Bonsoir Krystal,
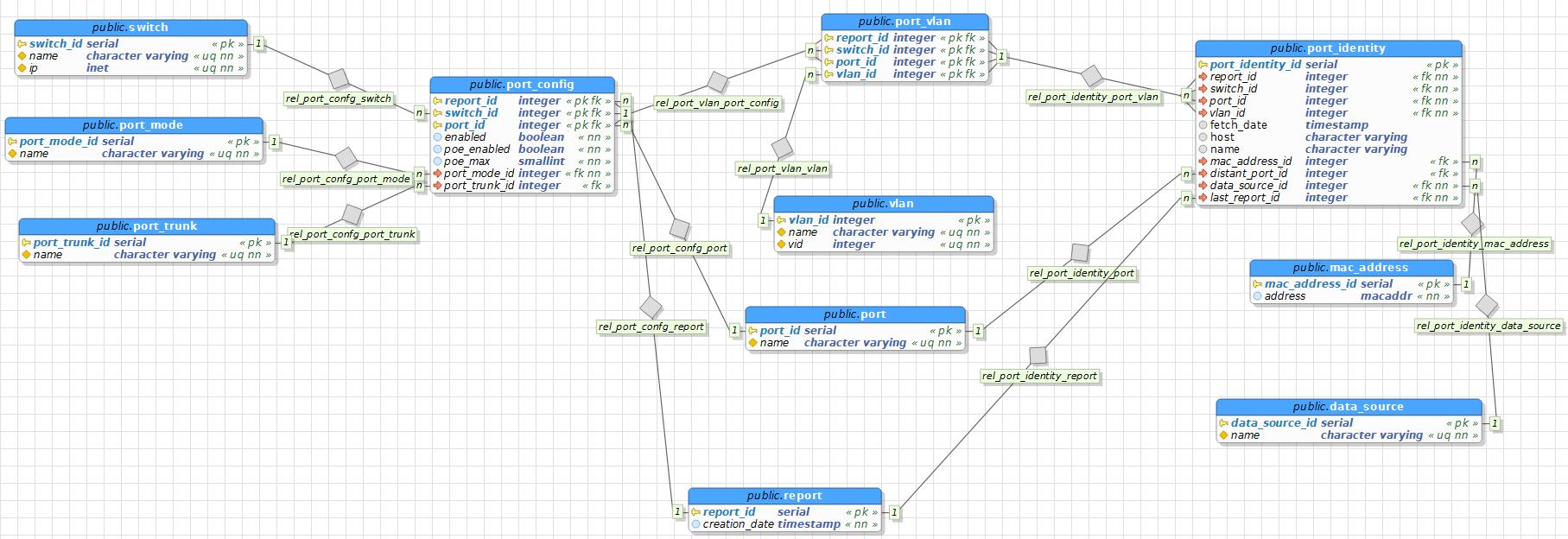
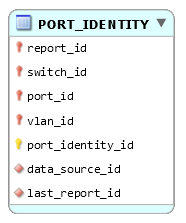
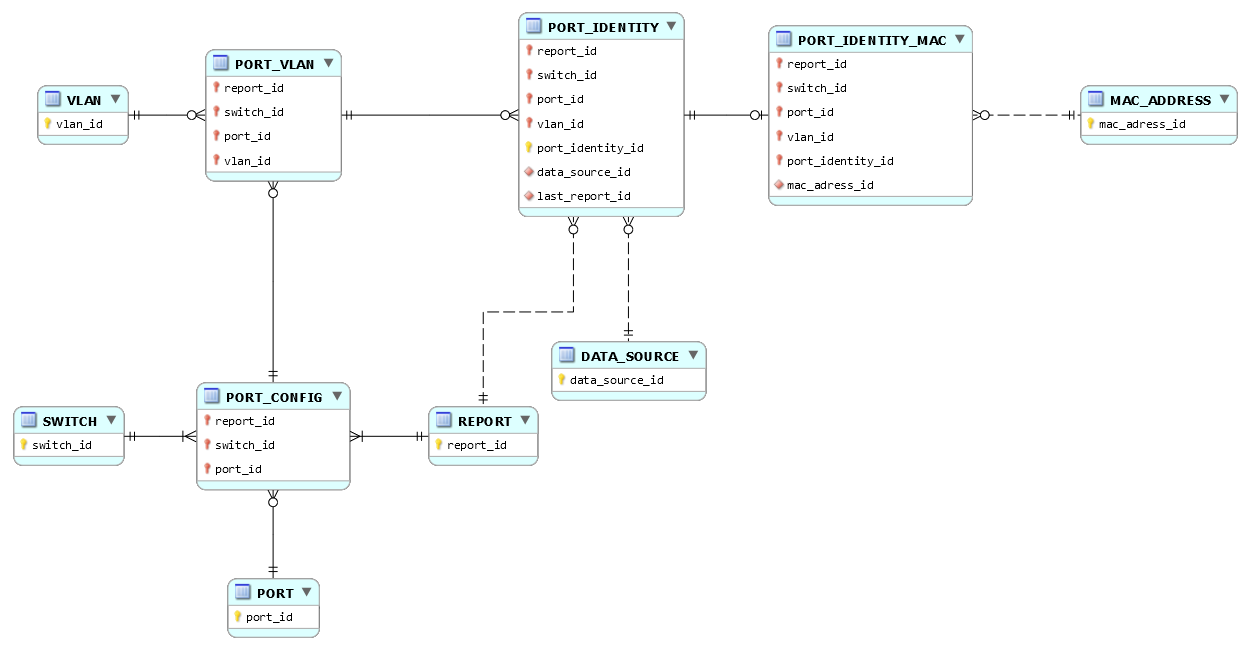
Daccord pour la table PORT_IDENTITY, elle a son existence propre, je la prend en compte et revois ma copie. Cette table a pour clé primaire {port_identity_id}.
