


Bonjour,
je cherche un moyen de supprimer tous les accents d'une chaîne de caractères.
J'ai trouvé des fonctions pour Delphi, mais je n'ai rien trouvé jusqu'alors qui fonctionne sous Lazarus.
Quelqu'un a-t-il une solution ?
Merci d'avance.
Ben
Inscrivez-vous gratuitement
pour pouvoir participer, suivre les réponses en temps réel, voter pour les messages, poser vos propres questions et recevoir la newsletter


Bonjour,
je cherche un moyen de supprimer tous les accents d'une chaîne de caractères.
J'ai trouvé des fonctions pour Delphi, mais je n'ai rien trouvé jusqu'alors qui fonctionne sous Lazarus.
Quelqu'un a-t-il une solution ?
Merci d'avance.
Ben
Dernière modification par Alcatîz ; 22/01/2017 à 13h22. Motif: préfixe



Salut,
j'ai regardé pour t'aider mais il y a un soucis avec les chaines de caractères sous Lazarus...
si je fait:
avec chaine et i bien initialisés et bien ça donne une boite de dialogue vide...
Code : Sélectionner tout - Visualiser dans une fenêtre à part Showmessage(chaine[i]);
Edit: ah non, c'est les accents qui posent problème sinon chaine[i] fonctionne...
je n'ai pas constaté de problème de ce genre.
je viens de tester ceci
tous les caractères sont bien repris.
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
effectivement avec un TEdit ça fonctionne...
essaye ça alors:
c'est pas de moi je l'ai trouvé sur ce forum
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
chez moi ça donne 'A?A?A'...
Edit: ça donne 'éàèù', rien (boite vide) puis 'A?A?A'
bonjour,
il me semble que j'avais tester une méthode de ce type et que j'avais eu des résultats du même genre que quoi...
je vais refaire des tests ce soir.
ben














Bonjour !
Le sujet avait été traité, par exemple, dans cette discussion :
http://www.developpez.net/forums/d14...ne-fonctionne/
Je viens de tester rapidement la solution que j'avais proposée à l'époque mais j'ai l'impression qu'elle ne fonctionne plus avec Lazarus 1.6.2.
Malheureusement je n'ai pas le temps de me pencher davantage sur le problème aujourd'hui. En espérant vous avoir mis quand même sur la piste d'une solution...
Mon site personnel consacré à MSEide+MSEgui : msegui.net


Bonjour,
Voici la fonction que j'utilise (posté dans sources/tri stringlist)
Cordialement
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
Thierry

A partir de Lazarus 1.6 et FPC 3.0 il ne faut plus utiliser AnsiToUTF8 ou UTF8ToAnsi pour convertir explicitement une chaîne entre Ansi et UTF8.Envoyé par Roland Chastain

A la place il faut utiliser WinCPToUTF8 et UTF8ToWinCp de l'unité LazUtf8 :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Faux en ce qui concerne '' (majuscule) qui ne commence pas par $C3 mais est codé #$C5#$B8
Bonjour DomDA91,
Tu as raison, mais j'ai bien précisé que la fonction ne traitait que la table latin BASIC.
'' fait partie de la table latin EXTENDED.
Je reconnais donc que mon code ne prend en charge que les caractères latins les plus usités.
Cordialement
Thierry
je vous remercie de vos réponses.
je teste tout ça ce soir")

Il y a l'API FoldString qui permet de faire cela assez facilement. FoldString(MAP_COMPOSITE) va décomposer chaque caractère de la chaîne en son caractère de base et son accent. Une boucle permet ensuite de ne conserver que les caractères.
Un exemple ici.
FoldString, n'est-ce pas une fonction de l'API Windows ? Si c'est le cas ça risque de ne pas être multi-plateforme et benoit1024 est peut-être sous un autre OS.
je n'avais pas précisé l'os, j'alterne entre windows et linux. je recherche donc effectivement une solution mulit plateforme.
je viens de tester ce code, cela ne fonctionne pas.
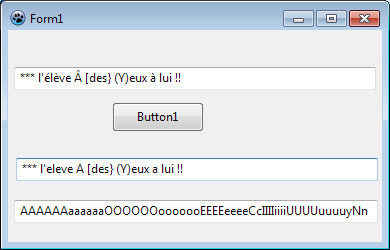
je récupère '*** l'aela" au lieu de ***' l''eleve A [des} (Y)eux a lui !!'
par contre, le code suivant fonctionne correctement :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
gros merci à tous de votre aide
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59


