










Bonjour,
Un FAE est un filtre qui élimine les fréquences du signal hors Bande Passante utilisée.
Il convient mal à ton cas car il réduit le signal et le retarde.
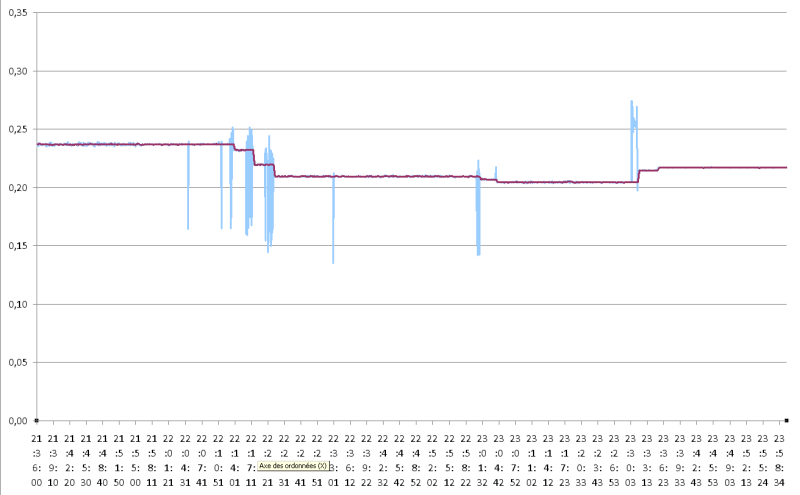
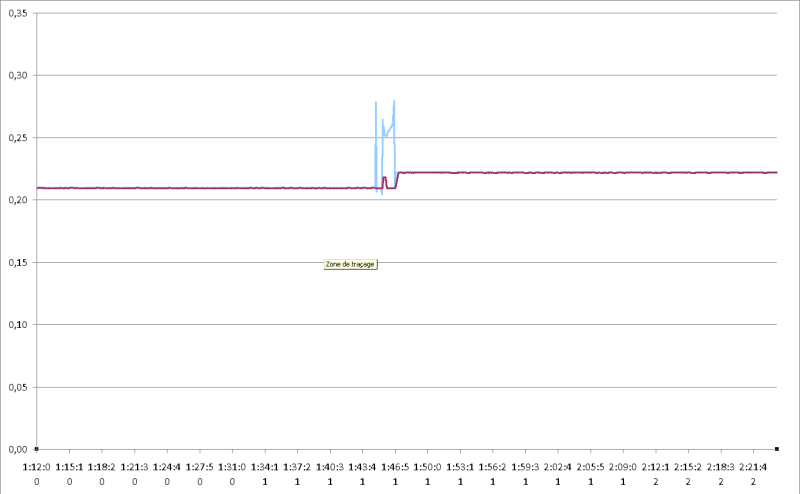