A partir de là, mon interprétation est la suivante, dites-moi quand je me trompe... :
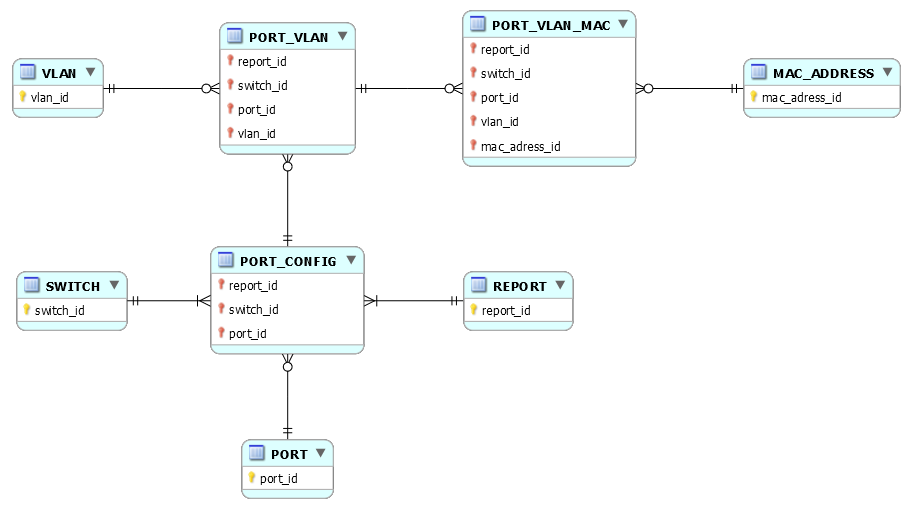
La table PORT_IDENTITY est associée à la table PORT_VLAN. Pour un port_vlan on peut avoir plusieurs port_identity ; pour un port_identity on a au moins un et au plus un port_vlan.
