1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'APA01'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'APA01'),
'SEC01', 'Section 1' ;
INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'APA01'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'APA01'),
'SEC02', 'Section 2' ;
INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'APA01'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'APA01'),
'SEC03', 'Section 3' ;
INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'APA02'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'APA02'),
'SEC01', 'Section 1' ;
INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'DSK01'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'DSK01'),
'SEC01', 'Section 1' ;
INSERT INTO SECTION (ServiceId, SectionId, SectionCode, SectionLibelle)
SELECT (SELECT ServiceId FROM SERVICE WHERE ServiceCode = 'DSK01'),
(SELECT COALESCE(MAX(SectionId), 0) + 1
FROM SERVICE AS x JOIN SECTION AS y ON x.ServiceId = y.ServiceId
WHERE x.ServiceCode = 'DSK01'),
'SEC02', 'Section 2' ;
SELECT '' AS 'SECTION', * FROM SECTION ; |













 Répondre avec citation
Répondre avec citation


 .
. et
et  permettent aux forumeurs de cibler leur recherche dans une discussion : n'hésitez pas à voter !
permettent aux forumeurs de cibler leur recherche dans une discussion : n'hésitez pas à voter !








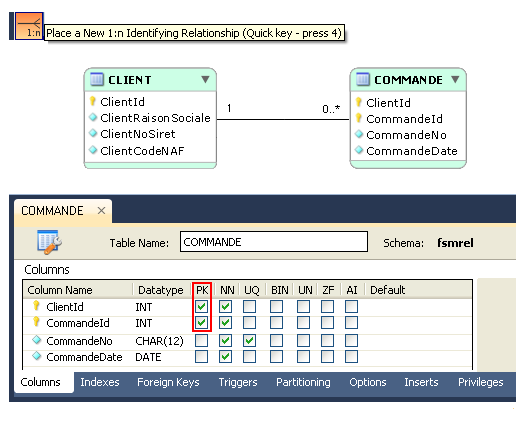
_MLD.png)



.png)

Partager