











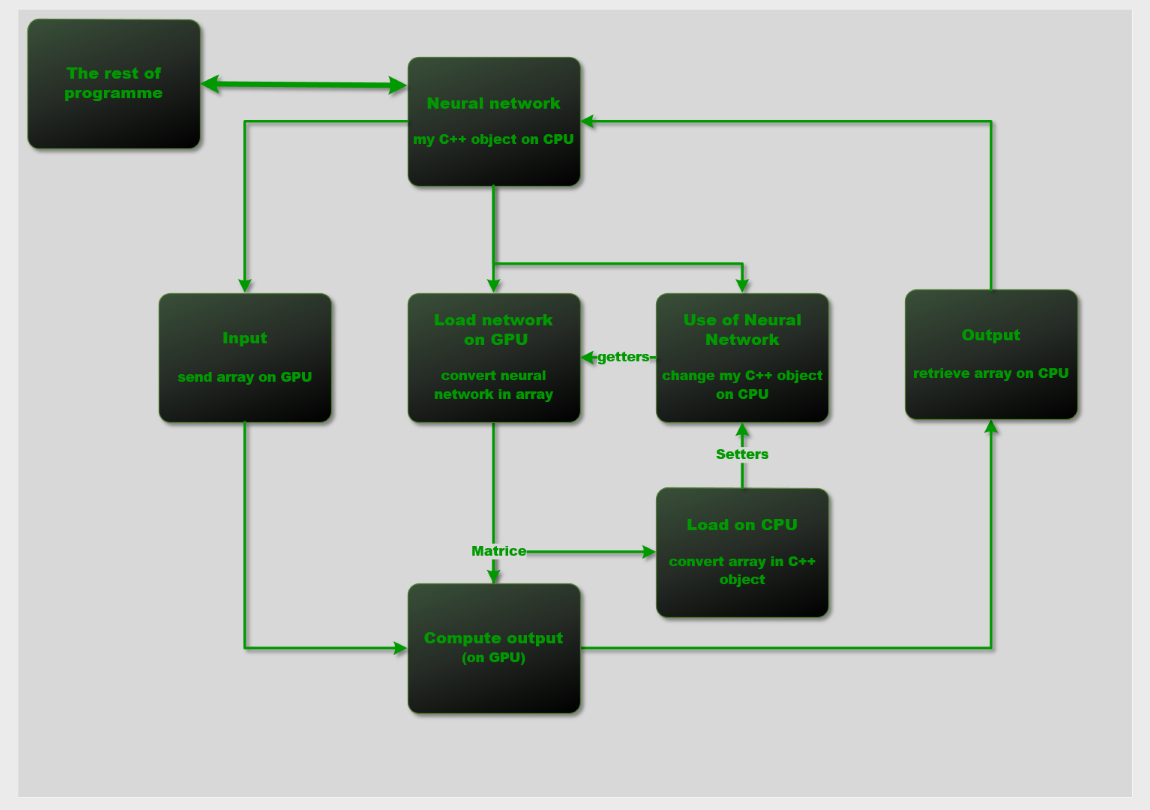
Bonjour, je suis en train d'apprendre à codé en CUDA et j'ai vu qu'il fallait passer les variables sur le GPU pour effectuer des calculs de mass. (Je développe des réseaux de neurones.)
J'aimerais savoir s'il est plus rapide de passer un tableau à mon GPU ou si passer variable par variable n'augme pas significativement le temps de calcul.
Actuellement j'ai un objet contenant des objets qui contiennent des vectors, es-ce vraiment plus rapide de transformer tout ça en matrice et de faire du calcul matriciel ?
Dites-moi ce que vous en penser
 Répondre avec citation
Répondre avec citation











Partager