Un port_identity est facultativement associé à au plus une seule mac_address_id (adresse machine) ; une mac_address_id peut être associée à plusieurs port_identity. Puisquun port_identity nest pas nécessairement associé à une mac_address_id, je préfère pour ma part mettre en uvre une table PORT_IDENTITY_MAC (de clé primaire {port_identity_id}) associant les tables PORT_IDENTITY et MAC_ADRESS (exit le bonhomme Null) :
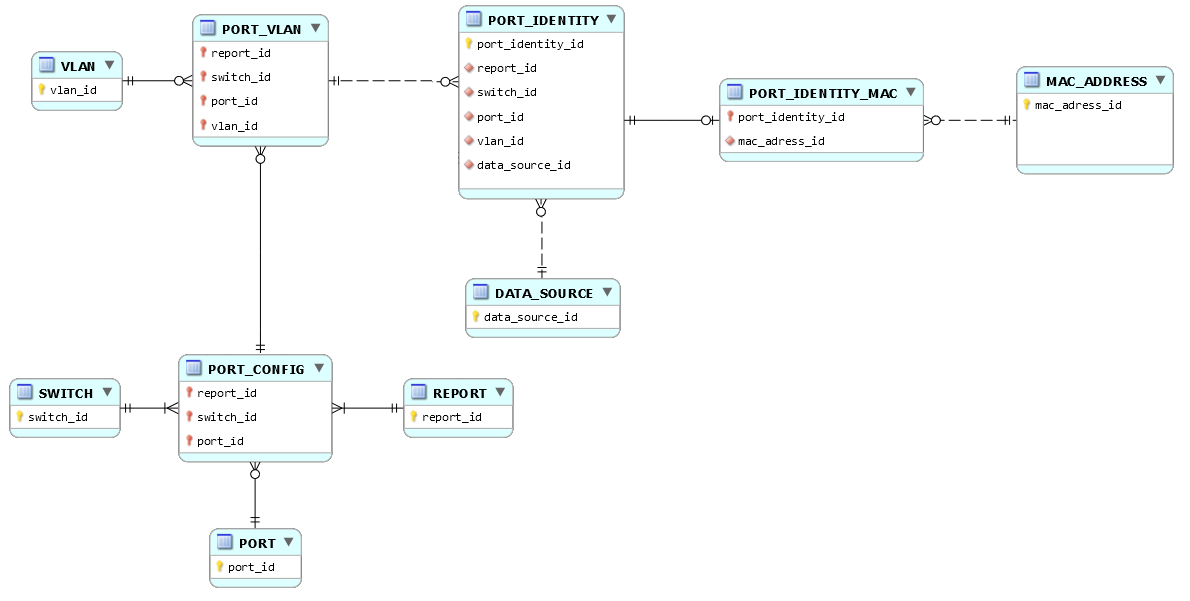
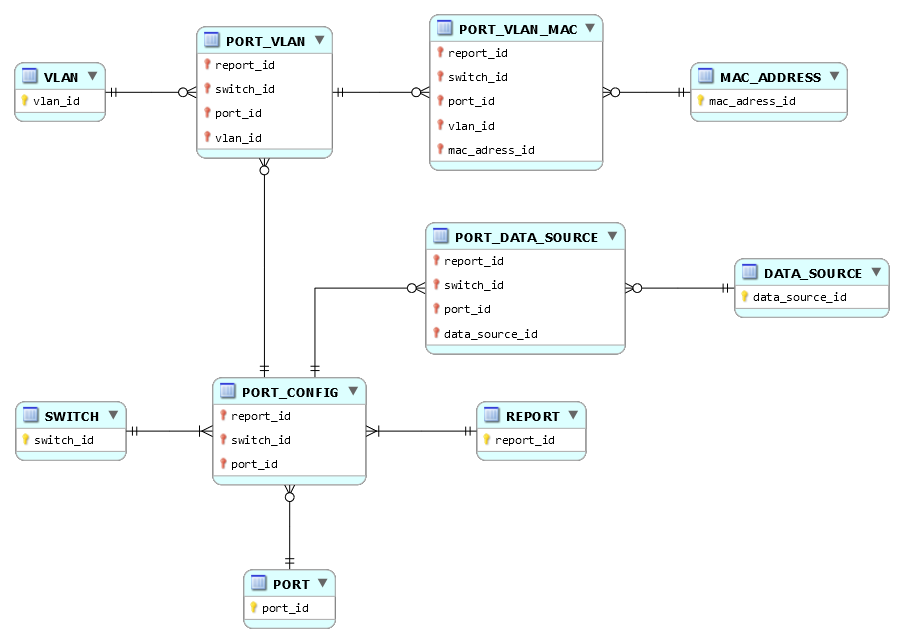
Comme dans votre diagramme, la table DATA_SOURCE est associée à la table PORT_IDENTITY, mais vous écrivez :
Pour chaque adresse MAC précédemment récupérée, je vais interroger différentes DATA_SOURCE
Question : la table DATA_SOURCE ne sert-elle que lorsqu'on connaît ladresse MAC ? Si oui, autant la mettre en relation avec la table PORT_IDENTITY_MAC, sinon elle st à sa place. Quen est-il exactement ?
