ERROR: missing data for column "temp_id"
CONTEXT: COPY copydata, line 2: "1;Neu;Y:\SAS\A\Ahlsdorf\STG\_ATLAS\D_NEU\WIESENBU.LIB;4.582.829;5.746.965;;Ja;ENERCON;E-40/6.44-600;..."
Les données de STG_Ahlsdorf_table2.csv contiennent 68 colonnes et la table 70 donc je supprime les 2 dernières colonnes de la table:
1
2
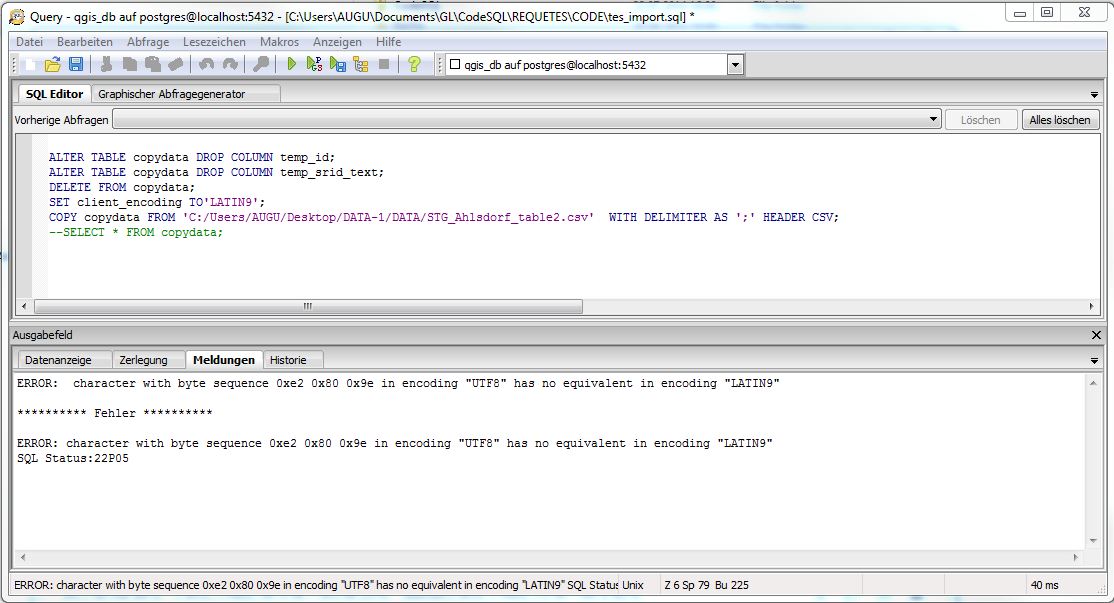
| alter table copydata drop column temp_id;
alter table copydata drop column temp_srid_text; |
Après ça j'importe le CSV sans erreur en tant qu'utilisateur postgres:
set client_encoding to 'LATIN9';
COPY copydata FROM '/tmp/STG_Ahlsdorf_table2.csv' WITH DELIMITER AS ';' HEADER CSV;
Résultat tjrs en client_encoding LATIN9 comme la séquence SQL montrée dans la question initiale
select * from copydata;
-[ RECORD 1 ]----------------+------------------------------------------------
temp_label | 1
temp_status | Neu
temp_access | Y:\SAS\A\Ahlsdorf\STG\_ATLAS\D_NEU\WIESENBU.LIB
temp_xtext | 4.582.829
temp_ytext | 5.746.965
temp_ztext |
temp_valid | Ja
temp_manufactor | ENERCON
temp_typegenerator | E-40/6.44-600
temp_powerrated | 600
temp_rotordiam | 44,0
temp_hubheight | 78,0
temp_description | ENERCON E-40/6.44 600 44.0 !O! Nabe: 78,0 m
temp_creator | USER
temp_powercurve | WT1871/01
temp_userlabel | WEA neu
temp_result | 1.031,8
temp_efficiency | 100,0
temp_regcorrec | 1,00
temp_eqroughness | 2,3
temp_meanwindspeed | 5,76
temp_hpvalue | 96
temp_calprod_wgs | 0,0
temp_actualwindcorrectenergy | 0,0
temp_goodnessfact |
temp_a(sum) | 6,50
temp_k(sum) | 2.256
temp_a(0) | 4,57
temp_k(0) | 2.443
temp_f(0) | 4,4
temp_a(1) | 5,14
temp_k(1) | 2.619
temp_f(1) | 3,6
temp_a(2) | 5,83
temp_k(2) | 2.584
temp_f(2) | 3,3
temp_a(3) | 6,72
temp_k(3) | 2.275
temp_f(3) | 6,8
temp_a(4) | 6,11
temp_k(4) | 2.467
temp_f(4) | 8,5
temp_a(5) | 5,35
temp_k(5) | 2.396
temp_f(5) | 5,4
temp_a(6) | 5,37
temp_k(6) | 2.299
temp_f(6) | 6,2
temp_a(7) | 6,82
temp_k(7) | 2.408
temp_f(7) | 13,7
temp_a(8) | 7,17
temp_k(8) | 2.533
temp_f(8) | 14,7
temp_a(9) | 8,08
temp_k(9) | 2.529
temp_f(9) | 15,6
temp_a(10) | 6,56
temp_k(10) | 2.408
temp_f(10) | 10,2
temp_a(11) | 5,19
temp_k(11) | 2.471
temp_f(11) | 7,5
temp_airdensity | 1.230
temp_displacement | 0,0
temp_projectnumber | 4250 05 03115 67
temp_date | 11,2005
temp_place | STG Ahlsdorf










 Répondre avec citation
Répondre avec citation














 [
[

Partager