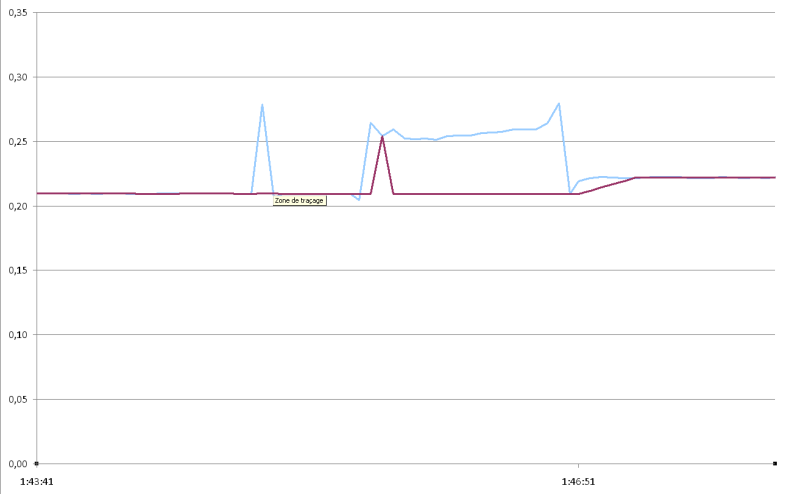
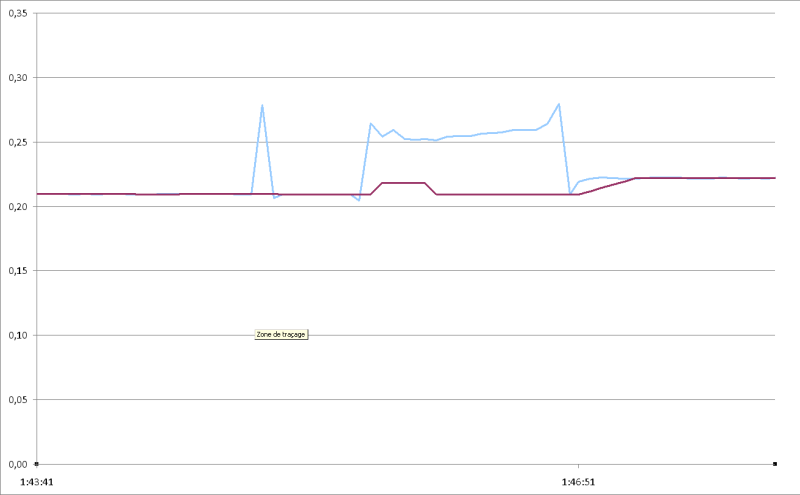
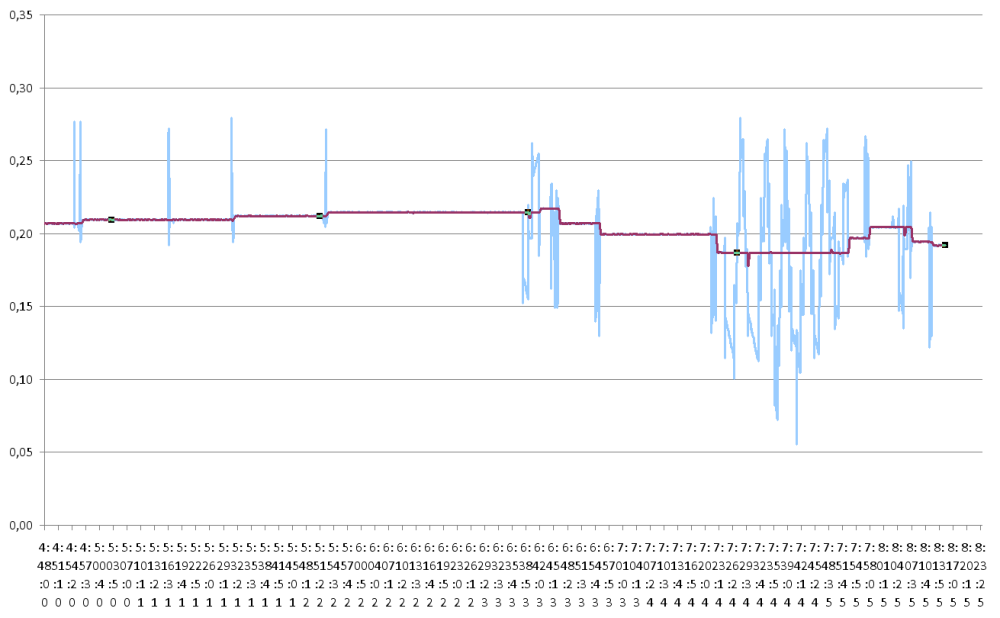
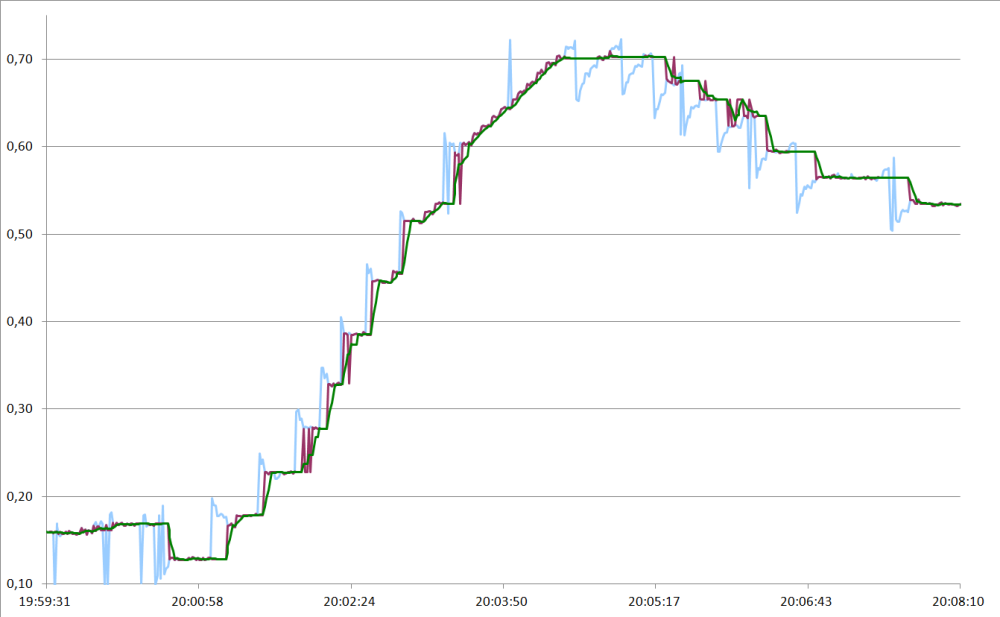
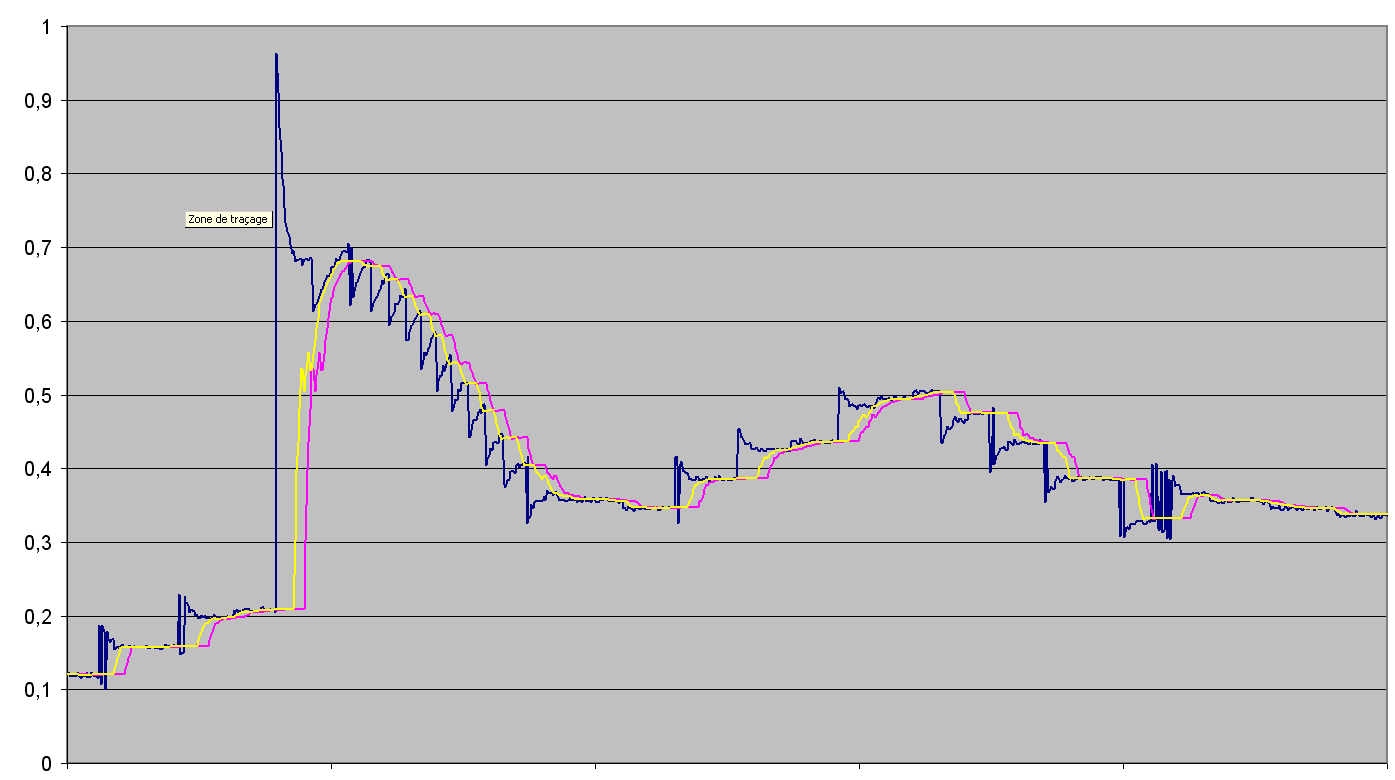
En revanche je te propose un filtre de kalman stationnaire (gains fixes) d'ordre deux en testant l'innovation.
Cela ne prend que 8 instruction de calculs simples.
Un exemple avec excel :
 Répondre avec citation
Répondre avec citation











Partager