












Les programmeurs présentent des réactions cérébrales distinctes, liées à leur expertise, aux violations de forme et de sens lors de la lecture de codes, selon une étude de l'université de Washington
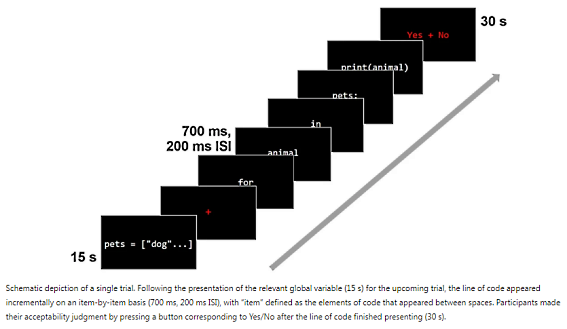
Alors que la programmation informatique occupe une place de plus en plus centrale dans le monde du travail, la nécessité de disposer de meilleurs modèles sur la manière dont elle est effectivement apprise est de plus en plus évidente. Une étude menée par des chercheurs de l'université de Washington, et publiée dans le journal Scientific Reports, a comblé cette lacune en enregistrant les réponses cérébrales électrophysiologiques de 62 programmeurs Python de différents niveaux de compétence lors de la lecture de lignes de code comportant des manipulations de la forme (syntaxe) et du sens (sémantique).
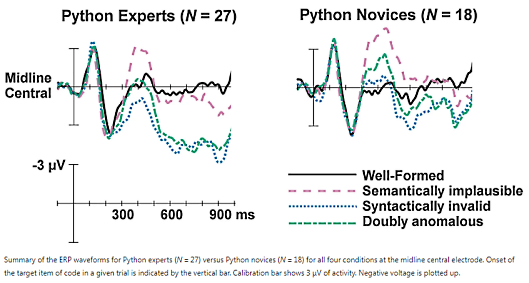
Au niveau du groupe étudié, les résultats ont montré que les manipulations de la forme entraînaient des effets P600, le code syntaxiquement invalide générant plus de déflexions positives dans la plage 500-800 ms que le code syntaxiquement valide. Les manipulations du sens ont entraîné des effets N400, le code sémantiquement non plausible générant plus de déflexions négatives dans la plage 300-500 ms que le code sémantiquement plausible.
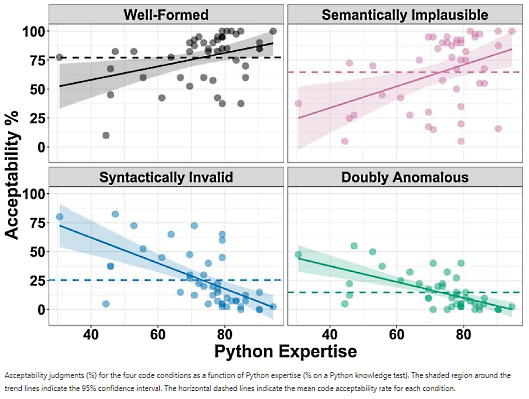
Une plus grande expertise Python au sein du groupe a été associée à une plus grande sensibilité aux violations de forme. Ces résultats soutiennent l'idée que les compétences en programmation, tout comme les compétences en apprentissage du langage naturel, sont associées à l'incorporation de connaissances fondées sur des règles dans les processus de compréhension en ligne. Inversement, les programmeurs de tous les niveaux de compétence ont montré une sensibilité neuronale aux manipulations de sens, ce qui suggère que le recours à des relations sémantiques préexistantes facilite la compréhension du code à tous les niveaux de compétence.
Selon les auteurs de l'étude, il s'agit des premières données empiriques étayant les comparaisons cognitives entre la lecture et la compréhension du code. Plus précisément, leurs données suggèrent que lorsque des programmeurs compétents lisent des lignes de code, ils utilisent des informations sur la forme de l'énoncé et sur la signification des mots pour mettre à jour progressivement leur représentation mentale de ce que le code tente d'accomplir, tout comme les lecteurs d'une langue naturelle utilisent des informations sur la structure grammaticale et sur la sémantique des mots pour comprendre le sens d'une phrase. Dans l'expérience menée par les chercheurs de l'université de Washington, cela s'est traduit respectivement par des effets N400 et P600 distincts chez les programmeurs lors de manipulations sémantiques et syntaxiques du code.
En outre, les résultats de cette étude suggèrent qu'au fur et à mesure que les programmeurs acquièrent de l'expertise dans un langage de programmation particulier, leurs réponses cérébrales reflètent de plus en plus la sensibilité aux connaissances fondées sur des règles dans leurs processus de compréhension en ligne. Cette progression, appelée "grammaticalisation" dans l'apprentissage des langues naturelles, est également observée lors de l'acquisition d'une seconde langue naturelle. Bien que cette analyse de l'expertise soit transversale, il convient de noter que cette tendance à l'augmentation des effets P600 avec une plus grande expertise a été démontrée dans des études transversales et longitudinales d'apprenants d'une deuxième langue naturelle. On pourrait donc s'attendre à une tendance similaire, à savoir l'apparition d'effets P600 plus marqués au fil du temps avec une exposition croissante aux langages de programmation. Les auteurs de l'étude considèrent qu'il s'agit là d'un domaine intéressant pour les recherches à venir.
