validation = faux et date_validation non renseigné
validation = faux et date_validation renseigné
validation = vrai et date_validation non renseigné
validation = vrai et date_validation renseigné
Association INVENTORIE
En létat, votre MCD permet de savoir quel ensemble de techniciens sest positionné sur tel point (cf. en lespèce lentité-type PASSAGE_POINT). On a la connaissance de cet ensemble grâce à lassociation INVENTORIE qui recense les paires {TECHNICIEN, PASSAGE}, donc les techniciens parties prenantes dans tel passage. Exemple :
Cette représentation en extension est conforme à la règle de gestion des données, quand vous écrivez :INVENTORIE {id_passage, id_technicien} PA1 TE1 PA1 TE2 PA1 TE3 PA2 TE1 PA2 TE3 PA2 TE4 ... ...
« pour répondre à fsmrel; plusieurs techniciens (en général, seul un est renseigné même si 2 sont présents) peuvent faire ensemble le suivi. »
En effet si « en général seul un est renseigné », il nest manifestement pas interdit que la triplette TE1, TE2, TE3 puisse inventorier le passage PA1. Mais parmi ces 3 techniciens, y en a-t-il un quil faudrait marquer comme étant le principal concerné ?
Entité-type PASSAGE_POINT
PASSAGE_POINT est une entité-type dun genre particulier, elle dite entité-type associative ; cest une association quon déguise en entité-type parce quen Merise traditionnel il est interdit dassocier une association à quoi que ce soit (cette interdiction dogmatique a été levée en 1993 dans OOM (Orientation Objet dans Merise), mais ça na pas été suivi deffet...
Qui dit entité-type associative, dit héritage implicite des identifiants : PASSAGE_POINT hérite des identifiants de PASSAGE et de POINT. Dans le cas de JMerise, pour aboutir à cela, il faut utiliser un lien relatif, dune part pour la patte dassociation connectant PASSAGE_POINT et PRECISE, et dautre part pour la patte dassociation connectant PASSAGE_POINT et EST_SUR :
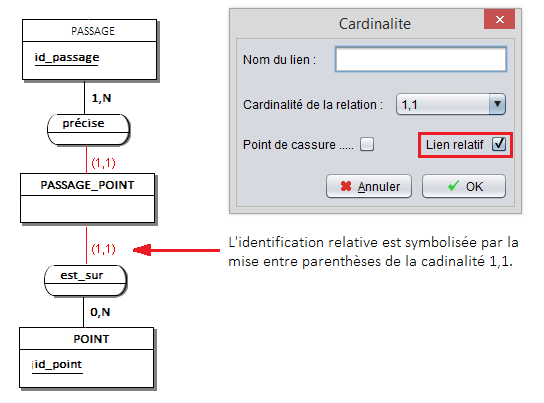
Au stade SQL, la table PASSAGE_POINT sera automatiquement dotée des colonnes id_passage et id_point, avec pour clé primaire la paire {id_passage, id_point}. Maintenant, si dans le temps le point PT1 et le passage PA1 peuvent être associés plus dune fois, alors votre attribut id_passage_point permettra cette association multiple :
Incidemment, comme jen ai déjà parlé, lidentification relative joue pour la relation entre les entités-types TRANSECT et POINT, car cette fois-ci POINT est une caractéristique de TRANSECT, c'est-à-dire quun point est une propriété intrinsèque dun transect, un point ne peut pas changer de transect :PASSAGE_POINT {id_point, id_passage, id_passage_point} PT1 PA1 1 PT1 PA1 2 PT1 PA1 3
.png)
Lidentification relative permet daborder la prise en compte de la contrainte suivante :
Si le point <PT1> appartient au transect <TR1> et si le passage <PA1> est constitutif de ce transect <TR1>, alors le passage-point <PT1, PA1> ne peut faire référence quà un seul transect, à savoir <TR1>.
Exemple de MCD permettant daborder la prise en compte de la contrainte (pour varier les plaisirs, jutilise PowerAMC) :
.png)
En tant que tel, ce MCD ne permet pas de garantir la contrainte (à moins de faire figurer une contrainte dinclusion qui obscurcirait le diagramme...) Toutefois, du fait de lidentification relative, les entités-types PASSAGE et POINT héritent toutes les deux de lidentifiant de TRANSECT, à savoir id_transect :
PASSAGE a pour identifiant non pas {id_passage}, mais {id_transect, id_passage}
POINT a pour identifiant non pas {id_point}, mais {id_transect, id_point}
Du fait de lidentification relative, PASSAGE_POINT hérite de lidentifiant de PASSAGE et de celui de POINT, en conséquence de quoi son identifiant ne se réduit pas à {id_passage_point} mais est le suivant :
{id_transect, id_point, id_transect2, id_passage, id_passage_point}
Où id_transect figure deux fois, ce qui permet de rattacher un passage-point à deux transects distincts, aïe !
Mais, au stade MLD, il suffit de supprimer manuellement id_transect2, ce qui fait que chaque tuple de PASSAGE_POINT fait référence à un transect unique, et la contrainte dunicité est assurée :
.png)
La table SQL PASSAGE_POINT a bien pour clé primaire le quadruplet :
{id_transect, id_point, id_passage, id_passage_point}
Elle possède deux clés étrangères :
fk1 = {id_transect, id_point}
fk2 = {id_transect, id_passage}
faisant respectivement référence à la clé primaire de POINT et à celle de PASSAGE.
A suivre...
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Ah ! J'oubliai !
Oui ! Mais on regardera de plus près le cas des éléments...
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Normalement, le technicien et la date sont liés; s'il n'y a pas de relevé, il n'y a ni date ni technicien, et s'il y a un relevé, il y a forcément une date et un technicien.
En effet, la table qui est proposé comme exemple correspond bien.
Au niveau validation, si la validation est vrai, elle devra forcément être accompagnée d'une date... par contre, si elle est fausse, elle peut ne pas avoir de date (même si c'est à éviter, mais dans la base historique, on a quelques cas). Cela signifie donc qu'il faut séparer les entités?
Non, il n'y a pas forcément de principal... l'essentiel est qu'il y ai au moins un nom associé au passage.
whaou, je découvre cette fonctionnalité, donc ça évite d'avoir une boucle si je comprend bien...
