
Envoyé par
YoniBlond

Je comprends mieux comment appliquer l'héritage merci !
Cependant je ne vois toujours pas l'intérêt de cette méthode, on gagne un peu de temps et on simplifie la création de la base d'accord (quoiqu'avec la gestion des vues, ça se vaut). Mais au niveau utilisation même si les performances restent acceptables, je ne vois pas en quoi c'est un avantage ?
Je ne sais pas ce que vous voulez dire par « gagner un peu de temps ». Quoi quil en soit, quand on modélise les données, on ne cherche pas à gagner du temps. Sil sagit du temps passé à modéliser, largument est sans objet. Mieux vaut réfléchir un peu plus lors de la conception plutôt quavoir à rattraper le coup une fois la base de données en production. Sil sagit de la performance des applications, CInephil vous a expliqué que la jointure (opération relationnelle par excellence) était lobjet de tous les soins de la part des SGBDR. Si elle navait pas été rendue performante, ça fait trente ans que ces SGBD seraient passés à trappe. De même, quand vous dites « même si les performances restent acceptables », il sagit là dune appréciation subjective le plus souvent démentie par une observation objective des performances de la base de données, sous réserve bien sûr ce que ces performances aient été optimisées à l'occasion d'un prototypage ad-hoc soigné.
Maintenant, je récapépète : deux scénarios sont en compétition :
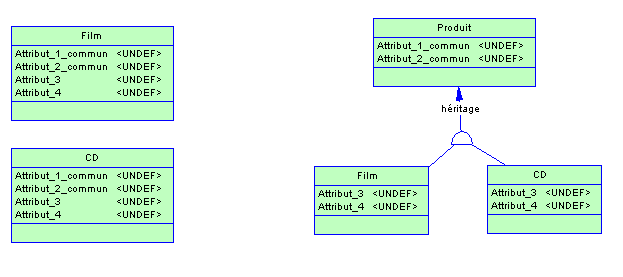
1) Mise en uvre dune table unique Produit, dont un sous-ensemble E1 des attributs est commun à tous les types de produits, un sous-ensemble E2 de ces attributs est spécifique à une catégorie de produits (films) et un sous-ensemble E3 est spécifique à une autre catégorie de produits (CD).
2) Mise en uvre dune table Produit dont les attributs sont ceux du sous-ensemble E1, accompagnée dune table Film dont les attributs sont ceux du sous-ensemble E2 et dune table CD dont les attributs sont ceux du sous-ensemble E3. Les tables Film et CD sont issues dune spécialisation de lentité-type Produit au niveau conceptuel.
Je pense que vous avez compris lintérêt des vues construite à partir de ces tables : indépendance vis-à-vis du modèle sous-jacent. Que vous persistiez dans votre vision mono-table ou que vous vous rangiez à lavis de CinePhil, dans les deux cas vous mettez en uvre une vue ProduitFilm pour que lutilisateur (programme ou terminaliste) ait une vision « Film » des produits et une vue ProduitCD pour que ce même donc utilisateur ait une vision « CD ». Sous le capot, dans le premier cas, les vues correspondent à une projection/restriction (SELECT attr1, attr2, ... WHERE IdType = type) alors que dans le 2e cas, il sagit dune jointure naturelle entre les tables Produit et Film dune part, Produit et CD dautre part).
Dun point de vue fonctionnel, grâce au vues, il ny a donc pas de différence, tant mieux pour lutilisateur final. Si lon passe au niveau physique, la différence est pour le moins radicale, et seul un prototypage des performances permettra de comparer la rapidité dexécution des requêtes (sans oublier que certaines dentre elles peuvent ne concerner que la partie spécifique des produits, auquel cas le système naura pas besoin deffecteur de jointure). Mais un problème préoccupant apparaît quand on utilise une seule table Produit dans laquelle sont mélangés films et CD : à moins dutiliser des valeurs par défaut du type « sans objet » quand tels sous-ensembles d'attributs (à savoir E2 ou E3) ne sont pertinents que pour tel type de produit, les marques « NULL » vont envahir la table Produit et à chaque instant on risque laccident, car la présence du bonhomme NULL peut nous faire prendre des vessies pour des lanternes. En plus, NULL ne permet pas aux optimiseurs des SGBDR de sexprimer pleinement.
Au niveau physique, il y a aussi le problème de la volumétrie, qui a une incidence en termes dorganisation et de coût financier. En ce sens, prenons lexemple dun organisme qui suit les entreprises et leurs salariés. Supposons que lon ait un million dentreprises (table Entreprise) pour dix millions dindividus (table Individu). Supposons que le nombre doctets nécessaire soit le même pour constituer une ligne Entreprise ou une ligne Individu, disons 200 octets, dont une quarantaine correspondent aux attributs communs. A peu de choses près, la consommation en espace est de lordre de 4 gigaoctets si lon nutilise quune table et 2,2 gigaoctets, soit près de deux fois moins si lon a trois tables. Est-ce intuitif ? Lécart peut devenir plus important quand le nombre doctets spécifiques est plus important dans le cas des entreprises. Il faut aussi tenir compte de loccupation des index, etc., etc.
Vous me direz que 4 GO ou 2 GO, ça nest pas grand-chose. Mai si on utilise plusieurs fois le même scénario dans la base de données, ça peut devenir préoccupant. Et puis les productions informatiques qui courent après le temps préfèrent gérer plusieurs petites tables quune grosse (parallélisation des tâches de service, telles que sauvegardes et réorganisations).En vrac, sont encore à prendre en compte certains effet secondaires, tels que les phénomènes de contention (verrouillage) plus fréquents avec une table unique.
Mais bon, ce ne sont que des considérations dordre physique et vous préférerez en revenir au niveau sémantique. Vous observerez dans le MCD ci-dessous, que la version dans laquelle lentité-type Personne est « repliée » (version « Sans héritage », souffre de certains défauts par rapport à la version dans laquelle Entreprise et Individu sont mis en évidence (version « Héritage »). Par exemple, comment prendre en compte le fait quune entreprise emploie au moins un individu ? Quun individu est nécessairement employé par une entreprise ? Quun individu a au moins un élément de paye ? Et au niveau tabulaire, ça devient de moins en moins jojo (par exemple, clés étrangères dont les colonnes sont marquées NULL) sans parler de la surcharge de programmation...
Both.jpg)
A vous de voir.













 Répondre avec citation
Répondre avec citation
















Partager