











Pourquoi Google a-t-il opté pour l'emploi d'un seul code base comme modèle de gestion de sources ?
Un de ses ingénieurs explique
Rachel Potvin, Engineering Manager Google, a expliqué la raison pour laquelle Google utilise un seul code base. « De prime abord, certains dentre vous se disent probablement que cest insensé » reconnait-elle.
Pour faire valoir les bénéfices dune telle stratégie, elle a évoqué sa propre expérience : « jai débuté ma carrière dans lindustrie du jeu vidéo où jai travaillé comme développeur logiciel pendant plusieurs années. Et, à cette période, lentreprise pour laquelle je travaillais avait lhabitude de bosser sur plusieurs jeux vidéo au même moment et chaque jeu était sur son propre dépôt. Il arrivait souvent que ces jeux soient conçus à partir des mêmes moteurs. Aussi, nous avions une copie du code du moteur dun jeu dans chacun de nos dépôts ». Si ces jeux allaient évoluer de manière indépendante, certains managers ont décidé que dans le cas où une fonctionnalité devait être implémentée dans un code base devait également être portée dans les autres. Elle a qualifié ce processus de difficile.
Bien des fois chez Google, la question de savoir sil fallait diviser ce code base géant en plusieurs code base sest posée, mais à chaque fois lentreprise a décidé de garder un seul code base et dinvestir dans lévolutivité. Pourquoi ? Elle a présenté les avantages et les inconvénients.
Avant dentrer dans le vif du sujet, Google a dabord présenté les statistiques de son dépôt : 1 milliard de fichiers, 9 millions de fichiers source, 2 milliards de ligne de code, un historique de 35 millions de modifications (45 000 par jour en moyenne 15 000 effectués par des humains, 30 000 par des systèmes automatisés) pour un poids total de 86 Téraoctets.
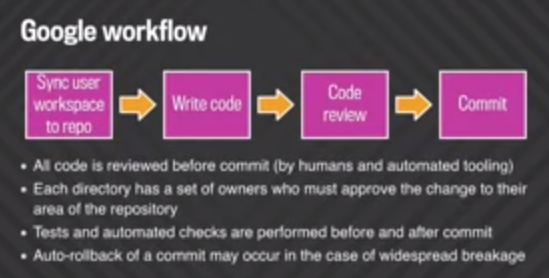
Lentreprise a également présenté son workflow. Le code est dabord examiné avant dêtre porté dans le dépôt (par des humains ou des outils automatisés). Chaque fichier a un ensemble de propriétaires qui doivent approuver les changements effectués dans leur zone sur le dépôt. Des tests et des vérifications automatisées sont effectués avant et après le portage. Une restauration automatique dune modification pourrait arriver en cas de plantage généralisé. Parmi les outils à la disposition des Googlers figurent Critique (pour examiner le code), Tricorder (pour des analyses statiques de la surface du code dans Critique) ou encore TAP (une infrastructure de tests complets avant et après les portages).
Après avoir donné tous ces éléments, Google cite quelques avantages, notamment :
- Un versioning unifié ;
- Un partage et une réutilisation extensifs du code ;
- Une gestion simplifiée de la dépendance ;
- Des changements au niveau atomique ;
- Un refactoring à grande échelle et une modernisation du code base ;
- Une collaboration entre les équipes ;
- Des limites déquipe et une possession du code flexibles ;
- Une visibilité du code et une arborescence claire qui fournissent un espace de noms implicite déquipe.
Les inconvénients, quant à eux, sont essentiellement relatifs aux coûts associés à ce modèle mais également à la complexité du code base
En conclusion, Google estime que ce modèle de gestion de source marche bien lorsquil est accompagné dune culture dingénierie de transparence et de collaboration. Si Google a beaucoup investi sur les outils dévolutivité et de productivité afin de soutenir ce modèle à cause des avantages significatifs quil en retire, lentreprise reconnaît que cette approche pourrait ou pas être la meilleure approche pour votre entreprise. Rachel Potvin et un de ses collègues ont écrit un article à ce sujet qui va plus en profondeur et qui sera publié « plus tard au courant de cette année ».
Source : YouTube
Et vous ?
Qu'en pensez-vous ?






 Répondre avec citation
Répondre avec citation



















Partager