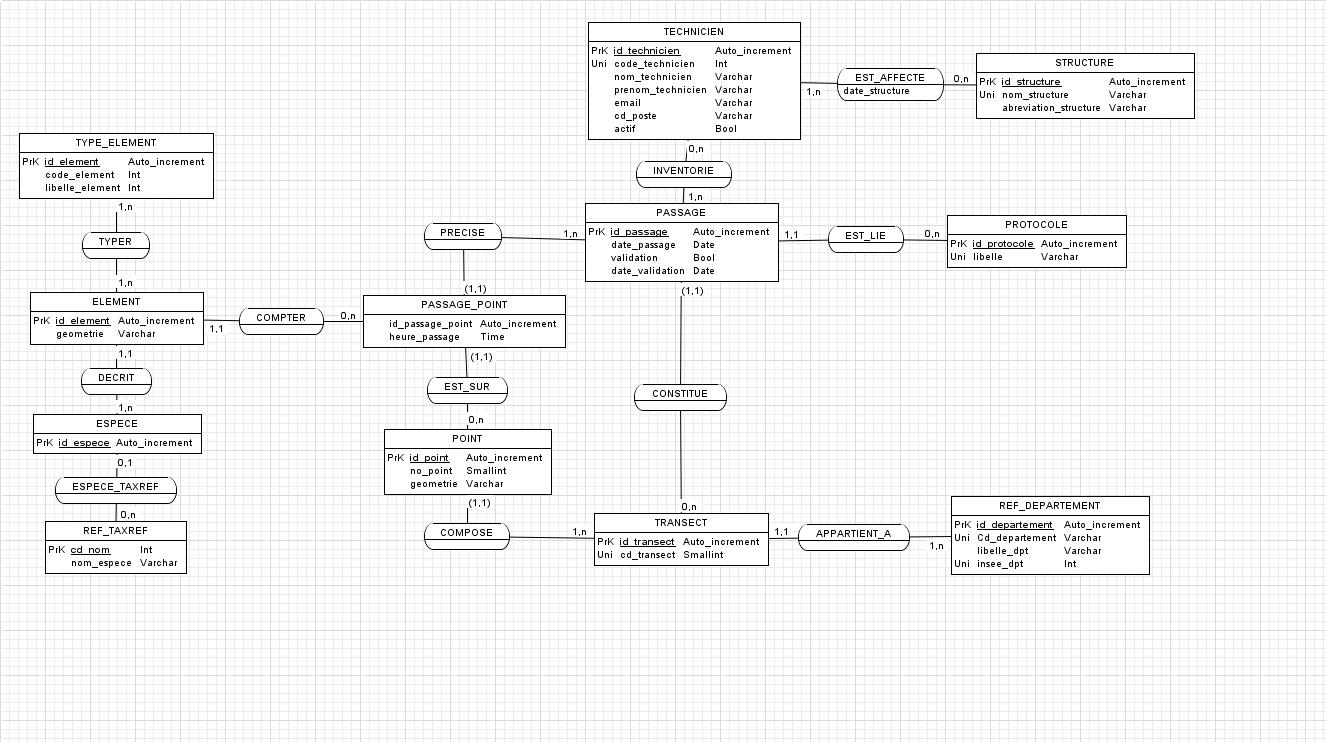
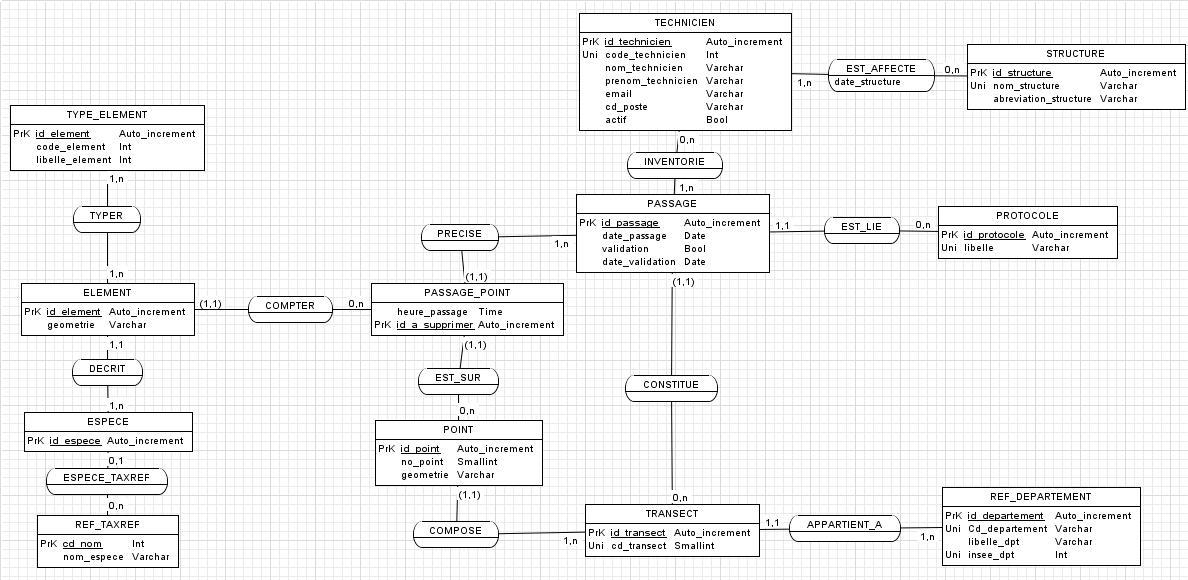
Du coup, si je tiens compte des différentes remarques, le MCD ressemblerait à ça:
Sur le MCD, on ne le voit pas le id_transect2? ou c'est quelque chose d'implicite?
Bonsoir Alex,
Jai modifié mon message précédent, en y soulignant dans les tableaux dexemples les attributs constitutifs des identifiants.
Je note que les termes RELEVÉ et PASSAGE_POINT ont tout lair dêtre synonymes, interchangeables. Est-ce vrai ?
Selon votre dernier MCD, lattribut id_passage_point de lentité-type PASSAGE_POINT ne participe plus à lidentifiant de celle-ci. Dans ces conditions, pour reprendre la représentation tabulaire que javais proposée (je souligne les attributs constitutifs de lidentifiant) :
Alors cette représentation nest plus valide, car lidentifiant de PASSAGE_POINT étant maintenant réduit à la paire {id_point, id_passage}, il sensuit que la valeur <PT1, PA1> ne peut plus être présente quune seule fois au lieu de trois (qui plus est, lattribut id_passage_point est rendu inutile). La représentation est donc nécessairement réduite à :PASSAGE_POINT {id_point, id_passage, id_passage_point, heure_passage} PT1 PA1 1 HE1 PT1 PA1 2 HE2 PT1 PA1 3 HE3
Quen est-il finalement de la participation de lattribut id_passage_point à lidentifiant de PASSAGE_POINT, quel tableau est correct ?PASSAGE_POINT {id_point, id_passage, heure_passage} PT1 PA1 HE1
Donc ce que jai écrit serait infirmé, un passage ne peut exister a priori, on doit savoir quel technicien est affecté à tout passage.
Je reprends cette partie :
« S'il n'y a pas de relevé, il n'y a ni date ni technicien »
Absence de relevé veut dire absence de linformation correspondante en ce qui concerne lentité-type PASSAGE_POINT. Cela veut dire aussi absence dinformation quant à la date de passage (entité-type PASSAGE, attribut date_passage), donc absence de linformation correspondante en ce qui concerne lentité-type PASSAGE.
Pour quil y ait présence de linformation (PASSAGE, PASSAGE_POINT), il faut quil y ait un technicien dans le coup (cest en tout cas le sens des cardinalités 1,N portées par les pattes dassociation connectant dune part PASSAGE et INVENTORIE et dautre part PASSAGE et PRECISE).
Suis-je clair, suis-je en phase ? Sil faut approfondir, allons-y, nattendons pas que la base soit en production !
