









Bonjour à toutes et à tous,
Je me permets de poser ma question sur cette section qui me semble adaptée à ma problématique : SQL ou NoSQL ?
Je suis actuellement entrain de réaliser un projet informatique à l'aide du Framework Django couplé à une SGBD : MySQL.
Le principe est le suivant :
Mon application génère un certains nombre de documents, d'infos sur des animaux, ... avec une volumétrie de BDD qui augmentera très rapidement avec le temps (pourrait compter peut-être 1 milliard d'entrées assez rapidement).
Pour le moment, j'utilise MySQL car c'est le seul SGBD que je connaisse et qui pour mon développement me permet de gérer une centaine d'entrées. Néanmoins, j'ai plusieurs objectifs à remplir :
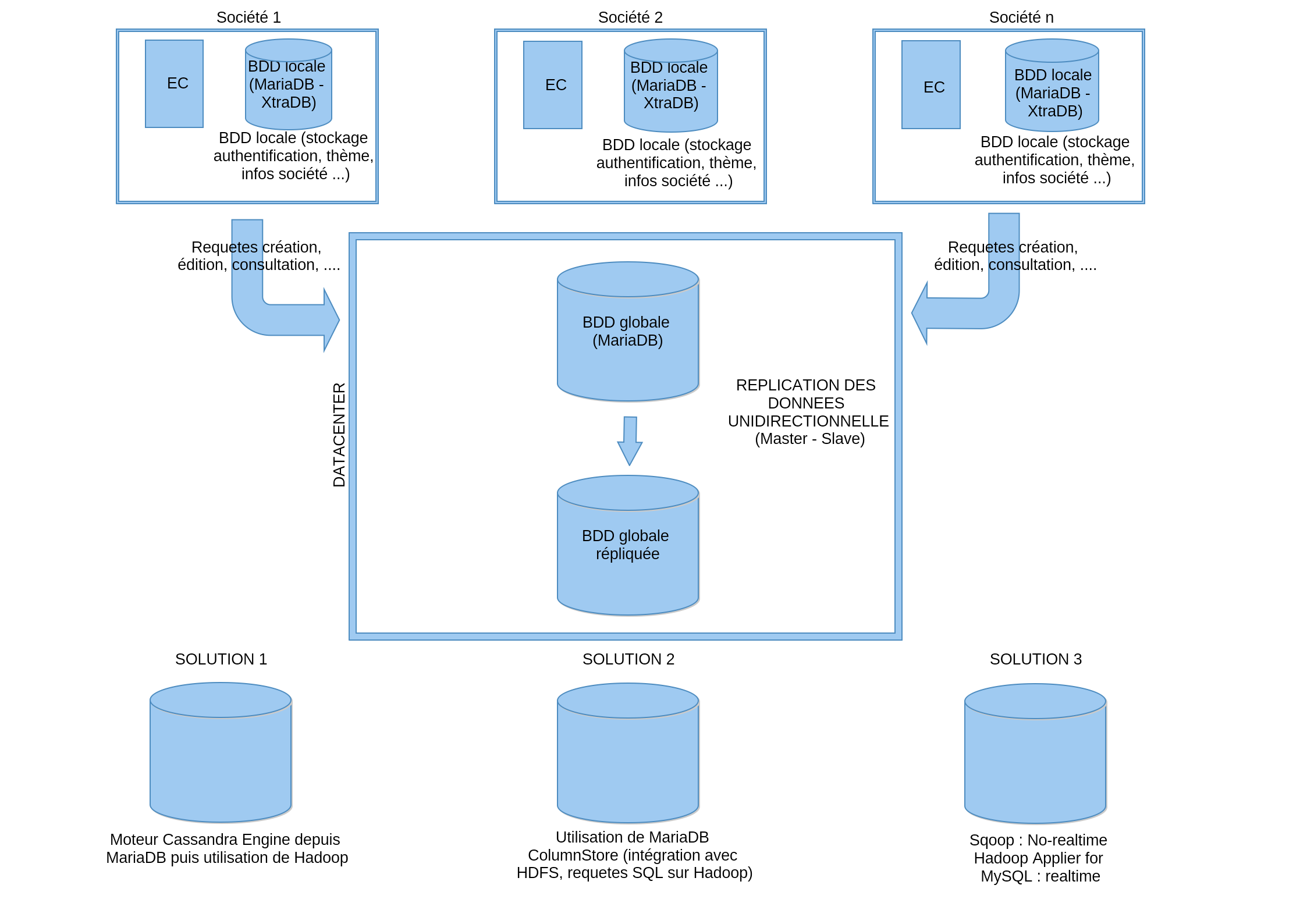
- Mon application va être implémentée dans plusieurs institutions indépendantes qui doivent gérer leurs données localement
- Chaque jour, un batch permettra de synchroniser la BDD locale de chaque institution vers un "Datacenter" qui regroupera toutes les informations de ces institutions (ainsi une requête de création stockera le résultat en local avant d'être poussé vers une BDD globale)
- Dans mon application, la consultation des données issues de sa propre institution se fera sur la BDD locale, sinon pour avoir des infos provenant des autres institutions cela se fera sur la BDD globale
- Possibilité de Big Data (Hadoop, ...) sur la BDD globale
A l'heure actuelle, j'ai développé l'équivalent d'une institution sur mon serveur de développement avec :
- Application codée en Django / HTML-CSS / Javascript
- Base de données MySQL
Je me suis un peu penché sur le NoSQL qui me permettra d'effectuer les opérations suivantes :
- Optimisation de la BDD pour une volumétrie de données très importante
- Réplication
- Possibilité de Big Data
--> MongoDB est sûrement le moteur NoSQL que je vais utiliser, mais j'ai plusieurs questions :
- Puis-je garder ma BDD locale en MySQL et ma BDD globale en MongoDB ?
- Si oui, dois-je utiliser des outils comme Tungsten Replicator pour passé de l'un à l'autre ? Possibilité de convertir données MySQL vers NoSQL et vice-versa ?
- Me conseilleriez-vous plutôt d'autres moteurs NoSQL ? (A savoir que c'est pour du stockage d'informations sur des animaux, formulaires, ...)
Merci beaucoup si vous avez pris le temps de lire jusqu'ici et j'attends avec beaucoup d'impatience de pouvoir en discuter avec vous !
 Répondre avec citation
Répondre avec citation









Partager