Je rejoins Escartefigue sur le fait que le périmètre indiqué par Pieplu est flou.
Combien de langues allez-vous utiliser dans votre base de données ?
Quel est la fréquence des changements de ces libellés ?
Est-ce une personne qui va faire la saisie ou est-ce un fichier langue que vous allez charger dans votre base de données ?
Si c'est une personne, il vous faut un clavier spéciale pour chaque langue.
En chinois, pour créer un seul idéogramme, cela correspond à la frappe de plusieurs touches. Idem pour l'arabe.
Est-ce que ce sont juste des libellés de produits ou est-ce la totalité de votre site (texte, voir image avec texte, logo ...) ?
En général, on utilise de l'UTF-8, mais celui-ci occupe trois octets au maximum pour représenter un seul caractère en mémoire et il n'est pas complet.
Il existe une nouvelle norme le 'UTFMB4' qui utilise jusqu'à quatre octets.
Est-ce que ce jeu de caractères est disponible dans votre SGBDR ? Et en admettant qu'il le soit, est-il complet ?
Et surtout comment allez-vous gérer le sens de la lecture ? En arabe, c'est de droite à gauche.
En chinois traditionnel, je crois que c'est de haut en bas, et de droite vers la gauche, sans ponctuation. Bon maintenant, le chinois se lit comme chez nous.
Il faut savoir qu'un jeu de caractères comme le 'latin1' représente la codification de vos caractères en mémoire.
Le 'latin1' est ce que l'on appelle un jeu de caractères régional, c'est-à-dire propre à un pays. Il est simple car un caractère occupe un seul octet.
Le UTF-8 (jeu de caractères) basé sur l'unicode à pour vocation de regrouper tous les jeux de caractères les plus usités dans le monde.
Ne confondez pas le jeu de caractères avec la police de caractères, qui sert à l'affichage des caractères à l'écran.
Pratiquement, il faut une police de caractères par alphabet utilisé pour vos langues.
Et l'on n'écrit pas de la même façon (je parle du dessin des caractères) du latin et du chinois, par exemple.
Le chinois à l'affichage utilise beaucoup plus de place que le latin. Donc il va falloir aussi gérer l'espacement et l'occupation des caractères à l'écran.
Je m'arrête là. Tout ce que je peux dire, c'est
bon courage ! Car vous allez entrer dans une usine à gaz juste pour gérer plusieurs langues.
@+












 Répondre avec citation
Répondre avec citation












 N'oubliez pas le bouton
N'oubliez pas le bouton  et pensez aux balises [code]
et pensez aux balises [code]





 de mon aide, vous pouvez cliquer sur
de mon aide, vous pouvez cliquer sur 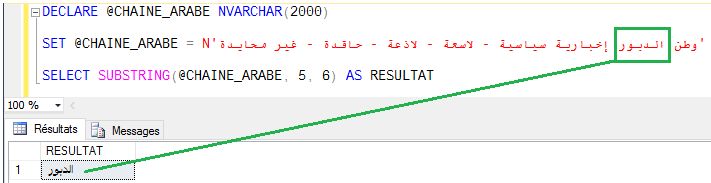




Partager