Si je comprends bien, dun point de vue fonctionnel, lattribut date_validation doit toujours être valorisé. La modélisation ne doit pas tenir compte des scories polluant la base historique. Lors du passage à la nouvelle base, vous serez amené à fournir une date « bidon » quand celle-ci est absente dans lancienne, du genre 31-12-9999 ou autre bidouille...
Vous parlez de séparer les entités-types : quentendez-vous par cela ?
Lattribut id_transect2 est implicite au stade MCD, cest ce que veut dire la mise entre parenthèses de la cardinalité 1,1 symbolisant ainsi lidentification relative. Cest au moment du passage au MLD que lAGL génère les colonnes (attributs) id_transect et id_transect2 (ou tout autre nom à son gré) pour la table PASSAGE_POINT. Si jai le temps, je regarderai comment JMerise se comporte en loccurrence.
Graphiquement, la boucle est toujours présente, mais la technique de lidentification relative « bouclée » permet den éviter les effet pervers, à condition de supprimer manuellement les attributs tels que id_transect2 (et ajuster la clé étrangère fk2 en conséquence). Dans le jargon merisien, on dit encore quon a mis en uvre une contrainte de chemin (forestier, dans votre cas !)
Pour tout ce dont nous avons débattu, cest daccord. En ce qui concerne le MLD, il faudra voir ce que produit JMerise. Sil y a trop de corrections à apporter, on pourra éventuellement effectuer une rétro-conception avec MySQL Workbench pour pouvoir générer des déclarations de tables SQL correctes.
Vérifiez aussi (dans le contexte JMerise) que la case « Null » est décochée, pour chaque attribut de chaque entité-type de votre MCD, sinon, par voie de conséquence, il pourrait se produire des cas perturbants en production, à limage de ce qui se passe avec la date de validation dans votre base historique...
En attendant votre prochain message, dès que jaurai un peu de temps, je regarderai du côté des éléments.
P.-S. Quand un message a pu vous apporter de l'aide, n'hésitez pas à le plusser, merci !
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
En effet, je ne me rends pas compte que les termes peuvent apporter à confusion. En fait, un RELEVE correspond au moment où le technicien sort sur le terrain et note ce qu'il voit. donc oui c'est synonyme avec PASSAGE_POINT.
En effet, il est vraiment que d'après le 1er tableau, id_passage_point fait répétition! Le 2nd tableau est correct.
La cardinalité 1,n entre PASSAGE et INVENTORIE correspond pour moi à: Un PASSAGE est inventorié par un ou n TECHNICIENs. et dans l'autre sens, un TECHNICIEN peut faire 0 ou plusieurs PASSAGE. Donc ça correspond bien au MCD que j'ai proposé non?
Mais en effet, s'il n'y a pas de passage, il n'y a pas de TECHNICIEN puisque le PASSAGE est fait par un ou plusieurs techniciens.
En effet, c'est ce que je pensais faire, ou mettre une date NULL.
Je voulais dire "entité-type associative"
Je pourrais poster le MLD généré par JMerise si vous pensez que le MCD semble correct (ou cohérent)?
Ok je vais vérifier, idem que pour le MLD, je posterais le MLD et le code SQL généré pour avoir vos retours et conseils, (mais déjà les différents MCD font une discussion super longue!).
Mais ils m'aident énormément! donc merci pour le rappel! ;-)
Bonsoir Alex,
La confusion nous guette dans chaque discussion, que ce soit chez DVP ou, sur le terrain, dans les réunions de travail avec les utilisateurs... Doù la nécessité dêtre très vigilant quant à la terminologie, ça na pas lair, mais dans cette affaire mieux vaut assurer : ceinture, bretelles et épingle à nourrice...
Si dans la même réunion de travail nos interlocuteurs sont des banquiers, des chimistes, des cheminots et des libraires, quand je prononce le mot « titre », le sens leur est évident dans leur propre univers, mais sorti de là, gare aux quiproquos ! On va déraper... Je pense quEscartefigue et Oishiiii seront de cet avis...
Daccord. Lattribut id_passage_point na plus de raison dêtre, il disparaît. La partie correspondante du MCD devient :
.png)
Et celle du MLD :
.png)
Oui, ça correspond.
En réalité, cest cette partie sur laquelle jattire lattention. En effet, si au stade du MCD tout va bien, au stade du code SQL rien ne garantit que la cardinalité 1,n entre PASSAGE et INVENTORIE sera respectée. Exemple :
Dans cette situation, le passage TR1 existe, mais sans technicien pour faire les relevés. Pour empêcher cela, il sera prudent de mettre en uvre le trigger PostgreSQL qui va bien, exercice pas trivial, voyez la discussion avec delarita (encore lui !) à partir disons du post #60.TECHNICIEN {id_technicien, nom_technicien, ...} TE1 Fernand TE2 Raoul TE3 Paul TE4 Antoine TE5 Pascal ... ... PASSAGE {id_transect, id_passage, date_passage, ...} TR1 1 2011-03-03 TR2 1 2011-09-08 INVENTORIE {id_transect, id_passage, id_technicien} TR2 1 TE4 TR2 1 TE5
Le bonhomme NULL ayant la fâcheuse habitude de ficher la patouille, je verrais plutôt une valeur du genre de celle que jai prise en exemple.
Hum... Seule lentité-type PASSAGE_POINT est associative, c'est-à-dire que PASSAGE_POINT est une association quon a déguisée en entité-type. POINT est une entité-type faible, non autonome, du point de vue de la modélisation elle na de sens que comme propriété multivaluée de TRANSECT, qui est à considérer comme étant une entité-type forte.
Cela dit, puisque lattribut date_validation sera toujours valorisé, il ny a plus dentités-types à séparer...
Daccord. On y arrivera, mais on aura du boulot pour remettre le code SQL déquerre...
Jai regardé du côté des éléments, jai des questions, mais pour ne pas tout mélanger, je préfère les poser dans un message à venir.
Courage !
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Il y a comme une contradiction entre les deux règles. Quand vous dites quun élément est caractérisé par une espèce et un type délément, on comprend : un élément est caractérisé par une et une seule espèce et un et un seul type délément.
Cela dit, selon votre MCD, un élément est typé par au moins un type délément : quelle est la finalité de cette pluralité ? Comment décider du type à retenir pour un élément donné ? En ce sens, il serait bien dexpliciter la règle de gestion EL02.
Si un élément est graine à la date D1 et que cette graine est devenue arbuste (donc tige) à la date D2, même si on était capable de se rendre compte de cette « métamorphose », on considère quil sagit de deux éléments distincts, cest bien cela ?
Si les éléments EL1, EL2, ..., ELn, sont de la même espèce, du même type, et géographiquement tout proches les uns des autres (même géométrie), vous aurez donc n occurrences ayant exactement la même valeur (à celle de lidentifiant près !) Why not, mais on peut se poser des questions quant à la mise en uvre dun attribut de comptage. Avez-vous rencontré des difficultés à ce propos ?
