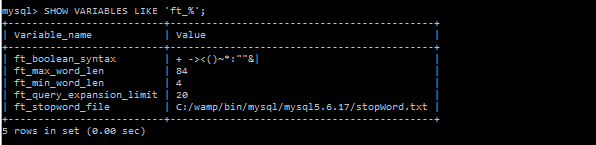
1
2
3
4
5
6
7
8
9
10
11
12
| CREATE TABLE table_test (
id integer NOT NULL,
titre character varying(210),
annee integer,
pays character varying(50),
resume_article text
);
INSERT INTO table_test(titre, annee, pays, resume_article) VALUES
('Blanche-Neige et les Sept Nains', '1937', 'USA', 'L''action débute lorsqu''un jour, la Reine interrogeant son miroir, celui-ci lui répond que la plus belle du royaume est dorénavant la princesse Blanche-Neige'),
('Les Petits Mouchoirs', '2010', 'France', 'Max, riche propriétaire d''un hôtel-restaurant, et sa femme Véro invitent chaque année leurs amis dans leur maison au Cap Ferret pour célébrer l’anniversaire d'Antoine et le début des vacances.'),
('La Reine des neiges', '2013', 'USA', 'Le roi et la reine partent immédiatement voir les trolls dont le roi est capable de guérir Anna.'),
('Au service de Sa Majesté', 'UK', '1937', 'Un mauvais garçon new-yorkais, fuit au Royaume unis en empruntant l''identité de sa victime présumée, un Canadien.'); |











 Répondre avec citation
Répondre avec citation

 de mon aide, vous pouvez cliquer sur
de mon aide, vous pouvez cliquer sur  .
.
 La redirection !
La redirection !









Partager