Bonsoir JBdev,

Envoyé par
JBdev

la table proposition aura (niveau MPD) comme clé primaire {IdProp, IdCli,IdEnt}, IdProp nécessiterait l'extra AUTO_INCREMENT mais Mysql le refuse du fait de sa participation dans la composition de la clé primaire de la table.
Les différents SGBD permettent lutilisation dun auto-incrément, mais on nest pas obligé de sen servir : il y a quand même dautres façons de générer des valeurs uniques pour les clés. Quoi quil en soit, avant le milieu des années quatre-vingt-dix, chacun devait se débrouiller tout seul, comme un grand...
Prenons lexemple MySQL suivant, dans lequel il sagit didentifier les entreprises, tout en se passant de lauto-incrémentation offerte par ce SGBD. Le principe est de dire que la nouvelle clé primaire {EntrepriseId} est incrémentée dune unité par rapport à la dernière clé créée, ce qui passe par lutilisation de la fonction dagrégation MAX (où n représente le pas de lincrément) :
MAX(EntrepriseId) + n
Quand il sagit de créer la 1re clé, pour empêcher au bonhomme Null de se manifester, on utilise la fonction COALESCE (où m représente la valeur initiale de la clé :
COALESCE(MAX(EntrepriseId) + n, m)
Un script :
CREATE TABLE ENTREPRISE
(
EntrepriseId INT NOT NULL
, EntrepriseSiren CHAR(9) NOT NULL
, EntrepriseNom VARCHAR(64) NOT NULL
, CONSTRAINT ENTREPRISE_PK PRIMARY KEY (EntrepriseId)
, CONSTRAINT ENTREPRISE_AK UNIQUE (EntrepriseSiren)
) ;
INSERT INTO ENTREPRISE (EntrepriseId, EntrepriseSiren, EntrepriseNom)
SELECT COALESCE(MAX(EntrepriseId) + 1, 1), '123456789', 'Dugoineau'
FROM ENTREPRISE ;
INSERT INTO ENTREPRISE (EntrepriseId, EntrepriseSiren, EntrepriseNom)
SELECT COALESCE(MAX(EntrepriseId) + 1, 1), '234567890', 'Naudin et Cie'
FROM ENTREPRISE ;
EntrepriseId EntrepriseSiren EntrepriseNom
1 123456789 Dugoineau
2 234567890 Naudin et Cie
DELIMITER GO
CREATE TRIGGER IncrementonsEntreprise BEFORE INSERT ON ENTREPRISE
FOR EACH ROW
BEGIN
SET NEW.EntrepriseId = (SELECT COALESCE(MAX(EntrepriseId) + 5, 100)
FROM ENTREPRISE) ;
END
GO
DELIMITER ;
INSERT INTO ENTREPRISE (EntrepriseId, EntrepriseSiren, EntrepriseNom)
VALUES (0, '123456789', 'Dugoineau') ;
INSERT INTO ENTREPRISE (EntrepriseId, EntrepriseSiren, EntrepriseNom)
VALUES (0, '234567890', 'Naudin et Cie') ;
EntrepriseId EntrepriseSiren EntrepriseNom