Cela me rappelle lhistoire du « Saint-Lazare - Pont-Cardinet » : Les choses se passaient en 1993-1994. Auparavant, les concepteurs du projet A* (à la SNCF) avaient prévu que chaque titre de transport (~ billet) ferait lobjet dune ligne dans la table SQL ad-hoc. Supposons que lon compte à cette époque tant de titres par jour pour le trajet parisien Saint-Lazare - Pont-Cardinet, même chose pour les trajets Saint-Lazare - autres stations, et tous les trajets des trains de banlieue en France (pas que de banlieue du reste, cas par exemple de Mimizan ville - Mimizan plage), non seulement ça commençait à occuper beaucoup de place sur disque, mais surtout le temps de stockage dans la base de données devenait rédhibitoire et il fallait le réduire à tout prix. La solution ? En gros, un seul titre « Saint-Lazare - Pont-Cardinet » par jour, comportant en fait le nombre réel de titres (et il y eut des réticences face à une solution aussi évidente !) Le temps de stockage devint enfin celui qui était attendu.
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
En effet, un élément n'a forcément qu'une seule espèce. Par contre, un élément peut avoir au moins TYPE_ELEMENT: ex. une plantule peut avoir une tige et une fleure. Mais s'il n'y a pas de TYPE_ELEMENT (donc ni fleur, ni tige, ni fruit,...) on ne peut pas identifier l'espèce donc considérée comme non présente.
C'est exactement cela. Lors des passages, on ne regarde pas l'historique. Au niveau des analyses qui sont faites après, seul le nombre déléments et les espèces par POINT ou TRANSECT sont analysées. Donc une graine aujourd'hui qui sera une plante (de la même espèce) au prochain PASSAGE seront certainement positionnées au même emplacement, mais il n'y aura pas de lien entre eux. Sachant que je rappelle qu'actuellement, il n'y avait pas moyen de positionner les ELEMENTs donc aucun moyen de savoir si c'était les même individus entre chaque PASSAGE. Peut-être que dans quelques années ça évoluera avec l'apport du positionnement géographique des ELEMENTs, mais ça fera l'objet d'une nouvelle version.
En effet! je n'avais pas voulu étendre aussi loin... mais en effet, il y a ce point que nous avions identifié. Majoritairement, les ELEMENTs sont positionnables individus par individus, mais il est vrai qu'on a déjà eu des cas où il y avait plein de plants ou graines regroupés. Pour ces cas là, je ne voyais pas comment faire, et j'ai laissé ça de côté pour l'instant, mais en effet, c'est un point à penser (c'est d'ailleurs pour cela que dans mes 1ères versions, j'avais mis "effectif" avec un entier pour dénombrer directement les groupes d'individus.
Si vous avez des idées ou propositions, je suis preneur!
Et encore un énorme merci!
Bonsoir Alex,
On progresse !
Daccord. Votre exemple aide parfaitement à la compréhension. Le nom de lassociation TYPER mavait fait dériver vers une relation de typage (élément hybride) alors quil sagit plutôt dune relation de composition (comme quoi un bon exemple permet déliminer les erreurs dinterprétation et les ambiguïtés...)
On est un peu dans logique du « Saint-Lazare - Pont-Cardinet ». Si le technicien relève la présence de 50 éléments strictement identiques, a priori il va devoir effectuer 50 opérations de saisie, totalement redondantes. Sil neffectue quune seule opération, et fournit la valeur 50 (attribut nombre_element de votre MCD dans le post #23), la table ELEMENT ne comportera quune ligne pour cette opération au lieu de 50 ; le technicien ira 50 fois plus vite pour la saisie et la table sera moins volumineuse. Même en admettant que nombre_element vaille le plus souvent 1, totaliser pour un point ou un transect ne compliquera pas particulièrement la requête SQL correspondante : en gros, au lieu deffectuer un COUNT, ça sera un SUM (en notant que les colonnes id_transect et id_point figureront de facto dans len-tête de la table ELEMENT, clé étrangère oblige)...
Non pas pour des raisons dordre sémantique, mais de performance de la base de données cette fois-ci, il serait opportun didentifier ELEMENT relativement à PASSAGE_POINT :
[ELEMENT]--(1,1)-----(COMPTER)-----0,N--[PASSAGE_POINT]
Lidentification relative est pas ici strictement nécessaire, mais au stade SQL on doit se préoccuper de la performance de la base de données ; cela peut avoir un impact sur le MCD, mais bien mineur (ajout de parenthèses encadrant la cardinalité 1,1...)
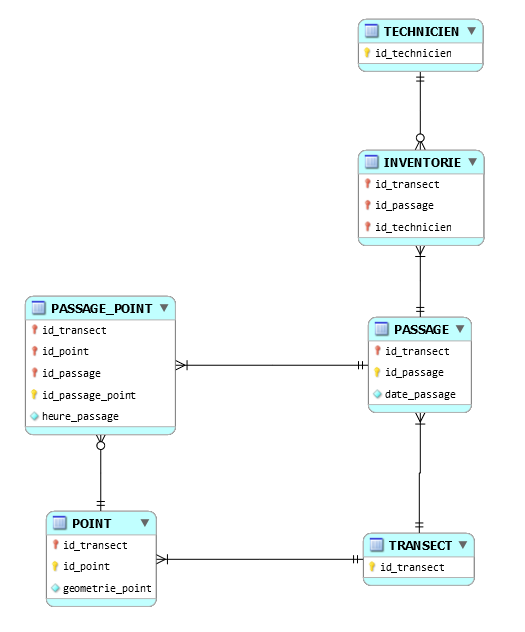
Jai regardé ce que produit JMerise.
Voici ce quil propose comme MLD dérivé du cur du MCD :
mld.png)
Avec la version de JMerise dont je dispose (la 0.4.0.1), on ne peut malheureusement pas modifier ce MLD...
Dommage, car pour garantir la contrainte de chemin (cf. le post #29), il faut supprimer lattribut id_transect_TRANSECT de la table PASSAGE_POINT (le fameux attribut id_transect2, cf. les posts #26, #28, #29).
De même en ce qui concerne lordre des attributs dans les clés primaires : tel Dagobert, JMerise la mis à lenvers pour les tables PASSAGE, POINT, PASSAGE_POINT, INVENTORIE : id_transect doit impérativement figurer en tête (au moins pour les trois premières).
Il faudra donc quon tripatouille le code SQL de génération de la structure des tables, avec envoi à la poubelle des instructions ALTER TABLE produites pour les clés étrangères : en loccurrence JMerise produit nimporte quoi (non référence aux bonnes tables, clés étrangères incomplètes...)
Mais comme il y a peu de tables, les réparations devraient aller assez vite.
JMerise vous a permis de produire des MCD, mais pour éviter davoir à reprendre tout le code SQL suite à une modification du MCD, autant utiliser DB-MAIN ou MySQL Workbench (lequel se situe plutôt au niveau MLD), que jai mentionnés dans le post #2.
Exemple avec MySQL Workbench :
Postez votre code SQL, on mettra les mains dan le cambouis...
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Donc en ajoutant cette identification relative, il serait à la fois possible de mettre 1 ELEMENT tout aussi facilement que 50 ELEMENTs?
