










Facebook sort Presto, son moteur de requêtes open source pour le big data
qui serait dix fois plus performant que celui de Hadoop
De nombreuses entreprises comme Facebook dépendent du Big data. Dans le domaine, on compte la paire Hadoop/Hive parmi les références. Pour rappel, Hive cest le moteur de requêtes populaire pour Hadoop.
Cependant, il se pourrait que le MapReduce élément essentiel sur lequel repose Hive ne soit pas optimisé pour des situations ou la quantité de données excède un certain seuil. En effet, la latence deviendrait ainsi élevée pour les requêtes effectuées avec Hive.
Les ingénieurs de Facebook, ayant cherché sans succès une solution de remplacement de Hive, en sont venus à créer leur propre moteur de requêtes open source écrit en Java, quils ont baptisé « Presto ».
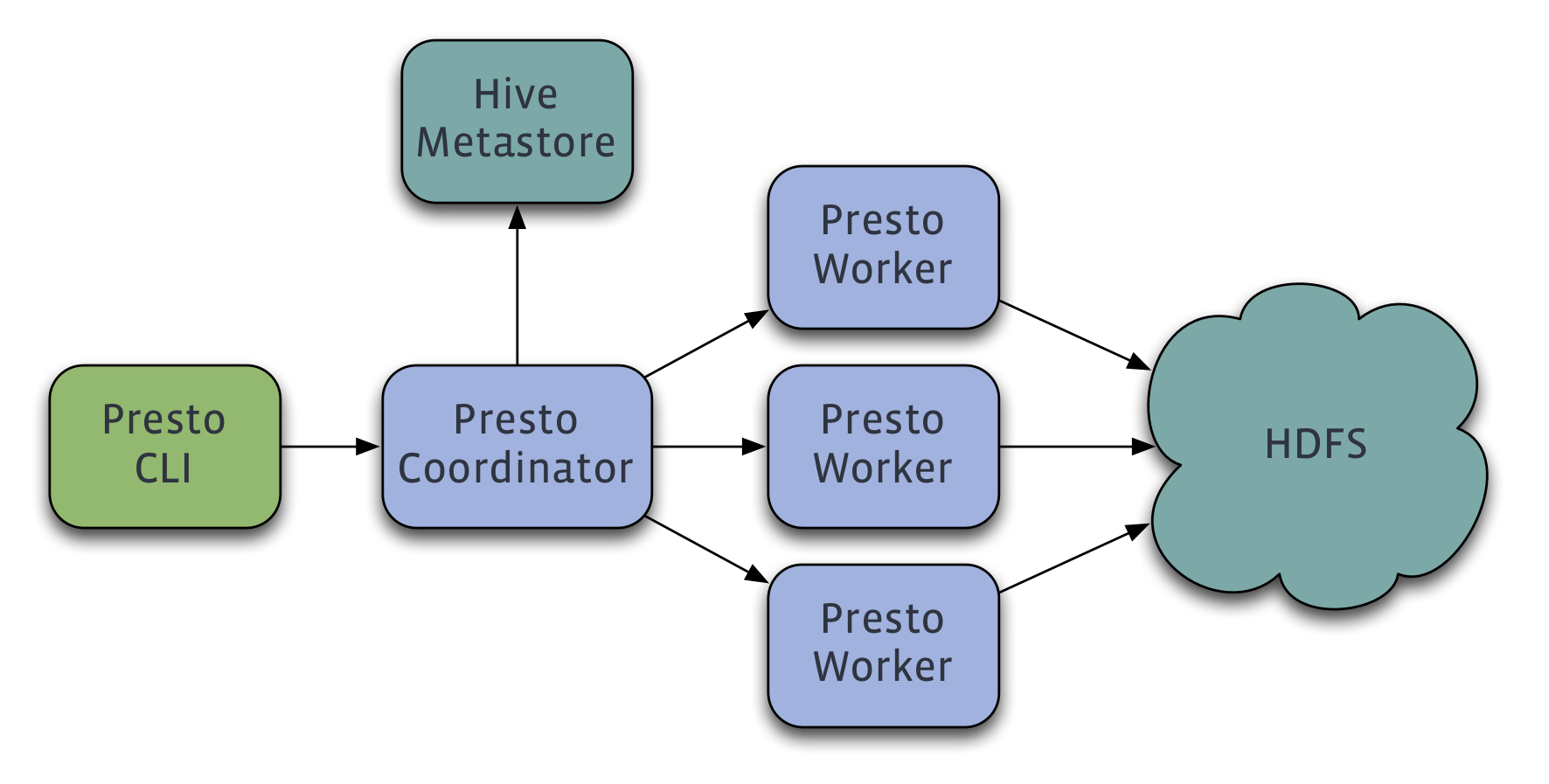
Presto diffère de Hive sur plusieurs points, bien que leurs clusters présentent tous les deux des architectures assez similaires (il y a toujours au moins un nud maître et des nuds esclaves).
Presto implémente une méthode personnalisée de distribution de tâche au sein de son cluster, qui nest pas basée sur MapReduce. De plus, il utilise un langage de requête compatible ANSI SQL.
Selon les ingénieurs du réseau social, Presto serait dix fois plus performant quHive en termes de réduction de charge sur le CPU, ainsi que la diminution de la latence pour les requêtes (raison pour laquelle il a dailleurs été conçu).
Pour les mois à venir, léquipe de développement de Presto annonce travailler pour la création de connecteurs pour les solutions Hbase, Scribe et bien dautres.
Télécharger Presto
Source: Facebook
Et vous ?
 Répondre avec citation
Répondre avec citation



















Partager