100 123456789 Dugoineau
105 234567890 Naudin et Cie
Supposons quaux entreprises sont accrochés des établissements et quon utilise lidentification relative :
[ ENTREPRISE ]----1,N--------(Composer)--------1,1 (R)----[ ETABLISSEMENT ]
Table des établissements :
CREATE TABLE ETABLISSEMENT
(
EntrepriseId INT NOT NULL
, EtablissementId INT NOT NULL
, EtablissementSiret CHAR(14) NOT NULL
, EtablisssementNom VARCHAR(64) NOT NULL
, CONSTRAINT ETABLISSEMENT_PK PRIMARY KEY (EntrepriseId, EtablissementId)
, CONSTRAINT ETABLISSEMENT_AK UNIQUE (EtablissementSiret)
, CONSTRAINT ETABLISSEMENT_ENTREPRISE_FK FOREIGN KEY (EntrepriseId)
REFERENCES ENTREPRISE (EntrepriseId)
) ;
CREATE TRIGGER IncrementonsEtablissement BEFORE INSERT ON ETABLISSEMENT
FOR EACH ROW
BEGIN
SET NEW.EtablissementId = (SELECT COALESCE(MAX(EtablissementId) + 1, 1)
FROM ETABLISSEMENT
WHERE EntrepriseId = NEW.EntrepriseId) ;
END
GO
INSERT INTO ETABLISSEMENT (EntrepriseId, EtablissementId, EtablissementSiret, EtablisssementNom)
SELECT EntrepriseId
, 0
, '12345678912345', 'Clinique Dugoineau'
FROM ENTREPRISE
WHERE EntrepriseSiren = '123456789' ;
INSERT INTO ETABLISSEMENT (EntrepriseId, EtablissementId, EtablissementSiret, EtablisssementNom)
SELECT EntrepriseId
, 0
, '23456789012345', 'La péniche'
FROM ENTREPRISE
WHERE EntrepriseSiren = '234567890' ;
INSERT INTO ETABLISSEMENT (EntrepriseId, EtablissementId, EtablissementSiret, EtablisssementNom)
SELECT EntrepriseId
, 0
, '23456789012346', 'Le clapier'
FROM ENTREPRISE
WHERE EntrepriseSiren = '234567890' ;
INSERT INTO ETABLISSEMENT (EntrepriseId, EtablissementId, EtablissementSiret, EtablisssementNom)
SELECT EntrepriseId
, 0
, '23456789012347', 'Chez Mme Mado'
FROM ENTREPRISE
WHERE EntrepriseSiren = '234567890' ;
EntrepriseId EtablissementId EtablissementSiret EtablisssementNom
100 1 12345678912345 Clinique Dugoineau
105 1 23456789012345 La péniche
105 2 23456789012346 Le clapier
105 3 23456789012347 Chez Mme Mado
Envoyé par
JBdev
M'amenant pour le coup à la question de mon topic l'identification relative apporte-elle autant que cela? Ou est ce que ce sont les SGBD qui ne sont pas à la hauteur de cette notion?
