1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
| public class Extractor {
// une map qui va associer un mot avec un extracteur de données
private final static Map<String, IExtractor> EXTRACTORS = createMap();
/**
*
* @param path le chemin de fichier
* @param appendable un appendable pour collecter le résultat
* @param words les mots dé début de ligne qu'on veut extraire
* @throws IOException
*/
public Extractor(Path path, Appendable appendable, String...words) throws IOException {
// on ne conserve que les filtres qu'on a sélectionnés
Map<String, IExtractor> extractors = new HashMap<>();
for(String word : words) {
IExtractor extractor = EXTRACTORS.get(word);
if ( extractor!=null ) {
extractors.put(word, extractor);
}
}
// on compte le nombre de ligne
int nb = 0;
try (BufferedReader reader = Files.newBufferedReader(path)) { // Lecture
// fichier
for (String line = reader.readLine(); line != null;) {
nb++; // Compteur nombre de ligne
if (nb > 1)
;
break; // Inutile de lire plus loin
}
}
if (nb == 1) { // si le fichier n'a qu'une seule line
try (BufferedReader reader = Files.newBufferedReader(path)) {
for (String line : reader.readLine().split("\n")) { // on la lit et on la découpe en lignes avec \n
extract(line, appendable, extractors); // on traite chaque sous-ligne
}
}
} else {
try (BufferedReader reader = Files.newBufferedReader(path)) {
for (String line = reader.readLine(); line != null; line = reader.readLine()) {
EXTRACTORS.get("LIN+").extract(line, appendable); // on n'extrait que par le mot LIN+
}
}
}
}
// on construit la map des composants d'extraction
private void extract(String line, Appendable appendable, Map<String, IExtractor> extractors) {
for (Map.Entry<String, IExtractor> entry : extractors.entrySet()) { // on parcourt toutes les associations
if (line.startsWith(entry.getKey())) { // si la clef est le début de la ligne
entry.getValue().extract(line, appendable); // on fait l'extraction associée
break; // on a trouvé la bonne association, on peut arrêter toute de suite et passer à la ligne suivante
}
}
}
// on construit une fois la map
private static Map<String, IExtractor> createMap() {
Map<String, IExtractor> extractor = new HashMap<>();
// on ajoute pour chaque mot, un extracteur associé
extractor.put("LIN+", Extractor::extractLinValue); // dit qu'on appellera la méthode extractLinValue lorsque le mot sera LIN+
extractor.put("RFF+ADE", Extractor::extractRffAdeValue);
extractor.put("RFF+MH", Extractor::extractRffMhValue);
return Collections.unmodifiableMap(extractor);
}
private static void extractLinValue(String line, Appendable appendable) {
try {
extractValue(line, appendable, 4, 0);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private static void extractRffAdeValue(String line, Appendable appendable) {
try {
extractValue2(line, appendable);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private static void extractRffMhValue(String line, Appendable appendable) {
try {
extractValue3(line, appendable);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
// tes trois méthodes, corrigées
private static void extractValue(String line, Appendable appendable, int field, int composite) throws IOException {
int i = 0;
int cptplus = 0;
char first = line.charAt(i);
appendable.append("\n");
appendable.append("Part n° : ");
while (i < line.length()) {
first = line.charAt(i);
i++;
if (first == '+') {
cptplus++;
while (cptplus >= field-- && i< line.length()) {
first = line.charAt(i);
appendable.append(first);
i++;
if (first == '+' || first == '\'' || first == ':') {
appendable.append(" ; ");
break;
}
}
}
}
}
private static void extractValue2(String line, Appendable appendable) throws IOException{ //RFF+ADE-------------SELECTION CHAMP & COMPOSITE--------------//
// ça fonctionne, mais on peut faire mieux, plus concis, plus efficace, et plus logique (voir juste après)
/*
int i=0;
int cptpoint = 0;
char first2 = line.charAt(i);
appendable.append("Supplier code : ");
while (i < line.length()){
first2 = line.charAt(i);
i++;
if(first2 == ':'){
cptpoint++;
while (cptpoint >= 1){
first2 = line.charAt(i);
appendable.append(line.charAt(i));
i++;
if (i >= line.length()){
appendable.append(" ; ");
break;
}
}
}
} */
int cptpoint = 0;
for(int i=0; i<line.length(); i++) {
if ( line.charAt(i)==':' ) {
cptpoint++;
if ( cptpoint>0 ) {
appendable.append(line.substring(++i));
}
}
}
}
private static void extractValue3(String line, Appendable appendable) throws IOException{ //RFF+MH-------------SELECTION CHAMP & COMPOSITE--------------//
// ça fonctionne, mais on peut faire mieux, plus concis, plus efficace, et plus logique (voir juste après)
/*int i=0;
int cptpoint = 0;
char first3 = line.charAt(i);
appendable.append("Fab order : ");
while (i < line.length()){
first3 = line.charAt(i);
i++;
if(first3 == ':'){
cptpoint++; // commenté ne sert à rien
while (cptpoint < 2){
first3 = line.charAt(i); // j'ai commenté ça parce que ça ne sert à rien
appendable.append(line.charAt(i));
i++;
if (i >= line.length()){
appendable.append(" ; ");
break;
}
}
appendable.append(line.substring(i));
}
}*/
int pos = line.indexOf(':'); // recherche position de :
if ( pos>= 0 ) { // si on a trouvé :
appendable.append(line.substring(++pos)); // on récupère ce qui se trouve après :
}
}
private interface IExtractor {
void extract(String line, Appendable appendable);
}
} |











mais le pb avec ça est que si j'appuis une nouvelle fois sur mon bouton ( ce qui veut dire qu'il sera déselectionné ) alors ma_variable ne sera pas null est sera toujours égale à ma_valeur..
 Répondre avec citation
Répondre avec citation





 La plupart des réponses à vos questions sont déjà dans les
La plupart des réponses à vos questions sont déjà dans les 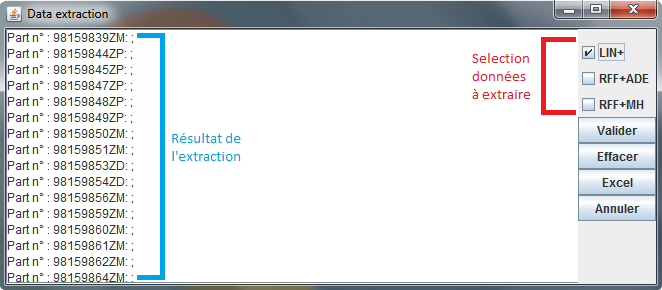


Partager