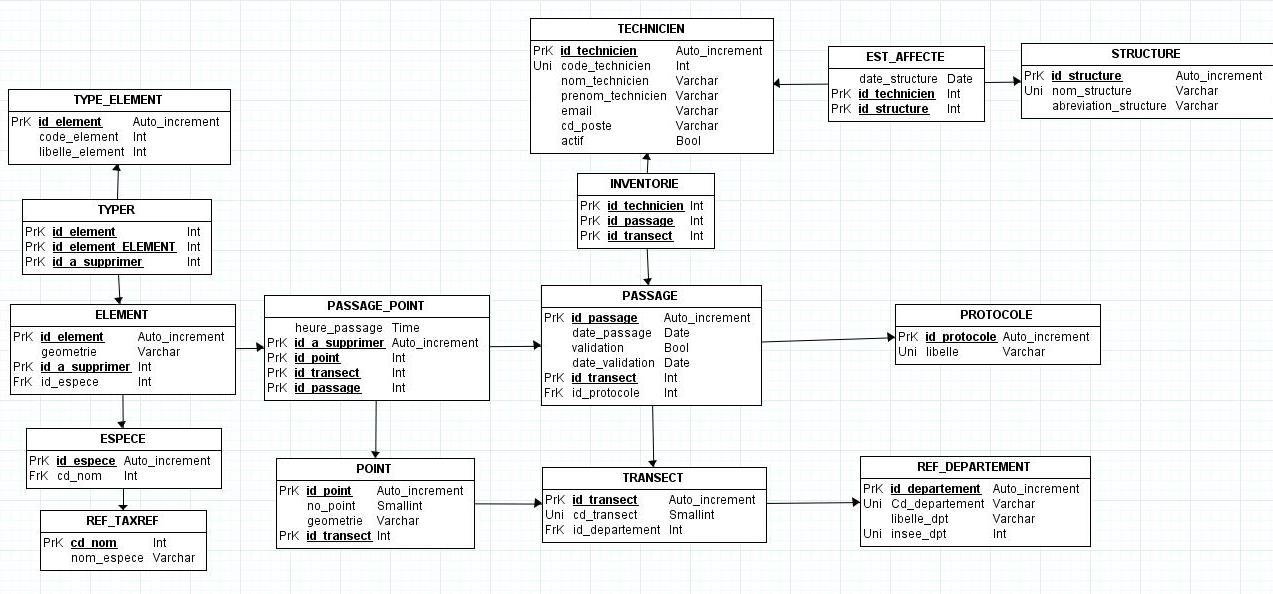
Pour JMerise, en effet, si je demande la vérification du MCD, j'aiDu coup, j'ai ajouté une clé primaire: "id_a_supprimer"Lien relatif : l'entite "PASSAGE_POINT" ne contient pas de clé primaire
ERREUR : Le MCD est incorrect
Voici (généré par JMerise) donc le MCD
Le MLD
et le Code SQL:
Concernant le logiciel à utiliser, j'ai testé BD_MAIN, mais ce que je trouve dommage c'est que le format des champs (varchar, etc.) n'apparait pas forcément. J'ai aussi regardé mysql workbench, mais vu que je travaille avec Postgresql et son extension spatiale postgis, c'est pas tout à fait le même language.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217#------------------------------------------------------------ # Script MySQL. #------------------------------------------------------------ #------------------------------------------------------------ # Table: TECHNICIEN #------------------------------------------------------------ CREATE TABLE TECHNICIEN( id_technicien int (11) Auto_increment NOT NULL , code_technicien Int , nom_technicien Varchar (50) NOT NULL , prenom_technicien Varchar (50) NOT NULL , email Varchar (25) , cd_poste Varchar (50) NOT NULL , actif Bool , PRIMARY KEY (id_technicien ) , UNIQUE (code_technicien ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: STRUCTURE #------------------------------------------------------------ CREATE TABLE STRUCTURE( id_structure int (11) Auto_increment NOT NULL , nom_structure Varchar (100) NOT NULL , abreviation_structure Varchar (25) , PRIMARY KEY (id_structure ) , UNIQUE (nom_structure ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: POINT #------------------------------------------------------------ CREATE TABLE POINT( id_point int (11) Auto_increment NOT NULL , no_point Smallint NOT NULL , geometrie Varchar (25) , id_transect Int NOT NULL , PRIMARY KEY (id_point ,id_transect ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: TRANSECT #------------------------------------------------------------ CREATE TABLE TRANSECT( id_transect int (11) Auto_increment NOT NULL , cd_transect Smallint NOT NULL , id_departement Int , PRIMARY KEY (id_transect ) , UNIQUE (cd_transect ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: REF_TAXREF #------------------------------------------------------------ CREATE TABLE REF_TAXREF( cd_nom Int NOT NULL , nom_espece Varchar (50) NOT NULL , PRIMARY KEY (cd_nom ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: ESPECE #------------------------------------------------------------ CREATE TABLE ESPECE( id_espece int (11) Auto_increment NOT NULL , cd_nom Int NOT NULL , PRIMARY KEY (id_espece ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: PASSAGE #------------------------------------------------------------ CREATE TABLE PASSAGE( id_passage int (11) Auto_increment NOT NULL , date_passage Date , validation Bool , date_validation Date , id_transect Int NOT NULL , id_protocole Int , PRIMARY KEY (id_passage ,id_transect ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: PROTOCOLE #------------------------------------------------------------ CREATE TABLE PROTOCOLE( id_protocole int (11) Auto_increment NOT NULL , libelle Varchar (25) , PRIMARY KEY (id_protocole ) , UNIQUE (libelle ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: REF_DEPARTEMENT #------------------------------------------------------------ CREATE TABLE REF_DEPARTEMENT( id_departement int (11) Auto_increment NOT NULL , Cd_departement Varchar (25) , libelle_dpt Varchar (25) , insee_dpt Int , PRIMARY KEY (id_departement ) , UNIQUE (Cd_departement ,insee_dpt ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: ELEMENT #------------------------------------------------------------ CREATE TABLE ELEMENT( id_element int (11) Auto_increment NOT NULL , geometrie Varchar (25) NOT NULL , id_a_supprimer Int NOT NULL , id_espece Int NOT NULL , PRIMARY KEY (id_element ,id_a_supprimer ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: TYPE_ELEMENT #------------------------------------------------------------ CREATE TABLE TYPE_ELEMENT( id_element int (11) Auto_increment NOT NULL , code_element Int , libelle_element Int , PRIMARY KEY (id_element ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: PASSAGE_POINT #------------------------------------------------------------ CREATE TABLE PASSAGE_POINT( heure_passage Time , id_a_supprimer int (11) Auto_increment NOT NULL , id_point Int NOT NULL , id_transect Int NOT NULL , id_passage Int NOT NULL , PRIMARY KEY (id_a_supprimer ,id_point ,id_transect ,id_passage ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: EST_AFFECTE #------------------------------------------------------------ CREATE TABLE EST_AFFECTE( date_structure Date , id_technicien Int NOT NULL , id_structure Int NOT NULL , PRIMARY KEY (id_technicien ,id_structure ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: INVENTORIE #------------------------------------------------------------ CREATE TABLE INVENTORIE( id_technicien Int NOT NULL , id_passage Int NOT NULL , id_transect Int NOT NULL , PRIMARY KEY (id_technicien ,id_passage ,id_transect ) )ENGINE=InnoDB; #------------------------------------------------------------ # Table: TYPER #------------------------------------------------------------ CREATE TABLE TYPER( id_element Int NOT NULL , id_element_ELEMENT Int NOT NULL , id_a_supprimer Int NOT NULL , PRIMARY KEY (id_element ,id_element_ELEMENT ,id_a_supprimer ) )ENGINE=InnoDB; ALTER TABLE POINT ADD CONSTRAINT FK_POINT_id_transect FOREIGN KEY (id_transect) REFERENCES TRANSECT(id_transect); ALTER TABLE TRANSECT ADD CONSTRAINT FK_TRANSECT_id_departement FOREIGN KEY (id_departement) REFERENCES REF_DEPARTEMENT(id_departement); ALTER TABLE ESPECE ADD CONSTRAINT FK_ESPECE_cd_nom FOREIGN KEY (cd_nom) REFERENCES REF_TAXREF(cd_nom); ALTER TABLE PASSAGE ADD CONSTRAINT FK_PASSAGE_id_transect FOREIGN KEY (id_transect) REFERENCES TRANSECT(id_transect); ALTER TABLE PASSAGE ADD CONSTRAINT FK_PASSAGE_id_protocole FOREIGN KEY (id_protocole) REFERENCES PROTOCOLE(id_protocole); ALTER TABLE ELEMENT ADD CONSTRAINT FK_ELEMENT_id_a_supprimer FOREIGN KEY (id_a_supprimer) REFERENCES PASSAGE_POINT(id_a_supprimer); ALTER TABLE ELEMENT ADD CONSTRAINT FK_ELEMENT_id_espece FOREIGN KEY (id_espece) REFERENCES ESPECE(id_espece); ALTER TABLE PASSAGE_POINT ADD CONSTRAINT FK_PASSAGE_POINT_id_point FOREIGN KEY (id_point) REFERENCES POINT(id_point); ALTER TABLE PASSAGE_POINT ADD CONSTRAINT FK_PASSAGE_POINT_id_transect FOREIGN KEY (id_transect) REFERENCES TRANSECT(id_transect); ALTER TABLE PASSAGE_POINT ADD CONSTRAINT FK_PASSAGE_POINT_id_passage FOREIGN KEY (id_passage) REFERENCES PASSAGE(id_passage); ALTER TABLE EST_AFFECTE ADD CONSTRAINT FK_EST_AFFECTE_id_technicien FOREIGN KEY (id_technicien) REFERENCES TECHNICIEN(id_technicien); ALTER TABLE EST_AFFECTE ADD CONSTRAINT FK_EST_AFFECTE_id_structure FOREIGN KEY (id_structure) REFERENCES STRUCTURE(id_structure); ALTER TABLE INVENTORIE ADD CONSTRAINT FK_INVENTORIE_id_technicien FOREIGN KEY (id_technicien) REFERENCES TECHNICIEN(id_technicien); ALTER TABLE INVENTORIE ADD CONSTRAINT FK_INVENTORIE_id_passage FOREIGN KEY (id_passage) REFERENCES PASSAGE(id_passage); ALTER TABLE INVENTORIE ADD CONSTRAINT FK_INVENTORIE_id_transect FOREIGN KEY (id_transect) REFERENCES TRANSECT(id_transect); ALTER TABLE TYPER ADD CONSTRAINT FK_TYPER_id_element FOREIGN KEY (id_element) REFERENCES TYPE_ELEMENT(id_element); ALTER TABLE TYPER ADD CONSTRAINT FK_TYPER_id_element_ELEMENT FOREIGN KEY (id_element_ELEMENT) REFERENCES ELEMENT(id_element); ALTER TABLE TYPER ADD CONSTRAINT FK_TYPER_id_a_supprimer FOREIGN KEY (id_a_supprimer) REFERENCES PASSAGE_POINT(id_a_supprimer);
Aurriez vous une solution à proposer pour PostGis? J'ai testé (mais dépassé le délais :-/ ) Win Design et il y a pgModeler qui a l'air vraiment pas mal mais payant (pas si cher au final).
Encore un gros merci à fsmrel
Bonsoir Alex,
Bien sûr ! Supposons quà loccasion du relevé concernant le transect TR1, le point PT1, le passage PA1 à lheure HE1, le technicien a relevé la présence :
dun seul élément <TR1, PT1, PA1, EL1>
dun seul élément <TR1, PT1, PA1, EL2>
de 50 éléments <TR1, PT1, PA1, EL3>
Exemple de code SQL (jai conservé les valeurs symboliques, donc sans tenir compte du type réel des attributs varchar, auto-increment, etc.) :
Doù le contenu des tables :INSERT INTO PASSAGE_POINT {id_transect, id_point, id_passage, heure_passage} VALUES (TR1, PT1, PA1, HE1) ; INSERT INTO ELEMENT (id_transect, id_point, id_passage, id_element, nb_elements, ...) VALUES (TR1, PT1, PA1, EL1, 1, ...) ; INSERT INTO ELEMENT (id_transect, id_point, id_passage, id_element, nb_elements, ...) VALUES (TR1, PT1, PA1, EL2, 1, ...) ; INSERT INTO ELEMENT (id_transect, id_point, id_passage, id_element, nb_elements, ...) VALUES (TR1, PT1, PA1, EL3, 50, ...) ;
PASSAGE_POINT {id_transect, id_point, id_passage, heure_passage} TR1 PT1 PA1 HE1 ELEMENT {id_transect, id_point, id_passage, id_element, nb_elements, ...} TR1 PT1 PA1 EL1 1 ... TR1 PT1 PA1 EL2 1 ... TR1 PT1 PA1 EL3 50 ...
Je nai pas ce problème. Avons-nous la même version de loutil ? De mon côté, jai installé la version 0.4.0.1.
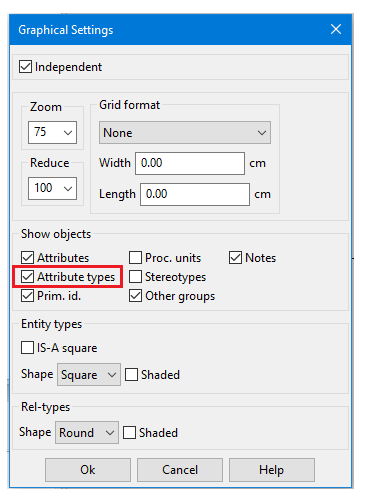
Il suffit de le lui demander
Barre de menus > VIEW > Graphical Settings, puis cocher la case « Attribute types » :
MySQL Workbench génère du SQL pour MySQL, mais JMerise aussi ! Avec la différence quavec MWB on sait produire du code valide, alors quavec JMerise cest la cata. De toute façon convertir du SQL orienté MySQL en SQL orienté PostgreSQL est un exercice simple (je ne parle pas de lextension spatiale, je ne la connais pas).