Lidentification relative sert notamment à résoudre de façon simple les contraintes de chemin, c'est-à-dire en évitant les triggers (fouillez dans les forums, jen parle assez souvent). Dans la soute, la propagation de lidentifiant EntrepriseId chez les descendants des entreprises permet de faire de la « clusterisation » (veuillez me pardonner ce barbarisme, mais il est vraiment tentant...) et offre ainsi des possibilités de gains en performances fort intéressants.
Peu importe que le SGBD ne soit pas à la hauteur, on vient de voir que ça nest pas un problème.
Envoyé par
JBdev
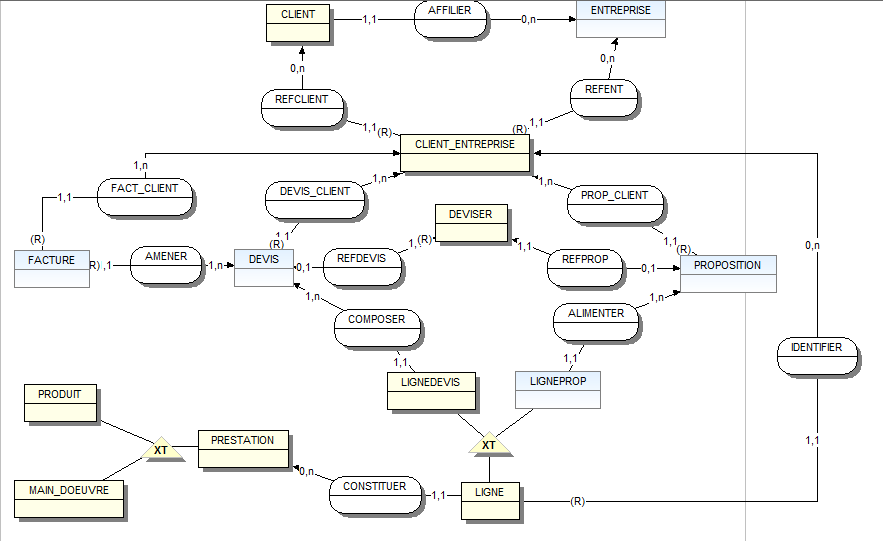
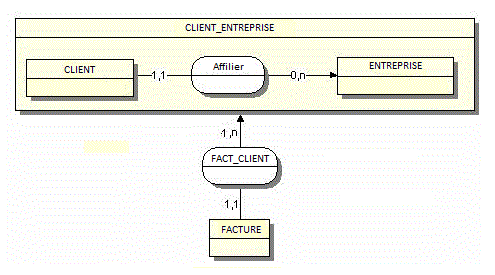
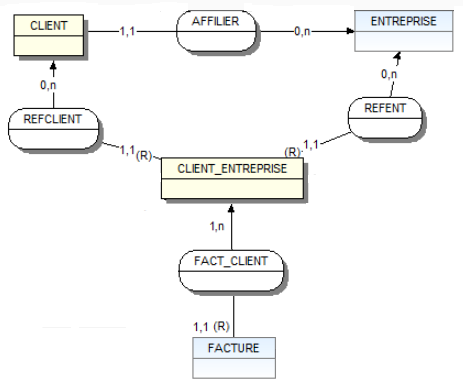
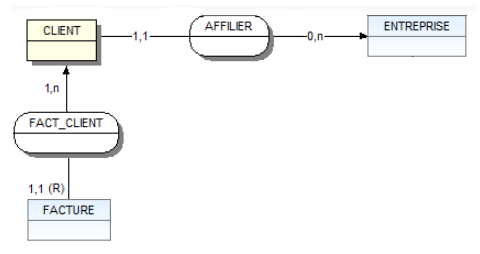
Chaque entreprise affilie un nombre n de client, chaque client est propre à l'entreprise ( agrégat selon WinDesign sur le MCD ci-dessous )
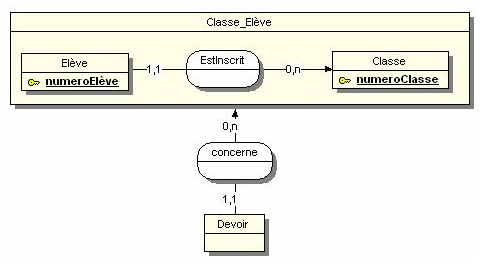
Daccord, je vois ce que vous entendez par agrégat, ça correspond au concept proposé en 1977 par John et Diane Smith dans Database abstractions: Aggregation and Generalization. Lagrégation a été évoquée dans quelques discussions, par exemple ici.
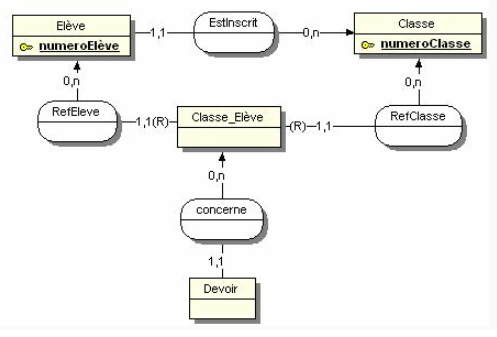
Votre modélisation de lagrégation correspond à celle qui est proposée dans la FAQ Merise. Mais lexemple proposé (en 2004) nest pas fameux et je ne reconnais pas la patte de Dominique Nanci (élégance du style, pertinence en ont pris un coup), quelquun a dû passer derrière lui pour bricoler le MCD, injecter des contre-vérités (un agrégat nest pas nécessairement vide). Je dis surtout que lexemple nest pas fameux (et devrait être remplacé !) parce que la cardinalité portée par la patte connectant lentité-type Elève et lassociation EstInscrit est 1,1 : en conséquence, lentité-type Classe_Elève nest quune restriction-projection de lentité-type Elève, ce que lon perçoit mieux en passant au stade logique :
Classe {ClasseId, ClasseNom}
PRIMARY KEY {ClasseId} ;
Elève {EleveId, ClasseId, EleveNom, ElevePrenom}
PRIMARY KEY {EleveId}
FOREIGN KEY {ClasseId} REFERENCES Classe ;
ClasseEleve {EleveId, ClasseId}
PRIMARY KEY {EleveId}
FOREIGN KEY {EleveId} REFERENCES Elève ;
FOREIGN KEY {ClasseId} REFERENCES Classe ;
Avez vous des règles de gestion des données non dites ici, justifiant un agrégat ? (Un vrai...)
A suivre...











")
 Répondre avec citation
Répondre avec citation







Partager