
Envoyé par
Sennad

Ouais mais je ne vois pas trop comment je peux faire ça.
En "gros"
select * from hashes where url like "/chemin/vers/ton/dossier/%"
Une fois que t'as reçu le paquet en local (ce qui devrait être rapide), plus qu'à stocker ça dans une hashmap le temps de parcourir le dossier.
Aussi, si, encore une fois, le seul traitement différencié est de savoir si on a eu un ajout / une modification / un rien, on peut s'en sortir sans devoir pomper au préalable la base de données:
Si la base de données a une colonne "firstSeen" remplie en auto avec le timestamp courant.
Si elle a une colonne "lastUpdated" avec la date de dernière mise à jour
INSERT INTO Tatable(name,path,hash,firstseen) VALUES ('lenom','lepath','lehash',ladate) ON DUPLICATE KEY UPDATE lastUpdated = IF(hash<>'lehash',ladate,lastUpdated)
Que tu peux du coup faire rentrer dans un batch jdbc facilement pusique c'est la même requête pour tout le monde.
Un fois tout scanné, tu peux finalement créer ton fichier de log avec trois requetes simple:
les modifiés:
select * from Tatable where lastUpdate >= heureDeDebut and firstSeen < heureDeDebut
les nouveaux:
select * from Tatable where firstSeen >= heureDeDebut
les pas modifiés:
select * from Tatable where lastUpdate < heureDeDebut
En base de données, il faut éviter de mettre trop de logique du coté du code utilisateur et plutot du coté du serveur, c'est souvent plus performant ")
Aussi, si t'as 50 process qui attaquent la base en parallèle, tu risque d'avoir un sacré goulot d'étranglement sur les transactions entre ces process.











 Répondre avec citation
Répondre avec citation

















 New files => firstSeen = currentWeek
New files => firstSeen = currentWeek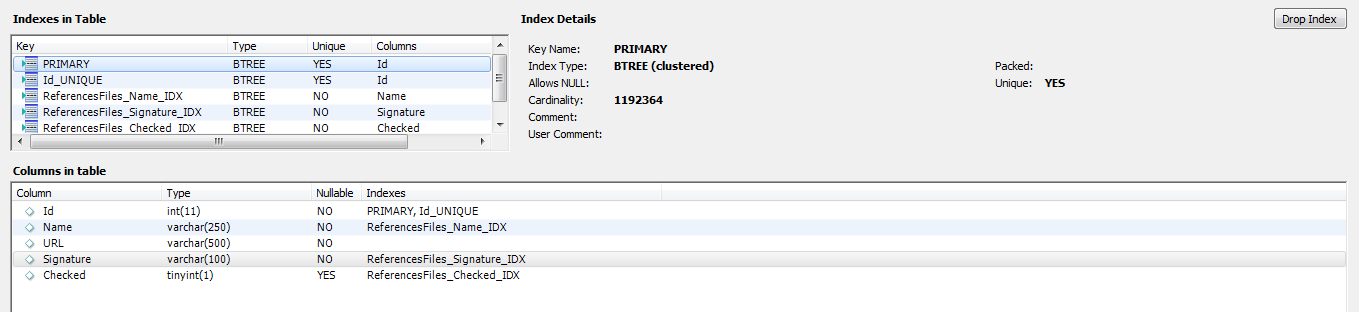

Partager