



Connaitriez vous un algorithme ou un programme (pascal ou VB) de régression linéaire par morceaux?
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter




Connaitriez vous un algorithme ou un programme (pascal ou VB) de régression linéaire par morceaux?
euh..
Peux-tu expliquer un peu ?
Parce que en général ça s'appelle juste "interpolation linéaire" : entre chaque couple de points on interpole linéairement..
Donc le programmer est extrêmement simple.... dans n'importe quel langage...
On a une base de points initiaux (un tableau) Pts (x,y)
Pour un nouveau point, on cherche entre quels indices il se situe. (i, i+1)
Puis on fait une règle de trois.. On "interpole linéairement"
"Un homme sage ne croit que la moitié de ce quil lit. Plus sage encore, il sait laquelle".
Consultant indépendant.
Architecture systèmes complexes. Programmation grosses applications critiques. Ergonomie.
C, Fortran, XWindow/Motif, Java
Je ne réponds pas aux MP techniques
















Donc, on peut faire une régression plus complexe que linéaire (quadratique, polynomiale en général), puis en faire une approximation linéaire par morceaux.
Vous souhaitez participer aux rubriques Qt (tutoriels, FAQ, traductions) ou HPC ? Contactez-moi par MP.
Créer des applications graphiques en Python avec PyQt5
Créer des applications avec Qt 5.
Pas de question d'ordre technique par MP !

Je pense que sa question c'est "comment déterminer les morceaux" pour avoir une approximation optimale.
Si c'est bien cela, il y a plusieurs méthodes dans la littérature (optimal piecewise linear approximation).
Le plus simple (mais pas forcément optimal) c'est de faire une suite d'approximations locales:
1. Approximer la courbe par un segment qui rejoint les 2 extrémités de la courbe: [A,B].
2. Chercher le point P de la courbe qui est le plus éloigné de l'approximation (= le plus loin du segment).
3. Remplacer le segment [A,B] par les deux segments [A, P] et [P, B]
4. Recommencer à l'étape 2 jusqu'à atteindre un erreur acceptable.
Sinon il y a la méthode inverse dans laquelle on fait un découpage uniforme de la courbe en petits segments,
puis on on fusionne itérativement les segments jusqu'à atteindre un erreur acceptable (Douglas-Peucker algorithm)
ALGORITHME (n.m.): Méthode complexe de résolution d'un problème simple.


Salut,
Pour moi une régression linéaire c'est chercher une droite qui traversent au mieux l'ensemble des points alors qu'une interpolation linéaire c'est chercher une courbe qui passe par tous les points.Envoyé par souviron34

Non ?
La science ne nous apprend rien : c'est l'expérience qui nous apprend quelque chose.
Richard Feynman
Si, je suis d'accord....
MAIS
le problème est le "par morceaux"
J'ai bien peur que le PO n'aie pas très très bien compris.. -ou expliqué...
")
"Un homme sage ne croit que la moitié de ce quil lit. Plus sage encore, il sait laquelle".
Consultant indépendant.
Architecture systèmes complexes. Programmation grosses applications critiques. Ergonomie.
C, Fortran, XWindow/Motif, Java
Je ne réponds pas aux MP techniques

Salut,
pseudocode a apporté la réponse la plus claire.
La seule information supplémentaire que l'on pourrait souhaiter, c'est l'aspect général du nuage de points: la "courbe moyenne" présente-t-elle une courbure continue, ou des parties quasi-rectilignes ? Les domaines de régression linéaire sont-ils éventuellement prédéfinis en limite ou en nombre ? Cela pourrait orienter la recherche du meilleur algorithme.
j'ai une fonction Y=f(X) définie sur un très grand nombre de points (27000) lorsque je représente cette fonction en
Excel j'obtiens une ligne brisée de quelques segments (entre 5 et 10). Mais ça c'est ce que je constate
sur mon graphe mais je ne connais pas d'algorithme/fonction qui me permettrait de récupérer, à partir de tous ces points, la suite
des segments décrits par leurs extrémités (Xdébut, Ydébut) --> (Xfin, Yfin).
Je suis à la recherche code ou simplement un algorithme qui me permettrait de faire cela ?
Alors la solution me paraît toute trouvée: le calcul de la pente locale sur les (2*n) points encadrant le point considéré, de rang (k), par la formule:
pk = (n+1)-1*[(yk+1 + yk+2 + ... + yk+n) - (yk-1 + yk-2 + ... + yk-n)] sur le domaine [n ; N - k].
Prendre une valeur modérée pour (n): 3 à 10 ? à toi de voir; il n'est même pas nécessaire de tenir compte du facteur constant (n+1)-1; la grandeur calculée sera alors p'k = (n+1) * pk .
L'essentiel est que le graphe de la suite y(k) = pk présente une série de paliers horizontaux séparés par une variation très rapide au voisinage des points de raccordement.
Les bornes apparaîtront d'autant plus nettement que (n) est plus petit ... d'où l'intérêt, pour ce dernier, de ne pas lui donner une valeur trop élevée - ce qui favorisera aussi la rapidité du calcul.
Autre solution, encore plus directe: les points de raccordement des parties quasi-rectilignes (qu'il ne sera peut-être pas nécessaire d'incorporer aux calculs de régression linéaire) se distingueront par un extremum de la variation de la pente calculée sur (2*n) points deux à deux symétriquement disposés, par une combinaison linéaire semblable à la précédente:
qk = (pk+1 + pk+2 + ... + pk+n) - (pk-1 + pk-2 + ... + pk-n)
On obtient ainsi pour (n = 3): qk = Si=-66(Ci * yk+i)
avec: C0 = -6 , C1 = C-1 = -4 , C2 = C-2 = -1 , C3 = C-3 = 2 ,
C4 = C-4 = 3 , C5 = C-5 = 2 , C6 = C-6 = 1 ;
le pic observé, centré en (k), présente une demi-largeur à la base égale à 3.
Sinon, fixer les bornes à la main, ne considérer que les points de ce que tu veux comme droite, faire une régression linéaire sur ce sous-ensemble de points.
Vous souhaitez participer aux rubriques Qt (tutoriels, FAQ, traductions) ou HPC ? Contactez-moi par MP.
Créer des applications graphiques en Python avec PyQt5
Créer des applications avec Qt 5.
Pas de question d'ordre technique par MP !
mon objectif est de pouvoir synthétiser l'information effectivement utile de mes 27000 points en une dizaine de segments.
L'objet informatique ainsi obtenu est beaucoup plus facile à manipuler et il contient l'essentiel de l'information.

