









Bonjour tout le monde,
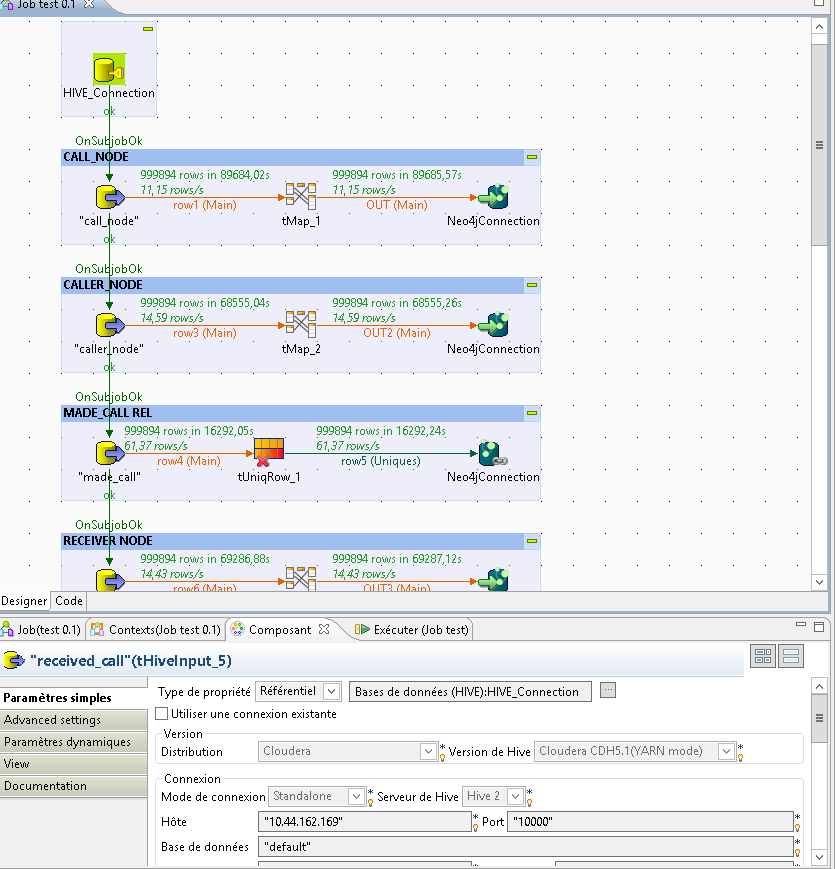
J'a créer un job sous Talend for Big Data pour charger des données d'une table hive contenant 1M de données vers une base nosql neo4j. Le temps d'éxécution est plutot trop lent, la vitesse est de 14.43 rows/s voire plus.
Je travaille avec une machine de 16Go de RAM.
J'ai regardé le fichier TOS_BD_win.ini et voila ce que j'ai trouvé:
-vmargs
-Xms512m
-Xmx1536m
-XX:MaxPermSize=512m
-Dfile.encoding=UTF-8
Quelqu'un peut m'aider et me dire comment je peux optimiser ce job ?
 Répondre avec citation
Répondre avec citation






Partager