









Bonjour,
J'essaie de faire tourner un code issu d'un livre sur des données réelles (textuelles) et j'ai l'erreur suivante :
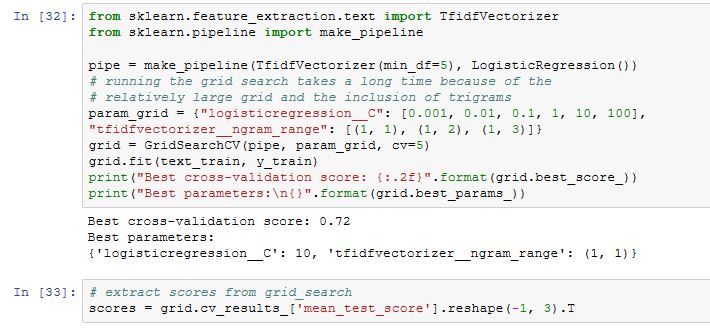
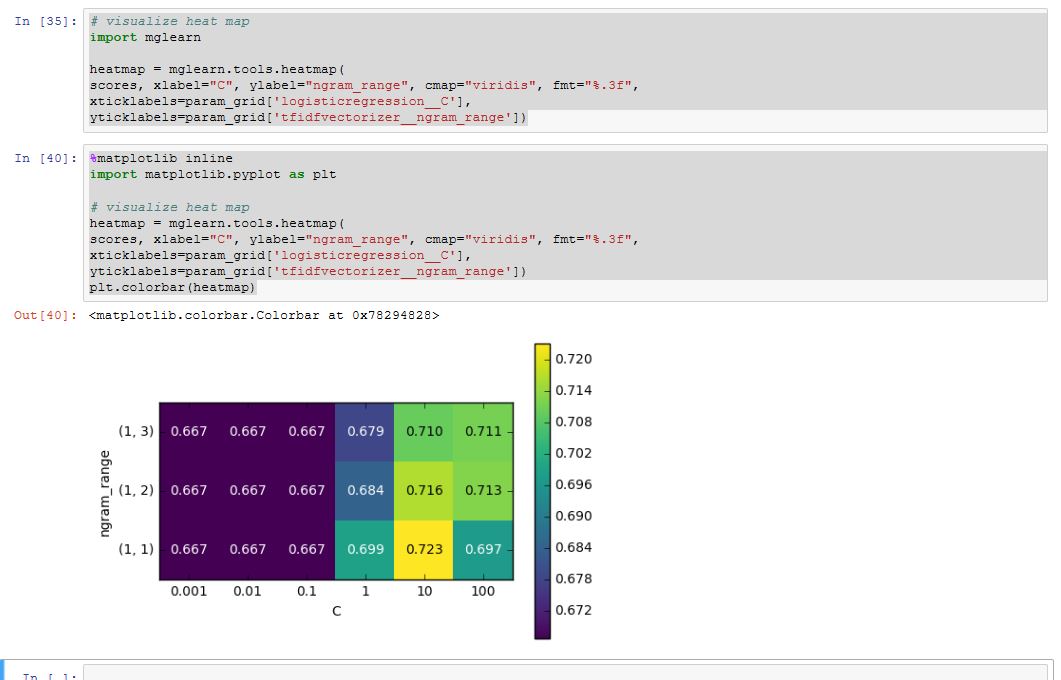
Le but est d'afficher l'évolution du tx de bien classé selon mes parametres (C / mot unique, bigrams et trigrams) sur mon echantillon test.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
Voici le code associé :
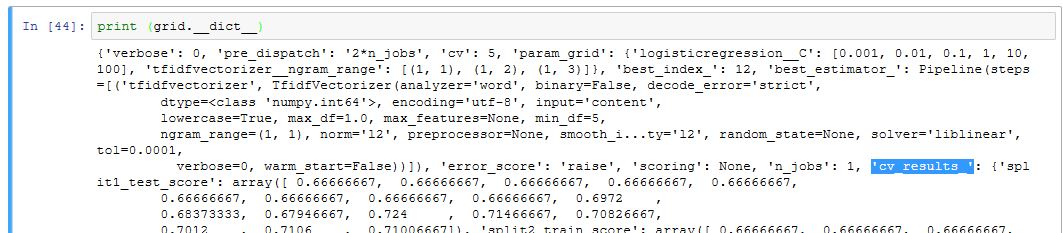
Si qqn a une idée ? j'ai testé ajouter l'option refit=True dans la fonction GridSearchCV() sans succès.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression()) param_grid = {'logisticregression__C': [ 0.001, 0.01, 0.1, 1, 10, 100],# "tfidfvectorizer__ngram_range": [(1, 1),(1, 2),(1, 3)]} # grid = GridSearchCV(pipe, param_grid, cv=5) grid.fit(text_train, Y_train) # extract scores from grid_search scores = grid.cv_results_['mean_test_score'].reshape(-1, 3).T
Vous remerciant par avance.
Cdlt,
 Répondre avec citation
Répondre avec citation





 ,
,  et les
et les 




Partager