Sur l'exemple fourni, les données sont presque parfaitement alignées. Si tes données sont systématiquement aussi "propres", la solution de Wiwaxia va fonctionner.
Etape 1 : Remplacer chaque nombre par une moyenne mobile. (une moyenne mobile, c'est la moyenne par exemple du nombre en cours, des 10 nombres précédents et des 10 nombres suivants, c.a.dire somme des 21 nombres, divisée par 21) . On fait l'impasse sur les 10 premiers nombres , et sur les 10 derniers. On a donc une série de 27000-20 = 26980 moyennes mobiles MM.
Etape 2 : Calculer les écarts EC(n) = MM(n) - MM(n-1) ; ici, on voit nettement un premier groupe où les écarts EC sont très proches de -0.852 , puis un 2nd groupe où les écarts sont proches de -0.48 etc etc.. Tant que EC(n) est proche de EC(n-1) avec moins de 1% d'écart (seuil qu'on peut affiner), on considère qu'on est sur la même portion de droite.
Pour notre premier segment , on va prendre par exemple un point vers le début (-14.825, 16 ) et un point vers la fin ( -1488.217, 1748) Et on trouve l'équation de la droite qui passe par ces 2 points : Y = -0.8506822 x + 1.213988
On peut aussi prendre les moyennes mobiles, au lieu des points d'origine, pour limiter le risque de tomber sur un point atypique.
Ensuite, on a une zone où notre écart EC n'est pas stable (en fait il n'est pas stable parce qu'on a pris des moyenne mobiles ; si on travaillait avec les données d'origine, l'Ecart EC serait plus stable ici). Puis on va bien identifier un long segment avec une pente de -0.48. Idem, on prend un point vers le début de ce segment et un point vers la fin, et on sait calculer l'équation de cette droite.
Et pour la zone intermédiaire, on calcule où nos 2 droites se coupent. Avec des données très propres comme celles que tu as, ça ne devrait pas poser de problème.
N'oubliez pas le bouton Résolu si vous avez obtenu une réponse à votre question.
Afin d'éviter tout imbroglio, je signale avoir modifié (et simplifié) le contenu calculatoire de mon précédent message (#10).
Les variations au premier et second ordre s'expriment finalement par la même formule, utilisant n = 3 paires de termes.
Voici ce que l'on obtient au voisinage d'une discontinuité définie par: u(k<0) = 0; u(0) = 5 ; u(k>0) = 10 .
Chaque rupture de pente est ainsi repérable par un pic de hauteur proportionnelle à la discontinuité étudiée.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Merci pour toutes vos réponses.
Le message de pseudocode m'a orienté vers l'algorithme de Douglas Peucker (je me doutais qu'il devait y avoir des références sur
cette "régression linéaire par morceaux" mais je ne savais pas par où commencer). Je vais donc regarder l'algo ci-dessous en plus de tester
les solutions que vous m'avez proposées.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Lalgorithme de Douglas-Peucker donne de très bons résultats, la version itérative du programme associé est très efficace.
Le choix du bon seuil (« epsilonLocal » dans le code ci-dessous) est bien entendu crucial.
C'est en gros la méthode suggérée par pseudocode
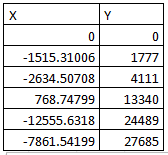
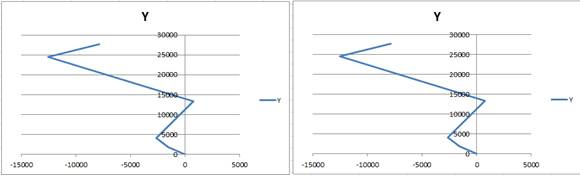
Exemple 1, résultat obtenu : 27687 points (graphe de gauche) synthétisé en à 6 points (graphe de droite)
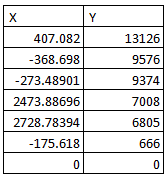
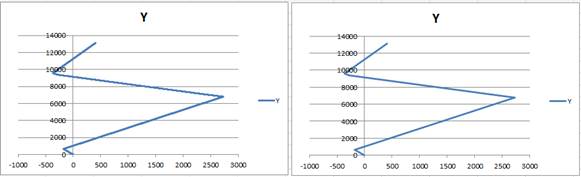
Exemple 2, résultat obtenu : 13128 points (graphe de gauche) synthétisé en à 7 points (graphe de droite)
Le codage en pascal de lalgorithme de Douglas-Peucker dans sa version itérative (Ramer)
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.
 Répondre avec citation
Répondre avec citation
![Nom : F [2017-06-23] Graphe linéaire par morceaux.png
Affichages : 1571
Taille : 4,3 Ko](https://www.developpez.net/forums/attachments/p289078d1498473488/general-developpement/algorithme-mathematiques/algorithmes-structures-donnees/regression-lineaire-morceaux/f-2017-06-23-graphe-lin-aire-morceaux.png/)
Partager