









Bonjour,
Premièrement cette discussion est peut être à ranger dans Merise plus que dans Mysql donc si c'est le cas veuillez m'en excuser.
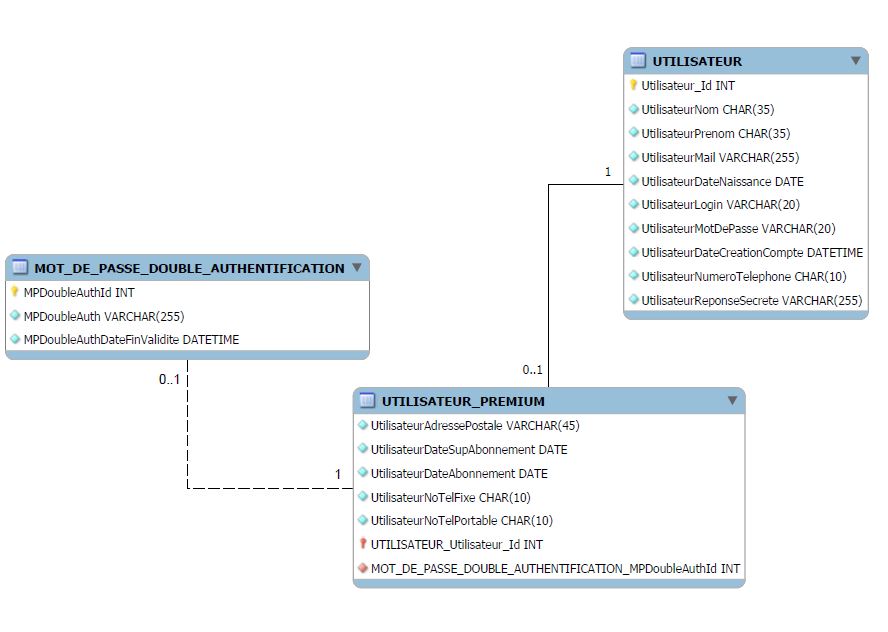
Je suis en train de modéliser sur workbench et j'ai un incompréhension que vous allez facilement lever.
Cela se situe au niveau du Mot de passe pour la double authentification. Je l'ai mis sur une table à part car comme il est censé changer souvent par rapport aux attributs de la table Utilisateur Premium (de ce que j'en ai lu lors de mes recherches sur divers forums mais est-ce exact pour autant?). Entre les tables "Utilisateur Premium" et " Mot de passe double authentification" quand je mets une relation identifiée j'ai obligatoirement la clé étrangère qui passe en clef primaire et je ne comprends pas pourquoi car je peux identifié une ligne de la table sans cette clé (d'après moi bien sûr)
Merci de votre aide!
 Répondre avec citation
Répondre avec citation









 de mon aide, vous pouvez cliquer sur
de mon aide, vous pouvez cliquer sur  .
.

Partager