














J'ai jamais parlé de "valeur 0" dans tes logs. Le 0 dont je parle c'est le nombre d'action d'un équipement donné pour une date et heure donnée lorsqu'il n'y a pas d'action de cet équipement pour cette date et heure donnée.
Pour une ligne :
correspondant à une entête :date1, heure1, 1, 0, 1, 0, 0
On a, à la date date1 et l'heure heure1 :Date, Heure, Equipement1, Equipement2, Equipement3, Equipement4, Equipement5
- pour l'équipement Equipement1 : une action au moins
- pour l'équipement Equipement2 : aucune action
- pour l'équipement Equipement3 : une action au moins
- pour l'équipement Equipement4 : aucune action
- pour l'équipement Equipement5 : aucune action
Si ton souci est de filtrer d'abord ton csv, puis de faire le comptage ensuite, malgré que ça donnerait le même résultat, tu peux appliquer la même technique de regroupement, mais au lieu de faire un counting() à la fin, il faut juste prendre l'un des élements au hasard dans la liste, le premier par exemple, ou le dernier, parce que c'est le plus simple à obtenir :
Collectors.reducing(0, (a,b)->a ) pour le premier
Collectors.reducing(0, (a,b)->b ) pour le dernier
(enfin en non parallélisé en tout cas).
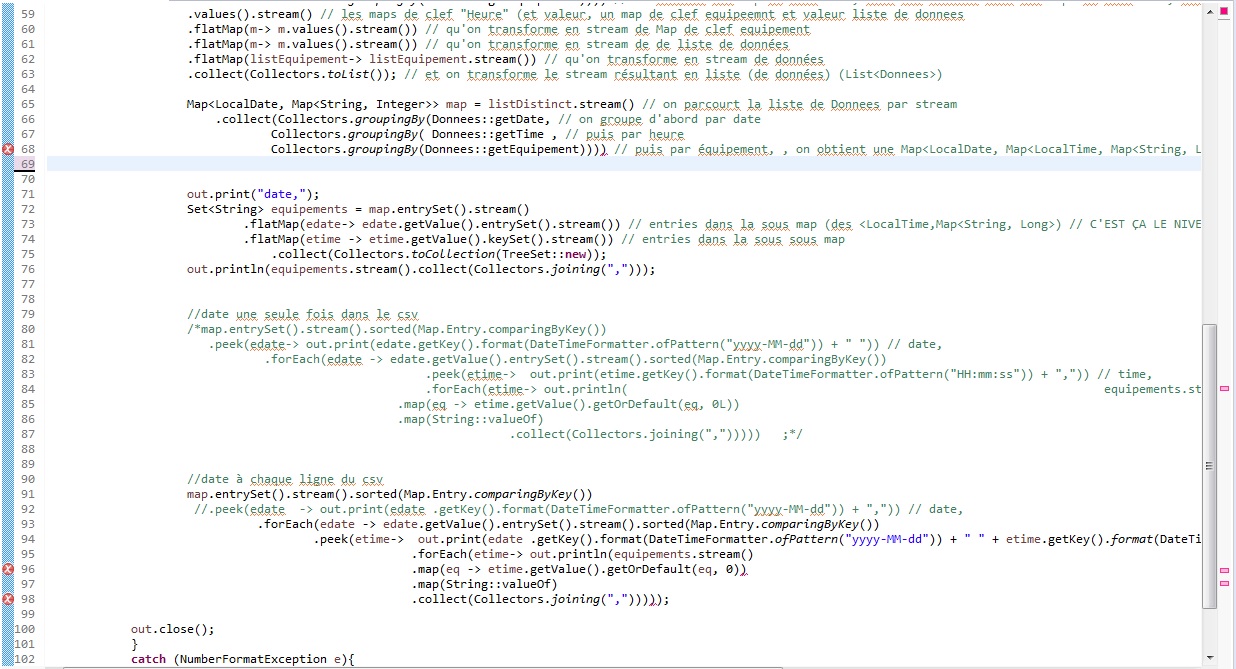
Ensuite, tu peux réobtenir une liste des données en mettant à plat la map de map de map de int... On pourrait d'ailleurs également le faire directement sans passer par le reducing,
listDistinct est la liste de toutes instances de données dictincte sur date, time et equipement (donc une pour chaque triplet de ces valeurs).
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
Maintenant si tu appliques ce tu appliquais avant sur une liste de String[], en l'adaptant puisque tu as une list de données, et le la ligne de titre est déjà tratée, tu obtiendra bien un résutat équvalent à avant, sauf que comme il n'y a plus de doublons, il n'y a plus de risque d'avoir autre chose que 0 ou 1, dans la table croisée (le comptage d'un élément ne peut pas donnée autre chose que 1).
Mais il vaut mieux procéder directement, ça évitera de reparcourir plusieurs fois les mêmes streams.
 La plupart des réponses à vos questions sont déjà dans les
La plupart des réponses à vos questions sont déjà dans les  Répondre avec citation
Répondre avec citation




Partager