













Bonjour à tous,
J'ai un problème un peu bizarre sur une requête.
Voici des captures d'écran pour mettre en place le contexte.
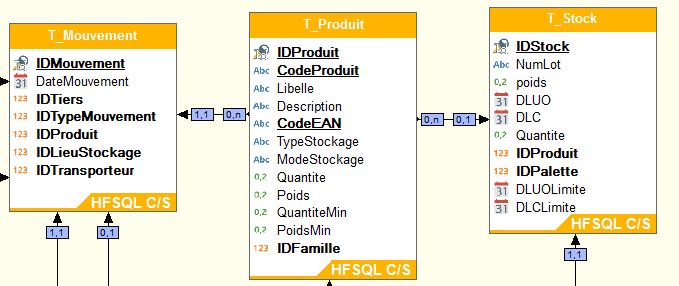
MCD :
Le contenu des 3 tables :
T_Mouvement :
T_Stock
T_TypeMouvement
Ce que je veux : récupérer tout les mouvements de façon unique avec des informations contenues dans d'autres tables.
Ma requête 1 :
Résultat :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
IDProduit CodeProduit Libellé IDTypeMouvement DateMouvement NumLot IDMouvement Poids DLUO DLC 3 07612464336538 Lait UHT 1 11/03/2016 140 3 8 NULL 14/07/2004 3 07612464336538 Lait UHT 1 21/03/2016 140 10 8 NULL 14/07/2004
Ma requête fonctionne comme je le souhaite
Dans ma requête 2 je rajoute le champ "quantité" qui est contenu dans la table "Stock", voici la requête :
Résultat :
Code : Sélectionner tout - Visualiser dans une fenêtre à part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
IDProduit CodeProduit Libellé IDTypeMouvement DateMouvement NumLot IDMouvement Poids DLUO DLC Quantité 3 07612464336538 Lait UHT 1 11/03/2016 140 3 8 NULL 14/07/2004 80,00 3 07612464336538 Lait UHT 1 21/03/2016 140 10 8 NULL 14/07/2004 80,00 3 07612464336538 Lait UHT 1 11/03/2016 140 3 8 NULL 14/07/2004 40,00 3 07612464336538 Lait UHT 1 21/03/2016 140 10 8 NULL 14/07/2004 40,00
Et là le résultat de ma requête s'affiche avec des doublons !!!!!
Je vous remercie bien.



 Répondre avec citation
Répondre avec citation





Partager