Il convient de noter que l'expertise en programmation n'a peut-être pas influencé la sensibilité neuronale aux manipulations sémantiques, mais la manière dont les auteurs ont manipulé la plausibilité sémantique reflétait des relations sémantiques préexistantes (par exemple, des relations catégorielles entre les noms de variables) plutôt que des relations spécifiques au code (par exemple, la substitution de fonctions qui sont liées à l'opération prévue dans une ligne de code, mais qui n'en sont pas l'objet). Bien que ces manipulations sémantiques soient loin d'être une exploration complète, des manipulations catégorielles similaires ont été utilisées pour comprendre les fondements cognitifs de la compréhension des mathématiques, tant au niveau du groupe que de l'individu.
En outre, ces résultats suggèrent que les programmeurs de différents niveaux d'expertise montrent une sensibilité neuronale aux relations sémantiques préexistantes dans les lignes de code, même lorsqu'elles n'ont que peu ou pas d'importance pour ce que fait le code (par exemple, dans les noms de variables). Cette activation neuronale supplémentaire a été proposée pour refléter une difficulté accrue à retrouver la signification de l'élément cible ou à intégrer cette signification dans la représentation globale de la structure en question.
La tendance comportementale observée par les chercheurs suggère également que les programmeurs moins compétents, dont les processus basés sur les règles ne sont pas encore totalement opérationnels, sont légèrement plus susceptibles de juger une ligne de code bien formée comme inacceptable lorsque les relations sémantiques entre les éléments ne sont pas plausibles.
Dans l'ensemble, ces données soutiennent l'idée que l'utilisation d'associations de sens préexistantes peut faciliter la compréhension du code pour certaines personnes. Ceci est cohérent avec des travaux antérieurs démontrant que des identifiants significatifs et efficaces favorisent une compréhension plus rapide et plus précise du code.
Lors de l'interprétation de ces résultats, les scientifiques de l'université de Washington ont noté que l'observation de réponses similaires à celles du langage à des violations dans des lignes de code ne fournit pas, en soi, la preuve que la compréhension du code repose sur les mêmes substrats neuronaux que la compréhension du langage. Une telle déduction nécessiterait un outil avec une meilleure résolution spatiale, comme l'IRMf, et les résultats de telles études ont été mitigés. En revanche, ces résultats viennent s'ajouter à un nombre croissant de travaux indiquant que les composantes N400 et P600 ne sont pas spécifiques au traitement du langage naturel. Les résultats de recherches utilisant divers stimuli, notamment des problèmes de mots mathématiques, le langage naturel, la musique et maintenant le code Python, convergent pour démontrer l'existence de neuro-computations communes au cur de l'intégration incrémentale d'informations séquentielles dans une structure de sens plus large.
À la lumière de ces similitudes, les auteurs de l'étude proposent que le débat actuel sur la question de savoir si le code est plus "proche du langage" ou "proche des mathématiques" soit mieux formulé en s'interrogeant sur les types d'informations que les programmeurs utilisent pour comprendre ce que fait une ligne de code, et sur la manière dont ces informations évoluent au fur et à mesure qu'ils deviennent plus compétents.
En résumé, ces chercheurs de l'université de Washington présentent la première étude montrant que les programmeurs font preuve d'une sensibilité neuronale aux informations relatives à la forme et au sens lorsqu'ils s'engagent dans la construction incrémentale en temps réel de représentations mentales au cours de la compréhension du code. Ce faisant, les programmeurs experts sont plus sensibles aux relations structurelles entre les éléments, caractérisées par des réponses cérébrales proéminentes aux violations syntaxiques dans les 600 ms suivant la visualisation d'un élément. En revanche, les programmeurs de différents niveaux de compétence présentent une sensibilité neuronale similaire aux relations sémantiques préexistantes entre les éléments du code, les programmeurs les plus novices se fiant légèrement plus à ces informations lorsqu'ils émettent des jugements d'"acceptabilité" comportementale hors ligne. Dans l'ensemble, ces résultats suggèrent que les processus qui soutiennent la compréhension du code ressemblent à ceux d'autres systèmes symboliques appris, basés sur des règles, tels que la lecture, l'algèbre et l'apprentissage d'une seconde langue en classe.
Source : "Computer programmers show distinct, expertise-dependent brain responses to violations in form and meaning when reading code" (étude de l'université de Washington)
Et vous ?
Quel est votre avis sur le sujet ?
Voir aussi :
 Répondre avec citation
Répondre avec citation
Partager