









Bonjour à tous,
J'ai réalisé un différentes méthodes de prédiction afin de parvenir à identifier des personnes susceptibles de résilier leurs contrats (churns).
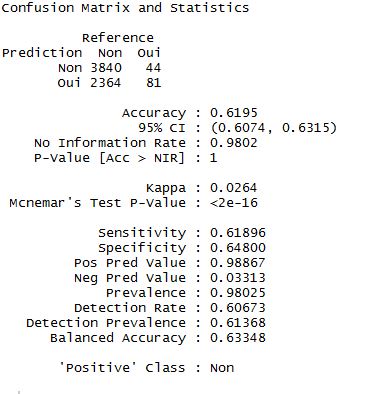
Je possède 26 variables dans mon analyse et en utilisant un arbre de décision avec la méthode "rpart" (plutôt reconnue), j'obtiens la matrice de confusion suivante :
La précision est correcte même si perfectible, cependant l'objectif le plus intéressant dans cette analyse est d'identifier les personnes qui résilient, ce que fait l'algorithme avec 3,3% de précision seulement...
Je cherche ainsi de nouvelles manières de faire grimper la précision pour la modalité "Oui". J'ai pensé à passer par une phase de pré-traitement (Dummy Variables puis centrer-réduire) mais j'ai peur que cela ne serve pas à grand chose...
Je suis preneur de toutes les suggestions que vous pourrez m'apporter
Merci à vous.
 Répondre avec citation
Répondre avec citation







Partager