













Dans la mesure où :
- Ça ne rends pas le MPD plus lisible (au contraire)
- Sans MPD sous les yeux, le développeur doit se poser la question en permanence de comment le concepteur a abrégé commande = cde ou cmd, client = clt ou cli ?
- L'utilisation d'un trigramme porte à confusion pro_id = identifiant de produit, provosion ou provision ?
- Ça alourdi inutilement l'écriture des requêtes (clauses SELECT et WHERE considérablement alourdies)
- Que pour les auto-jointures, donc ne peut pas utiliser le NATURAL JOIN
- Que pour les auto-jointures, on doit préfixer avec un nom de table qui n'existe pas
Je trouve que les avantages de préfixer systématiquement d'un trigramme "juste pour pouvoir utiliser des jointures naturelles" sont plus faibles qu'autre-chose.
Sachant qu'en plus seule une faible minorités de SGBD supportent cette syntaxe (et pour cause, vu qu'elle est aussi inutile qu'intrusive dans la conception et sa syntaxe non stable dans le temps), c'est pas un mal de la connaître, mais pas franchement un plus de l'utiliser : si c'est pour se coltiner des USING à chaque fois, aucun intérêt, et si on se passe d'un USING, on prend le risque d'avoir des requêtes qui se mettent à déconner à chaque modification du modèle des données.
Autant utiliser des INNER JOIN sur des noms de colonne explicites, et éviter de se coltiner des noms de colonne à rallonge inutilement.
Après, ça reste de la règle de nommage, donc les goûts et les couleurs... mais en attendant, j'ai plus souvent vu de la merde avec des concepteurs adeptes du trigramme qu'avec des adeptes des noms purement sémantiques et des jointures explicites.
Genre ça, désolé, mais moi je vomi :
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
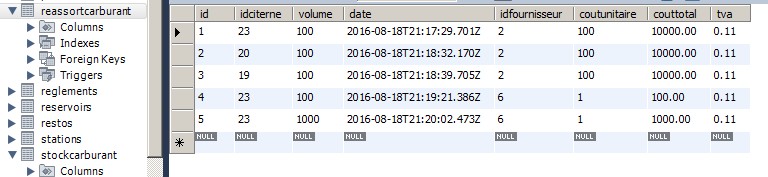
Dans le jeu de résultat, on n'a aucune certitude d'où vient chaque colonne.
Et le jour où je dois ajouter le client livré dans la requête :
WTF ?! comment ça se fait que ça marche pas ouin ouin...
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
Alors que si dès le début on bosse proprement :
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
Et le jour où je dois ajouter le client livré dans la requête :
C'est limpide, naturel et sans surprise pour le développeur : aucun besoin de toucher à la partie déjà existante de la requête.
Code sql : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
 Répondre avec citation
Répondre avec citation


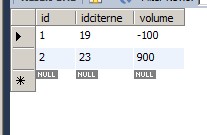
 bah... justement... si !
bah... justement... si !

Partager