








Bonjour,
Je fais des programmes mathématiques sur des bignumbers devant effectuer des milliards de calculs. J'ai crus comprendre qu'il était possible d'utiliser la carte graphique en parallèle pour partager les calculs avec le CPU.
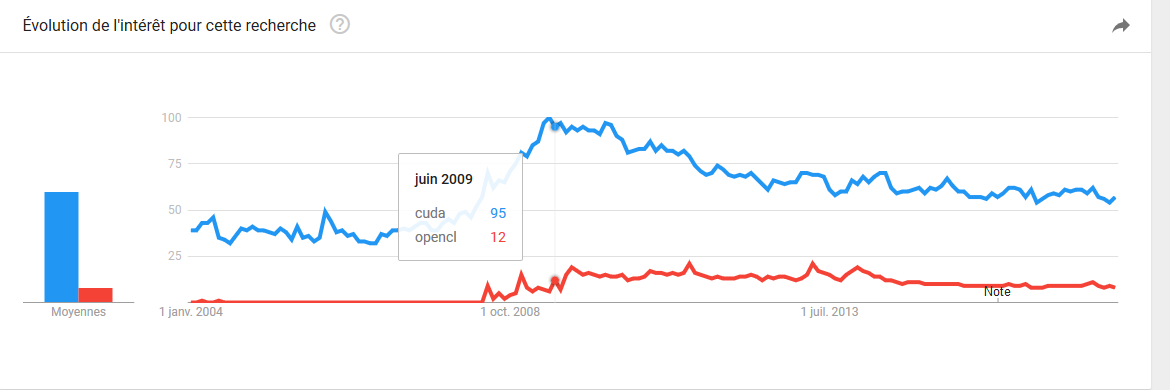
Est-ce que vous savez comment procéder, j'ai fais des recherches sur le net et j'ai lu quelques articles sur CUDA, mais il n'y a pas beaucoup d'infos ?
Merci.
 Répondre avec citation
Répondre avec citation



















Partager