Hello,
il y a aussi la fonction removediacritics qui se trouve dans la bibliothèque rutils de Silvioprog :
1 - Télécharger le fichier zip qui se trouve iciSome general purpose routines on string conversions, parsings, encodings and others.
Most of them are writen in low level programming which assures high performance and responsiveness.
2 - N'extraire que le fichier rutils.pas et le mettre dans le répertoire de son projet.
Exemple d'utilisation :
et voici le résultat :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
Ami calmant, J.P
Jurassic computer : Sinclair ZX81 - Zilog Z80A à 3,25 MHz - RAM 1 Ko - ROM 8 Ko


bonjour,
et chaque fois que je vois ce genre de question, je me pose la même question : mais pourquoi ?
À partir du moment où l'accent a pleine valeur orthographique, pourquoi vouloir le(s) supprimer ?
Une praline et un praliné, ce n'est pas la même chose, alors si quelqu'un pouvait m'expliquer...
Parce que sans accents ça risque d'être top, dans une BdD de stock, genre
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
Il a à vivre sa vie comme ça et il est mûr sur ce mur se creusant la tête : peutêtre qu'il peut être sûr, etc.
Oui, je milite pour l'orthographe et le respect du trait d'union à l'impératif.
Après avoir posté, relisez-vous ! Et en cas d'erreur ou d'oubli, il existe un bouton « Modifier », à utiliser sans modération
On a des lois pour protéger les remboursements aux faiseurs dargent. On nen a pas pour empêcher un être humain de mourir de misère.
Mes 2 cts,
--
jp



Bonjour Jipété,
Tu as entièrement raison s'il s'agit de l'affichage des chaînes, mais leur traitement est parfois simplifié si les caractères accentués sont ramenés à des caractères présents dans le corps originel ASCII. Je pense notamment au tri alphabétique : essaye de trier directement des mots accentués avec Lazarus.
PS : Je précise que Delphi trie correctement sans ce subterfuge.
Bonjour Gilles,
Je te laisse imaginer les subterfuges à mettre en uvre avec les mots modelé et modèle,tu vas te retrouver avec deux fois modele et attention les doublons, nécessaires cette fois !
Bonjour la prise de tête, car ça va obliger à quand même stocker la string accentuée pour l'afficher (et l'imprimer [factures, devis...]) correctement, hé oui...
OK, je ne connais rien aux BdD, mais je sais quand même qu'il y a des index (numériques, je suppose), et que le traitement serait grandement simplifié en les utilisant plutôt que de jongler avec modele01, modele02, ou praline01 praline02...
Bon courage à ceux qui doivent s'y coller !
Il a à vivre sa vie comme ça et il est mûr sur ce mur se creusant la tête : peutêtre qu'il peut être sûr, etc.
Oui, je milite pour l'orthographe et le respect du trait d'union à l'impératif.
Après avoir posté, relisez-vous ! Et en cas d'erreur ou d'oubli, il existe un bouton « Modifier », à utiliser sans modération
On a des lois pour protéger les remboursements aux faiseurs dargent. On nen a pas pour empêcher un être humain de mourir de misère.
Mes 2 cts,
--
jp
jurassic pork, merci pour ta solution, je vais tester ça
Jipété il y a de nombres raison de vouloir supprimer ce type de caractères.
j'en ai besoin ici pour renommer des noms de fichiers. il y a encore de nombreux cas où les fichiers contenant des accents posent problème.
encore merci à tous pour vos réponses")
je confirme que cette méthode fonctionne parfaitement.
c'est celle qque je vais utiliser.
bon dèv à tous
En fait toutes les méthodes proposées fonctionnent. Il est à noter toutefois que la méthode proposée par Andnotor convient pour un mot, mais pas pour un texte, car elle supprime tout caractère qui n'est pas alphanumérique.
Je me suis amusé à faire une petite application qui permet d'essayer les différentes méthodes.
Mon site personnel consacré à MSEide+MSEgui : msegui.net

Vous avez un bloqueur de publicités installé.
Le Club Developpez.com n'affiche que des publicités IT, discrètes et non intrusives.
Afin que nous puissions continuer à vous fournir gratuitement du contenu de qualité, merci de nous soutenir en désactivant votre bloqueur de publicités sur Developpez.com.
 Répondre avec citation
Répondre avec citation

 - Quelqu'un vous a aidé ou vous appréciez une intervention ? Pensez au
- Quelqu'un vous a aidé ou vous appréciez une intervention ? Pensez au 
Partager