La dernière fois que jai utilisé l'excellent WinDesign, cétait exactement il y a 20 ans...
Je ne connais pas pgModeler, mais faire un don de 10 dollars nest pas ruineux. Si un jour jai le temps, je le secouerai...
En attendant, je sens que je vais faire une génération de code SQL avec MySQL Workbench, dautant que jai pondu la moitié du MLD. Je verrai ce que cela représente de le bricoler pour PostgreSQL.
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Je suis également sur la 0.4.0.1, mais à priori, il lui faut obligatoirement une clé primaire!... comment avez vous fait pour ne pas avoir de clé primaire dans l'entité "PASSAGE_POINT"?
J'ai aussi fouillé dans les paramètres de JMerise, et il peut générer du sql postgres
Bonsoir Alex,
A propos du code SQL généré par JMerise, supprimer partout "ENGINE=InnoDB" paramètre spécifique à MySQL.
Sauf quand une colonne est du type SERIAL (auto-incrément de PostgreSQL), coder systématiquement « NOT NULL » pour chaque colonne de chaque table.
Par exemple pour la table TECHNICIEN, interdire au bonhomme Null laccès aux colonnes :
* email,
* actif (pour un booléen, 3 états possibles ça fait désordre
Entité-type ELEMENT : je nai pas vu lattribut nb_elements, je lai ajouté de mon côté.
Jai fait un petit essai avec PostgreSQL, voici le code SQL correspondant au coeur du modèle :
Résultat du SELECT * FROM ELEMENT :SET search_path TO alex ; DROP TABLE IF EXISTS ELEMENT ; DROP TABLE IF EXISTS PASSAGE_POINT ; DROP TABLE IF EXISTS PASSAGE ; DROP TABLE IF EXISTS POINT ; DROP TABLE IF EXISTS TRANSECT ; DROP TABLE IF EXISTS DEPARTEMENT ; DROP TABLE IF EXISTS ESPECE ; CREATE TABLE ESPECE ( id_espece INTEGER NOT NULL , CONSTRAINT ESPECE_PK PRIMARY KEY (id_espece) ) ; INSERT INTO ESPECE (id_espece) VALUES (1) ; INSERT INTO ESPECE (id_espece) VALUES (2) ; INSERT INTO ESPECE (id_espece) VALUES (3) ; SELECT * FROM ESPECE ; CREATE TABLE DEPARTEMENT ( id_departement SERIAL , cd_departement VARCHAR(3) NOT NULL , libelle_dpt VARCHAR(32) NOT NULL , CONSTRAINT DEPARTEMENT_PK PRIMARY KEY (id_departement) , CONSTRAINT DEPARTEMENT_AK UNIQUE (cd_departement) ) ; INSERT INTO DEPARTEMENT (cd_departement, libelle_dpt) VALUES ('91', 'Essonne') ; SELECT * FROM DEPARTEMENT ; CREATE TABLE TRANSECT ( id_transect SMALLINT NOT NULL , id_departement INTEGER NOT NULL , CONSTRAINT TRANSECT_PK PRIMARY KEY (id_transect) , CONSTRAINT TRANSECT_DPT_FK FOREIGN KEY (id_departement) REFERENCES DEPARTEMENT (id_departement) ) ; INSERT INTO TRANSECT (id_transect, id_departement) VALUES (1, 1) ; INSERT INTO TRANSECT (id_transect, id_departement) VALUES (2, 1) ; SELECT * FROM TRANSECT ; CREATE TABLE POINT ( id_transect SMALLINT NOT NULL , id_point SMALLINT NOT NULL , geometrie VARCHAR(32) NOT NULL , CONSTRAINT POINT_PK PRIMARY KEY (id_transect, id_point) , CONSTRAINT POINT_ID CHECK (id_point IN (1,2,3,4,5,6,7,8,9,10)) , CONSTRAINT POINT_TRANSECT_FK FOREIGN KEY (id_transect) REFERENCES TRANSECT (id_transect) ) ; INSERT INTO POINT (id_transect, id_point, geometrie) VALUES (1, 1, '') ; INSERT INTO POINT (id_transect, id_point, geometrie) VALUES (1, 2, '') ; SELECT * FROM POINT ; CREATE TABLE PASSAGE ( id_transect SMALLINT NOT NULL , id_passage SERIAL , date_passage DATE NOT NULL , validation BOOLEAN NOT NULL , date_validation DATE NOT NULL , CONSTRAINT PASSAGE_PK PRIMARY KEY (id_transect, id_passage) , CONSTRAINT PASSAGE_TRANSECT_FK FOREIGN KEY (id_transect) REFERENCES TRANSECT (id_transect) ) ; INSERT INTO PASSAGE (id_transect, date_passage, validation, date_validation) VALUES (1, '2018-03-12', false, '9999-12-31') ; INSERT INTO PASSAGE (id_transect, date_passage, validation, date_validation) VALUES (1, '2018-03-12', false, '9999-12-31') ; SELECT * FROM PASSAGE ; CREATE TABLE PASSAGE_POINT ( id_transect SMALLINT NOT NULL , id_point SMALLINT NOT NULL , id_passage SMALLINT NOT NULL , heure_passage TIME NOT NULL , CONSTRAINT PASSAGE_POINT_PK PRIMARY KEY (id_transect, id_point, id_passage) , CONSTRAINT PASSAGE_POINT_POINT_FK FOREIGN KEY (id_transect, id_point) REFERENCES POINT (id_transect, id_point) , CONSTRAINT PASSAGE_POINT_PASSAGE_FK FOREIGN KEY (id_transect, id_passage) REFERENCES PASSAGE (id_transect, id_passage) ) ; INSERT INTO PASSAGE_POINT (id_transect, id_point, id_passage, heure_passage) VALUES (1, 1, 1, '09:30') ; INSERT INTO PASSAGE_POINT (id_transect, id_point, id_passage, heure_passage) VALUES (1, 2, 1, '10:00') ; SELECT * FROM PASSAGE_POINT ; CREATE TABLE ELEMENT ( id_transect SMALLINT NOT NULL , id_point SMALLINT NOT NULL , id_passage SMALLINT NOT NULL , id_element SERIAL , id_espece SMALLINT NOT NULL , nb_elements SMALLINT NOT NULL , geometrie VARCHAR(32) NOT NULL , CONSTRAINT ELEMENT_PK PRIMARY KEY (id_transect, id_point, id_passage, id_element) , CONSTRAINT ELEMENT_PASSAGE_POINT_FK FOREIGN KEY (id_transect, id_point, id_passage) REFERENCES PASSAGE_POINT (id_transect, id_point, id_passage) , CONSTRAINT ELEMENT_ESPECE_FK FOREIGN KEY (id_espece) REFERENCES ESPECE (id_espece) ) ; INSERT INTO ELEMENT (id_transect, id_point, id_passage, id_espece, nb_elements, geometrie) VALUES (1, 2, 1, 3, 50, '') ; INSERT INTO ELEMENT (id_transect, id_point, id_passage, id_espece, nb_elements, geometrie) VALUES (1, 2, 1, 2, 1, '') ; SELECT * FROM ELEMENT ;

Jai refouillé dans le paramétrage de JMerise pour voir pourquoi ça marche chez moi : je nai rien trouvé...