Vous écrivez aussi :
Pour chaque adresse MAC précédemment récupérée, je vais interroger différentes DATA_SOURCE et chacune d'entre elle peut me donner jusqu'à 4 informations :
fetch_date -> qui correspond à la date de l'information dans la DATA_SOURCE, et n'est en aucune façon liée à la date de la table REPORT ;
host -> qui correspond au nom de l'équipement correspondant à l'adresse MAC ;
name -> qui correspond à un libelle textuel de l'équipement, indépendant de la colonne host, correspondant à l'adresse MAC ;
distant_port_id -> qui correspond au port de l'équipement correspondant à l'adresse MAC qui est connecté au port du switch.
Si ces attributs ne sont valorisés (non marqués Null) que lorsquils sont liés ladresse MAC, ils devraient migrer vers la table PORT_IDENTITY_MAC.
Vous écrivez encore :
Ces 4 colonnes seront ou non null en fonction de la data source dont l'information est issue.
Par exemple :
venant de la data source ARP, les colonnes host et distant_port_id seront null
Venant la data source DHCP, seule la colonne distant_port_id sera null
Venant de la data source LLDP, ... ça dépend! Parfois aucune colonne ne sera null, parfois host et distant_port_id seront null
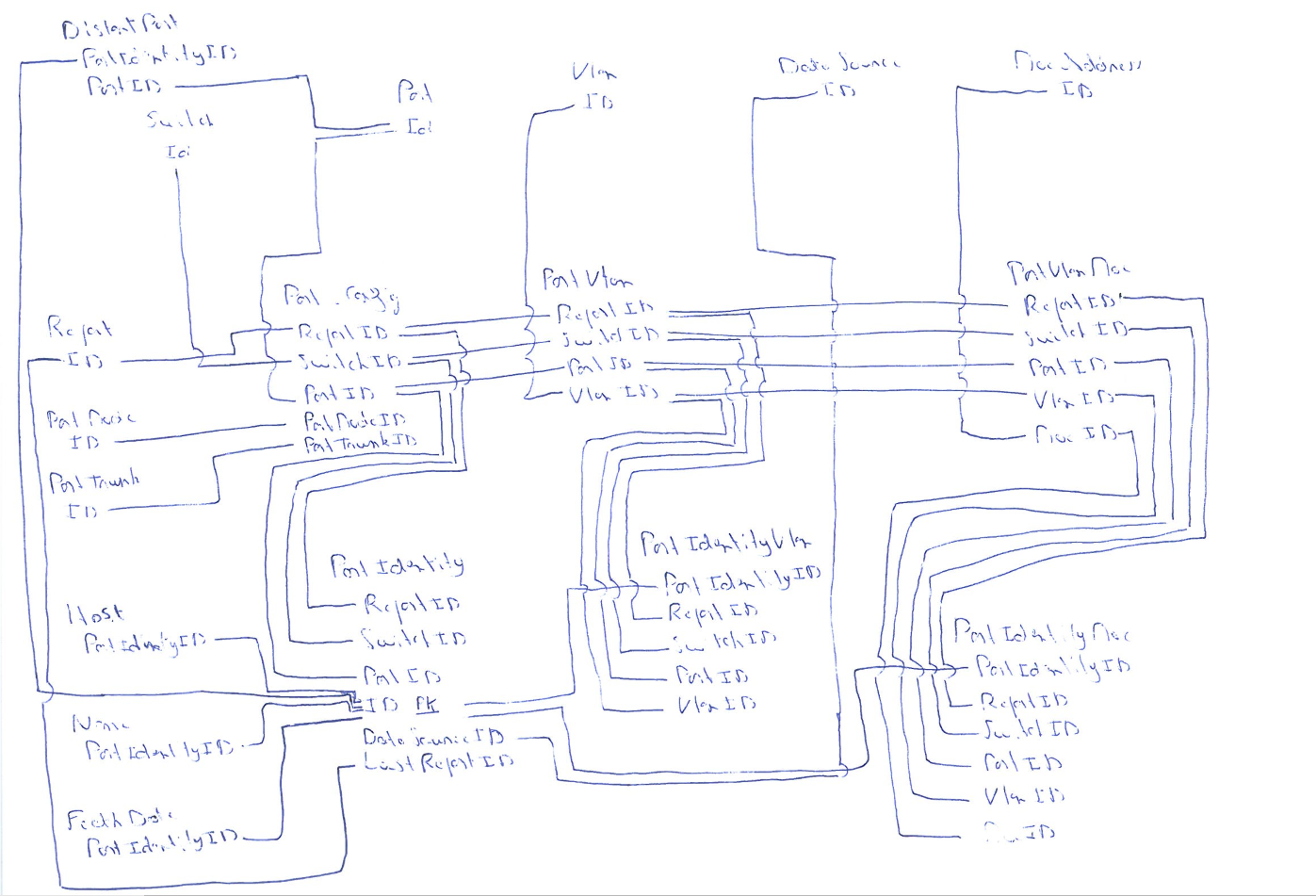
Du point de vue théorique, il faudrait mettre en uvre une table par attribut « nullable », exemple :
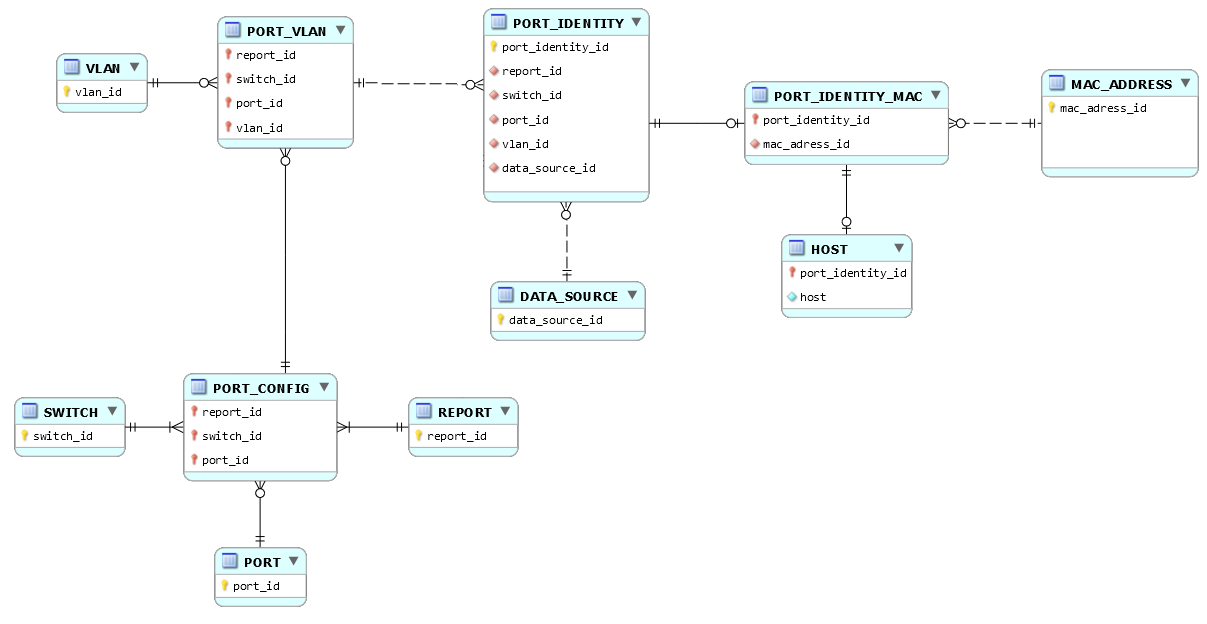
Un port_identity à adresse MAC est parfois associé à un host ; un host est associé à au moins et au plus un port_identiy à adresse _mac :
[ PORT_IDENTITY_MAC ]--0,1--------( rel_port_host ) -----1,1--[ HOST ]
Maintenant, au lieu de mettre en uvre une table HOST, vous pouvez conserver lattribut host dans la table PORT_IDENTITY_MAC, et éviter la présence de Null en utilisant plutôt une valeur de type varchar, mais de longueur égale à zéro.