Attention : la notion de clé primaire ne fait pas partie du vocabulaire de MERISE, lauteur de JMerise commet un abus de langage. On doit parler didentifiant en MERISE et seulement en SQL de clé primaire (ou principale, parce quelle est plus égale que les autres clés de la table).
De toute façon, je pense que lon peut coder directement le script de génération des structures des tables SQL à la mano, comme je lai fait ci-dessus ; ce qui manque ne devrait pas prendre beaucoup de temps et je pourrai vous aider si la saisie manuelle vous pose un problème.
Quen pensez-vous ?
____________________
P.-S. Si vous avez 5 minutes, vous pouvez voter ici aussi...
(a) Faites simple, mais pas plus simple ! (A. Einstein)
(b) Certes, E=mc², mais si on discute un peu, on peut lavoir pour beaucoup moins cher... (G. Lacroix, « Les Euphorismes de Grégoire »)
=> La relativité n'existerait donc que relativement aux relativistes (Jean Eisenstaedt, « Einstein et la relativité générale »)
__________________________________
Bases de données relationnelles et normalisation : de la première à la sixième forme normale
Modéliser les données avec MySQL Workbench
Je ne réponds pas aux questions techniques par MP. Les forums sont là pour ça.
Bonjour fsmrel,
Merci, en effet, à plusieurs endroits, je n'avais pas mis de NOT NULL! Notamment pour le booléen ou certaines clés primaires!
Il y certains qui n'ont pas de mails personnels, donc on préfère un null qu'un mail générique ou celui de la structure.
à quel endroit dois-je l'ajouter? car il me semblait que ça faisait redondance de l'ajouter... Je rajoute donc l'attribut nb_element dans l'entité ELEMENT?
Je ne vois pas non plus d'où ça vient... j'ai remis mon "id_a_supprimer"
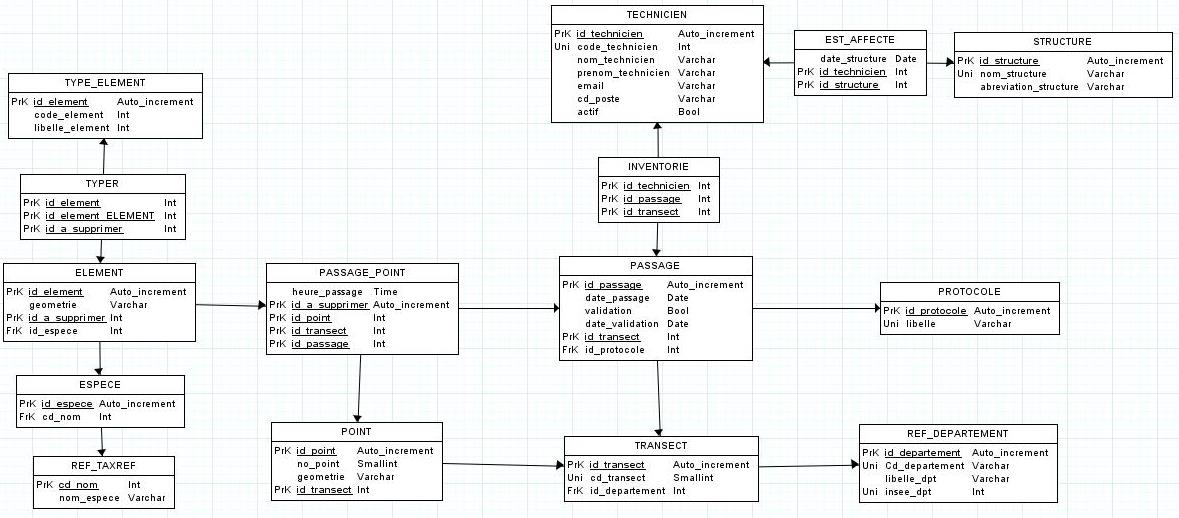
Voici donc le MCD final:
le MLD final
et enfin le code SQL généré (il me reste à ajuster la longueur des champs notamment):
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
Je viens d'essayer de créer ma base de données dans postgresql, sans le "id_a_supprimer" défini comme clé primaire et il me met ce message:
Donc est ce qu'il ne faut pas quand mêem mettre une clé primaire? fsmrel, vous me dites que ça fonctionne sur votre JMerise, avez vous bien les mêmes choses que moi?
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Merci

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.

 Répondre avec citation
Répondre avec citation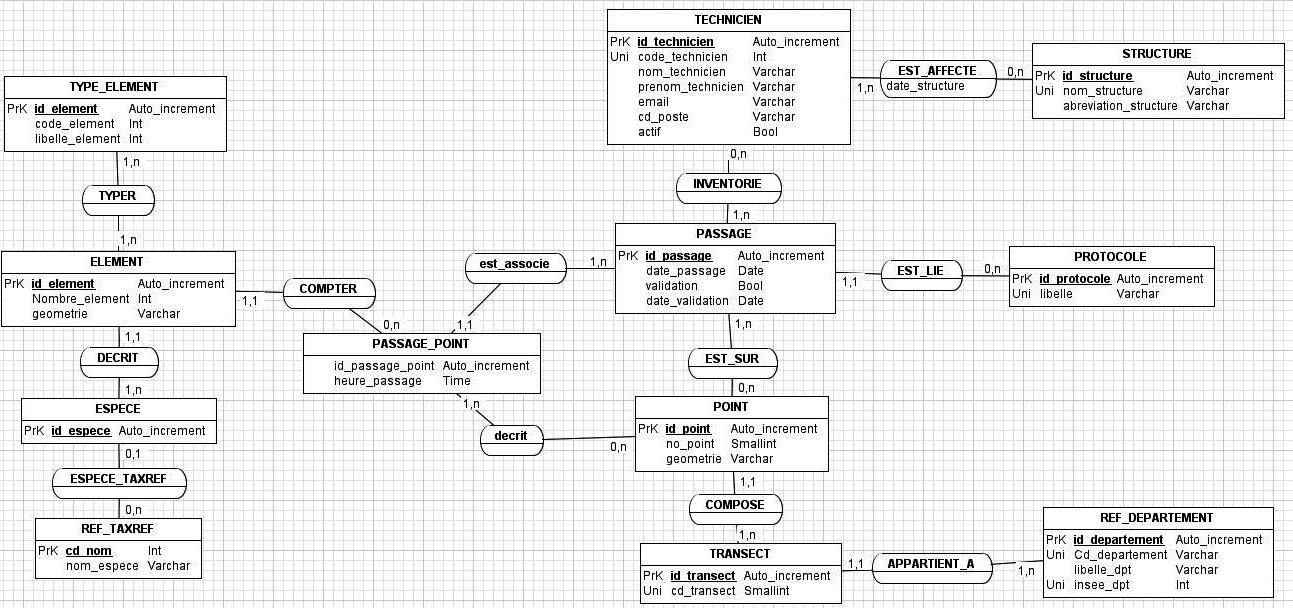
Partager