Un scénario selon lequel on met en évidence une table HOST (même principe pour name et distant_port_id) :
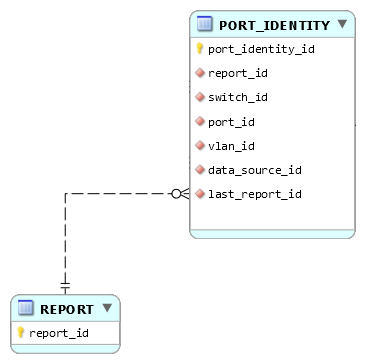
En ce qui concerne lattribut last_report_id, puisque le report ne dépend pas de ladresse MAC, il est à sa place dans PORT_IDENTITY :
Pour ma part, je tendrais donc vers quelque chose comme ceci :
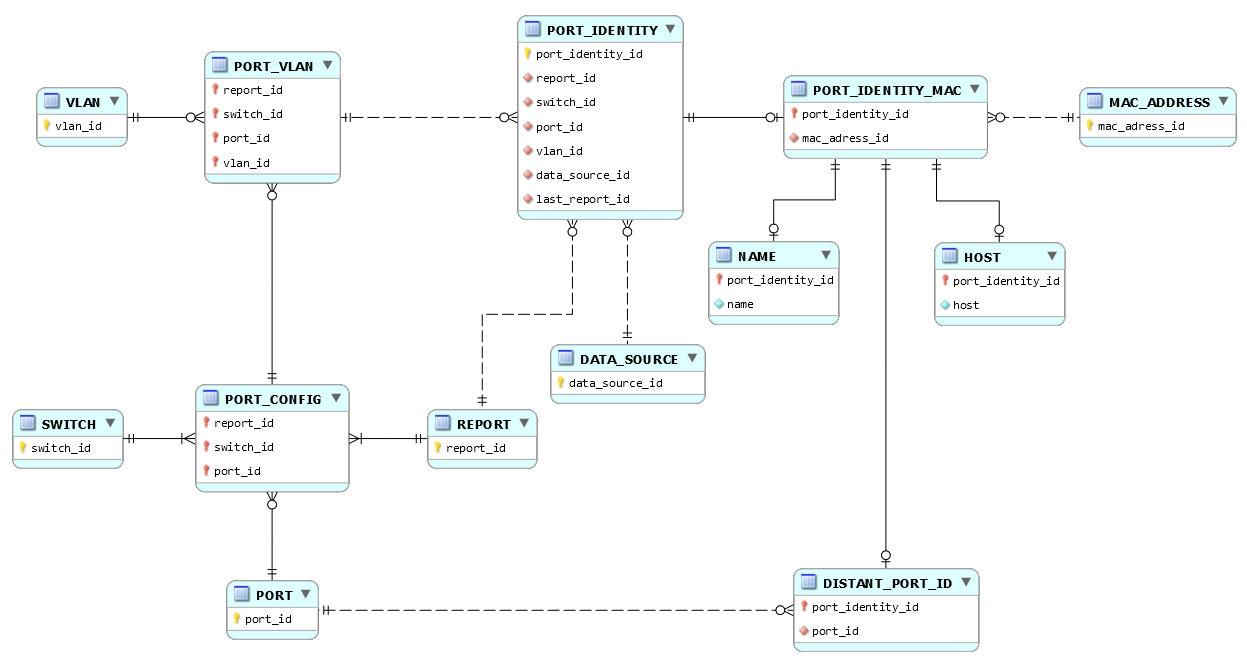
Reste le cas de fetch_date : attribut ou table, selon sa « nullabilité ».









 Répondre avec citation
Répondre avec citation
















Partager